
Unless you’ve been under a rock, you’ll know the tech industry has been rocked by the rapid advance in performance by large language models (LLMs) such as ChatGPT. By adapting self-supervised learning methods, LLMs “learn” to sound like a human being by learning how to fill in gaps in language and, by doing so, become remarkably adept at solving not just language problems but understanding & creativity.
Interestingly, the same is happening in imaging, as models largely trained to fill in “gaps” in images are becoming amazingly adept. A friend of mine, Pearse Keane’s group at University College of London, for instance, just published a model trained using self-supervised learning methods on ophthalmological images which is capable of not only diagnosing diabetic retinopathy and glaucoma relatively accurately, but relatively good at predicting cardiovascular events and Parkinson’s.
At a talk, Andrew Ng captured it well, by pointing out the parallels between the advances in language modeling that happened after the seminal Transformer paper and what is happening in the “large vision model” world with this great illustration.
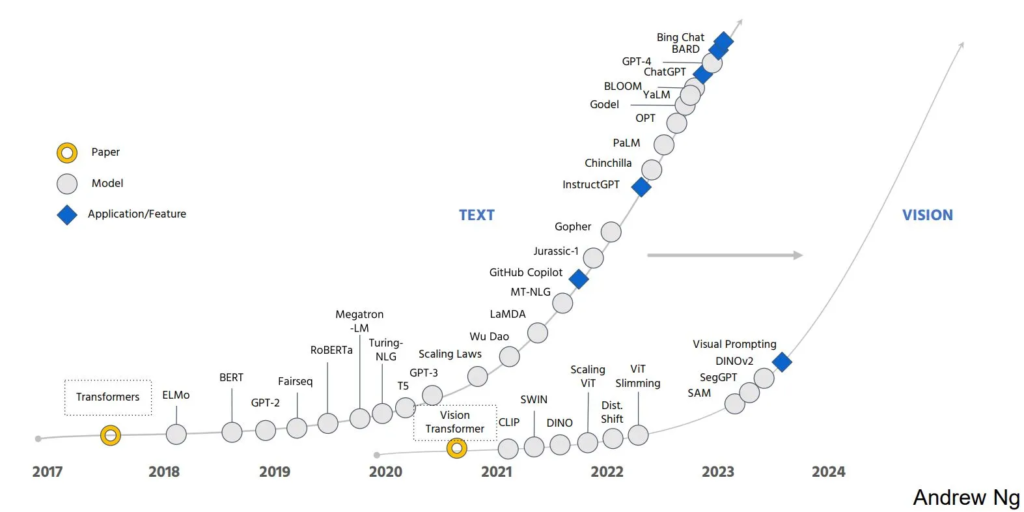
“The revolution we’ve seen for text will be coming to images,” renowned computer scientist Andrew Ng asserted in a keynote talk he gave at the recent AI Hardware Summit here.
Andrew Ng: The AI Text Revolution
Is Coming to Images
Sally Ward-Foxton | EETimes