
Summary
I built a metasearch engine that:
- Uses an LLM (OpenAI GPT3.5) to (1) interpret the search intent based on a user supplied topic and then (2) generate service-specific search queries to execute to get the best results
- Shows results from Reddit, Wikipedia, Unsplash, and Podcast episodes (search powered by Taddy)
- Surfaces relevant images from a set of crawled images using a vector database (Pinecone) populated with CLIP embeddings
- Was implemented in a serverless fashion using Modal.com
The result (using the basic/free tier of many of the connected services) is accessible here (Github repository). While functional, it became apparent during testing that this approach has major limitations, in particular the latency from chaining LLM responses and the dependence on search quality from the respective services. I conclude by discussing some potential future directions.
Motivation
Many articles have been written about the decline in Google’s search result quality and the popularity of attempts to fix this by pushing Google to give results from Reddit. This has even resulted in Google attempting to surface authoritative blog/forum-based results in its search results.
Large language models (LLMs) like OpenAI’s GPT have demonstrated remarkable versatility in handling language and “reasoning” problems. While at Stir, I explored the potential to utilize a large language model as a starting point for metasearch — one that would employ an LLM’s ability to interpret a user query and convert it to queries which would fulfill the user’s intent while also working well with other services (i.e., Reddit, image vector databases, etc.).
Serverless
To simplify administration, I employed a serverless implementation powered by Modal.com. Unlike many other serverless technology providers, Modal’s implementation is deeply integrated into Python, making it much easier to:
- Define the Python environment needed for an application
- Pass data between routines
- Create web endpoints
- Deploy and test locally
Define the Python environment needed for an application
Modal makes it extremely easy to set up a bespoke Python environment / container image through it’s Image API. For my application’s main driver, which required the installation of openai, requests, and beautifulsoup, this was achieved in 2 lines of code:
image = Image.debian_slim(python_version='3.10') \
.pip_install('openai', 'requests', 'beautifulsoup4')
stub = Stub('chain-search', image=image)Code language: JavaScript (javascript)Afterwards, functions that are to be run serverless-ly are wrapped in Modal’s Python function decorators (stub.function). These decorators take arguments which allow the developer to configure runtime behavior and pass secrets (like API keys) as environment variables. For example, the first few lines of a function that engages Reddit’s search API:
@stub.function(secret=Secret.from_name('reddit_secret'))
def search_reddit(query: str):
import requests
import base64
import os
reddit_id = os.environ['REDDIT_USER']
user_agent = os.environ['REDDIT_AGENT']
reddit_secret = os.environ['REDDIT_KEY']
...
return resultsCode language: Python (python)Modal also provides a means to intelligently prefetch data for an AI/ML-serving function. The Python class decorator stub.cls can wrap any arbitrary class that defines an initiation step method (__enter__ ) as well as actual function logic. In this way, a Modal container that is still warm that is being invoked an additional time need not re-initialize variables or fetch data, as it already did so during initiation.
Take for instance the following class which (1) loads the SentenceTransformer model stored at cache_path and initializes a connection to a remote Pinecone vector database during initiation and (2) defines a query function which takes a text string, runs it through self.model, and passes it through self.pinecone_index.query:
# use Modal's class entry trick to speed up initiation
@stub.cls(secret=Secret.from_name('pinecone_secret'))
class TextEmbeddingModel:
def __enter__(self):
import sentence_transformers
model = sentence_transformers.SentenceTransformer(cache_path,
device='cpu')
self.model = model
import pinecone
import os
pinecone.init(api_key=os.environ['PINECONE_API_KEY'],
environment=os.environ['PINECONE_ENVIRONMENT'])
self.pinecone_index = pinecone.Index(os.environ['PINECONE_INDEX'])
@method()
def query(self, query: str, num_matches = 10):
# embed the query
vector = self.model.encode(query)
# run the resulting vector through Pinecone
pinecone_results = self.pinecone_index.query(vector=vector.tolist(),
top_k=num_matches,
include_metadata=True
)
...
return results
Code language: Python (python)Transparently Pass data between routines
Once you’ve deployed a function to Modal, it becomes an invokable remote function. via Modal’s Function API. For example, the code below is from a completely different file from the TextEmbeddingModel class defined above.
pinecone_query = Function.lookup('text-pinecone-query',
'TextEmbeddingModel.query')Code language: Python (python)The remote function can then be called using Function.remote
return pinecone_query.remote(response[7:], 7)Code language: Python (python)The elegance of this is that the parameters (response[7:] and 7) and the result are passed transparently in Python without any need for a special API, allowing your Python code to call upon remote resources at a moment’s notice.
This ability to seamlessly work with remote functions also makes it possible to invoke the same function several times in parallel. The following code takes the queries generated by the LLM (responses — a list of 6-10 actions) and runs them in parallel (via parse_response) through Function.map which aggregates the results at the end. In a single line of code, as many as 10 separate workers could be acting in parallel (in otherwise completely synchronous Python code)!
responses = openai_chain_search.remote(query)
results = parse_response.map(responses)Code language: Python (python)Create Web Endpoints
To make a function accessible through a web endpoint, simply add a web_endpoint Python function decorator. This turns the functions into FastAPI endpoints, removing the need to embed a web server like Flask. This makes it easy to create API endpoints (that return JSON) as well as full web pages & applications (that return HTML and the appropriate HTTP headers).
from fastapi.responses import HTMLResponse
@stub.function()
@web_endpoint(label='metasearch')
def web_search(query: str = None):
html_string = "<html>"
...
return HTMLResponse(html_string)Code language: Python (python)Deploy and test locally
Finally, Modal has a simple command line interface that makes it extremely easy to deploy and test code. modal deploy <Python file> deploys the serverless functions / web endpoints in the file to the cloud, modal run <Python file> runs a specific function locally (while treating the rest of the code as remote functions), and modal serve <Python file> deploys the web endpoints to a private URL which automatically redeploys every every time the underlying Python file is changes (to better test a web endpoint).
To designate a particular function for local running via modal run simply involves using the stub.local_entrypoint function decorator. This (and modal serve) makes it much easier to test code prior to deployment.
# local entrypoint to test
@stub.local_entrypoint()
def main(query = 'Mountain sunset'):
results = []
seen_urls = []
seen_thumbnails = []
responses = openai_chain_search.remote(query)
for response in responses:
print(response)
...Code language: Python (python)Applying Large Language Model
Prompting Approach
The flexibility of large language models makes determining an optimal path for invoking them and processing their output complex and open-ended. My initial efforts focused around engineering a single prompt which would parse a user query and return queries for other services. However, this ran into two limitations. First, the various responses were structurally similar with one another even if the queries were wildly different. The LLM would supply queries for each API/platform service available even when some of the services were irrelevant. Secondly, the queries themselves were relatively generic. The LLM’s responses did not adapt very well to the individual services (i.e. providing more detail for a Podcast search that indexes podcast episode descriptions vs. something more generic for an image database or Wikipedia).
To boost the “dynamic range”, I turned to a chained approach where the initial LLM invocation would interpret whether or not a user query is best served with image-centric results or text-centric results. Depending on that answer, a follow-up prompt would be issued to the LLM requesting image-centric OR text-centric queries for the relevant services.
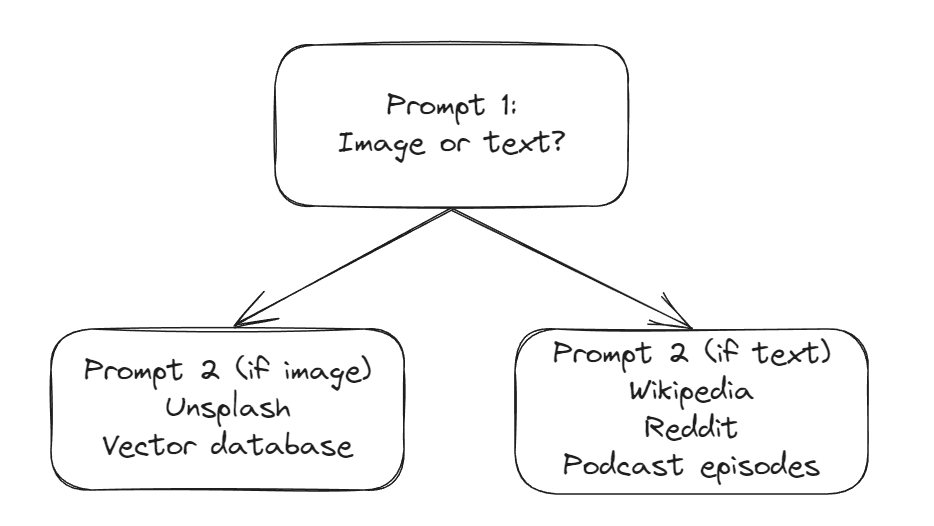
To design the system prompt (below), I applied the Persona pattern and supplied the LLM with example rationales for user query categorization as a preamble for the initial prompt.
<strong>*System Prompt*</strong>
Act as my assistant who's job is to help me understand and derive inspiration around a topic I give you. Your primary job is to help find the best images, content, and online resources for me. Assume I have entered a subject into a command line on a website and do not have the ability to provide you with follow-up context.
Your first step is to determine what sort of content and resources would be most valuable. For topics such as "wedding dresses" and "beautiful homes" and "brutalist architecture", I am likely to want more visual image content as these topics are design oriented and people tend to want images to understand or derive inspiration. For topics, such as "home repair" and "history of Scotland" and "how to start a business", I am likely to want more text and link content as these topics are task-oriented and people tend to want authoritative information or answers to questions.
<strong>*Initial Prompt*</strong>
I am interested in the topic:
{topic}
Am I more interested in visual content or text and link based content? Select the best answer between the available options, even if it is ambiguous. Start by stating the answer to the question plainly. Do not provide the links or resources. That will be addressed in a subsequent question.Code language: plaintext (plaintext)Reasonably good results were achieved when asking for queries one service at a time (i.e. “what queries should I use for Reddit” then “what queries should I use for Wikipedia”, etc.), but this significantly increased the time to response and cost. I ultimately settled on combining the follow-up requests, creating one to generate text-based queries and another to generate image-based ones. I also applied the Template Pattern to create a response which could be more easily parsed.
<strong>*Text-based query generation prompt*</strong>
You have access to three search engines.
The first will directly query Wikipedia. The second will surface interesting posts on Reddit based on keyword matching with the post title and text. The third will surface podcast episodes based on keyword matching.
Queries to Wikipedia should be fairly direct so as to maximize the likelihood that something relevant will be returned. Queries to the Reddit and podcast search engines should be specific and go beyond what is obvious and overly broad to surface the most interesting posts and podcasts.
What are 2 queries that will yield the most interesting Wikipedia posts, 3 queries that will yield the most valuable Reddit posts, and 3 queries surface that will yield the most insightful and valuable podcast episodes about:
{topic}
Provide the queries in a numbered list with quotations around the entire query and brackets around which search engine they're intended for (for example: 1. [Reddit] "Taylor Swift relationships". 2. [Podcast] "Impact of Taylor Swift on Music". 3. [Wikipedia] "Taylor Swift albums").
<strong>*Image query generation prompt*</strong>
You have access to two search engines.
The first a set of high quality images mapped to a vector database. There are only about 30,000 images in the dataset so it is unlikely that it can return highly specific image results so it would be better to use more generic queries and explore a broader range of relevant images.
The second will directly query the free stock photo site Unsplash. There will be a good breadth of photos but the key will be trying to find the highest quality images.
What are 3 great queries to use that will provide good visual inspiration and be different enough from one another so as to provide a broad range of relevant images from the vector database and 3 great queries to use with Unsplash to get the highest quality images on the topic of:
{topic}
Provide the queries in a numbered list with quotations around the entire query and brackets around which search engine they\'re intended for (for example: 1. [Vector] "Mountain sunset". 2. [Unsplash] "High quality capture of mountain top at sunset".)Code language: plaintext (plaintext)invoking openai and parsing the llm’s responses
I chose OpenAI due to the maturity of their offering and their ability to handle the prompting patterns I used. To integrate OpenAI, I created a Modal function, passing my OpenAI credentials as environment variables. I then created a list of messages to capture the back and forth exchanges with the LLM to pass back to the GPT model as history.
@stub.function(secret=Secret.from_name('openai_secret'))
def openai_chain_search(query: str):
import openai
import os
import re
model = 'gpt-3.5-turbo' # using GPT 3.5 turbo model
# Pull Open AI secrets
openai.organization = os.environ['OPENAI_ORG_ID']
openai.api_key = os.environ['OPENAI_API_KEY']
# message templates with (some) prompt engineering
system_message = """Act as my assistant who's job ... """
initial_prompt_template = 'I am interested in the topic:\n{topic} ...'
text_template = 'You have access to three search engines ...'
image_template = 'You have access to two search engines ...'
# create context to send to OpenAI
messages = []
messages.append({
'role': 'user',
'content': system_message
})
messages.append({
'role': 'user',
'content': initial_prompt_template.format(topic=query)
})
# get initial response
response = openai.ChatCompletion.create(
model=model,
messages = messages,
temperature = 1.0
)
messages.append({
'role': 'assistant',
'content': response['choices'][0]['message']['content']
})Code language: Python (python)To parse the initial prompt’s response, I did a simple text match with the string "text and link". While crude, this worked well in my tests. If the LLM concluded the user query would benefit more from a text-based set of responses, the followup text-centric prompt text_template was sent to the LLM. If the LLM concluded the user query would benefit more from images, the follow-up image-centric prompt image_template was sent to the LLM instead.
if 'text and link' in response['choices'][0]['message']['content']:
# get good wikipedia, reddit, and podcast queries
messages.append({
'role': 'user',
'content': text_template.format(topic=query)
})
else:
...
# get good image search queries
messages.append({
'role': 'user',
'content': image_template.format(topic=query)
})
# make followup call to OpenAI
response = openai.ChatCompletion.create(
model=model,
messages = messages,
temperature = 1.0
)Code language: Python (python)The Template pattern in these prompts pushes the LLM to return numbered lists with relevant services in brackets. These results were parsed with a simple regular expression and then converted into a list of strings (responses, with each entry in the form "<name of service>: <query>") which would later be mapped to specific service functions. (Not shown in the code below: I also added a Wikipedia query to the image-centric results to improve the utility of the image results).
responses = [] # aggregate list of actions to take
...
# use regex to parse GPT's recommended queries
for engine, query in re.findall(r'[0-9]+. \[(\w+)\] "(.*)"',
response['choices'][0]['message']['content']):
responses.append(engine + ': ' + query)
return responsesCode language: Python (python)Building and Querying Image Database
Update – Apr 2024: Sadly, due to Pinecone aggressively pushing it’s paid plan on me and not providing a way to export vectors / convert a paid vectorstore to a starter/free one, I have lost my Pinecone database and have had to disable the vector search. The service will continue to run on Unsplash and to support the text modalities but it will no longer query the image vector store hosted there.
Crawling
To supplement the image results from Unsplash, I crawled a popular high-quality image sharing platform for high quality images we could surface as image search results. To do this, I used the browser automation library Playwright. Used for website and webapp testing automation, it provided very simple APIs to use code to interact with DOM elements on the browser screen. This allowed me to login to the image sharing service.
While I initially used a combination of Playwright (to scroll and then wait for all the images to load) and the HTML/XML reading Python library BeautifulSoup (to parse the DOM) to gather the images from the service, this approach was slow and unreliable. Seeking greater performance, I looked at the calls the browser made to the service’s backend, and discovered the service would pass all the data the browser would need to render the image results on a page in a JSON blob.
Leveraging Playwright’s Page.expect_request_finished, Request, and Response APIs, I was able to directly access the JSON and programmatically extracted the data I needed directly (without needing to check what was being rendered in the browser window). This allowed me to quickly and reliably pull the images from the service and their associated metadata.
approach
To make it possible to search the images, I needed to find a way to capture the “meaning” of the images as well as the “meaning” of a text query so that they could be easily mapped together. OpenAI published research on a neural network architecture called CLIP which made this relatively straightforward to do. Trained on images paired with image captions on the web, CLIP makes it simple to convert both images and text into vectors (a series of numbers) where the better a match the image and text are, the closer their vectors “multiply” (dot product) to 1.0.
Procedurally then, if you have the vectors for every image you want to search against, and are given a text-based search query, to find the images that best match you need only to:
- Convert the query text into a vector using CLIP
- Find the image vectors that get the closest to
1.0when “multiplied/dot product-ed” with the search string vector - Return the images corresponding to those vectors
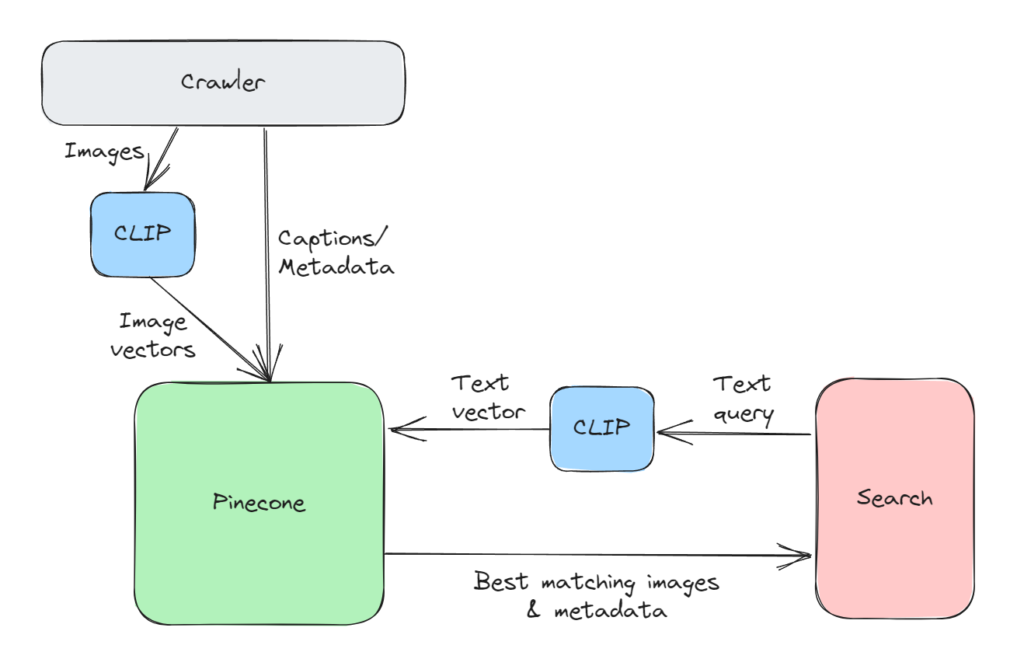
This type of search has been made much easier with vector databases like Pinecone which make it easy for applications to store vector information and query it with a simple API call. The diagram below shows how the architecture works: (1) the crawler running periodically and pushing new metadata & image vectors into the vector database and (2) whenever a user initiates a search, the search query is converted to a vector which is then passed to Pinecone to return the metadata and URLs corresponding to the best matching images.
Because of the size of the various CLIP models in use, in a serverless setup, it’s a good idea to intelligently cache and prefetch the model so as to reduce search latency. To do this in Modal, I defined a helper function (i.e. download_models, see below) which initiates and downloads the CLIP model from the SentenceTransformer package and then caches it (with modal.save). This helper function is then passed as part of the Modal container image creation flow with Image.run_function so that it’s called whenever the container image is initiated.
# define Image for embedding text queries and hitting Pinecone
# use Modal initiation trick to preload model weights
cache_path = '/pycache/clip-ViT-B-32' # cache for CLIP model
def download_models():
import sentence_transformers
model_id = 'sentence-transformers/clip-ViT-B-32' # model ID for CLIP
model = sentence_transformers.SentenceTransformer(
model_id,
device='cpu'
)
model.save(path=cache_path)
image = (
Image.debian_slim(python_version='3.10')
.pip_install('sentence_transformers')
.run_function(download_models)
.pip_install('pinecone-client')
)
stub = Stub('text-pinecone-query', image=image)Code language: Python (python)The stub.cls class decorator I shared before then loads the CLIP model from cache (self.model) if the container image is called again “while warm” (before it shuts down). It also initiates a connection to the appropriate Pinecone database in self.pinecone_index. Note: the code below was shared above in my discussion of intelligent prefetch in Modal
# use Modal's class entry trick to speed up initiation
@stub.cls(secret=Secret.from_name('pinecone_secret'))
class TextEmbeddingModel:
def __enter__(self):
import sentence_transformers
model = sentence_transformers.SentenceTransformer(cache_path,
device='cpu')
self.model = model
import pinecone
import os
pinecone.init(api_key=os.environ['PINECONE_API_KEY'],
environment=os.environ['PINECONE_ENVIRONMENT'])
self.pinecone_index = pinecone.Index(os.environ['PINECONE_INDEX'])Code language: Python (python)Invoking the CLIP model is done via model.encode (which also works on image data), and querying Pinecone involves passing the vector and number of matches desired to pinecone_index.query. Note: the code below was shared above in my discussion of intelligent prefetch in Modal
@stub.cls(secret=Secret.from_name('pinecone_secret'))
class TextEmbeddingModel:
def __enter__(self):
...
@method()
def query(self, query: str, num_matches = 10):
# embed the query
vector = self.model.encode(query)
# run the resulting vector through Pinecone
pinecone_results = self.pinecone_index.query(vector=vector.tolist(),
top_k=num_matches,
include_metadata=True
)
...
return results
Code language: Python (python)Assembling the Results
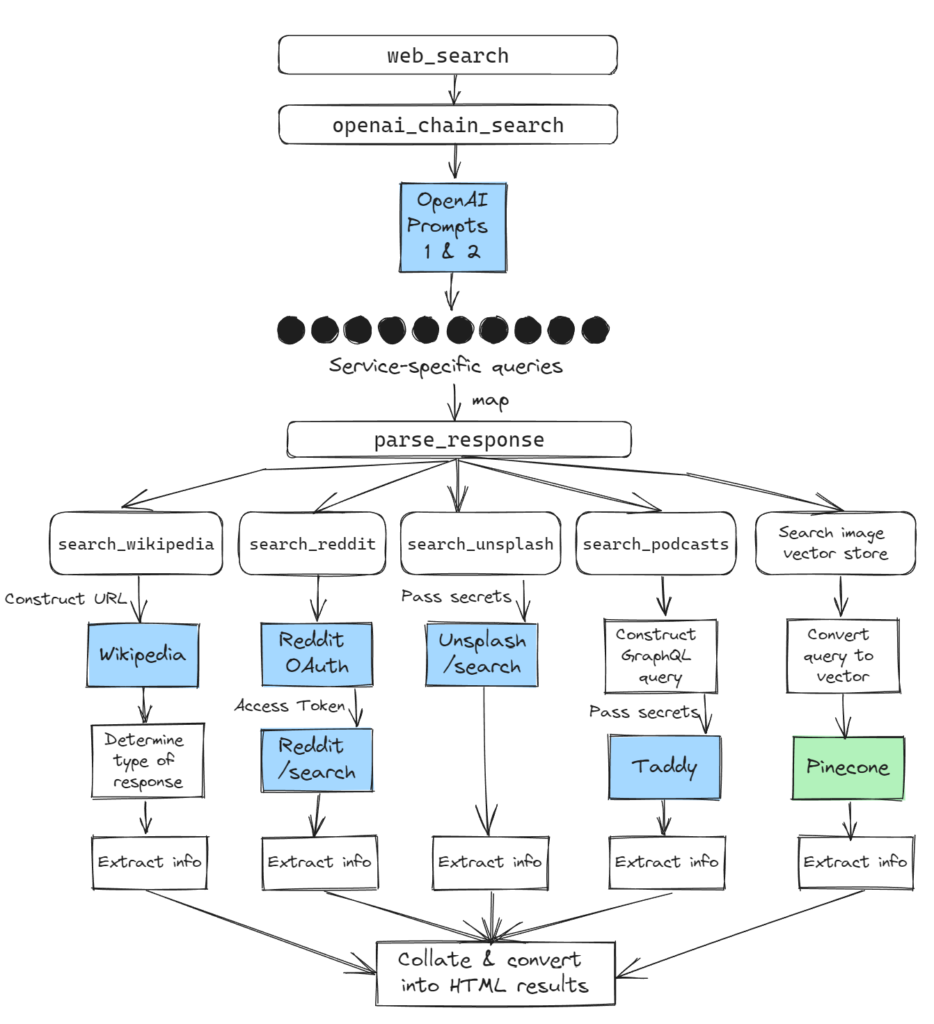
initiating the service workers
When the web endpoint receives a search query, it invokes openai_chain_search. This would, as mentioned previously, have the LLM (1) interpret the user query as image or text-centric and then (2) return parsed service-specific queries.
responses = openai_chain_search.remote(query)Code language: Python (python)The resulting responses are handled by parse_response, a function which identifies the service and triggers the appropriate service-specific function (to handle service-specific quirks). Those functions would return a Python dictionary with a consistent set of keys that would be used to construct the search results (e.g. query, source, subsource, subsource_url, url, title, thumbnail, and snippet)
# function to map against response list
@stub.function()
def parse_response(response: str):
pinecone_query = Function.lookup('text-pinecone-query', 'TextEmbeddingModel.query')
if response[0:11] == 'Wikipedia: ':
return search_wikipedia.remote(response[11:])
elif response[0:8] == 'Reddit: ':
return search_reddit.remote(response[8:])
elif response[0:9] == 'Podcast: ':
return search_podcasts.remote(response[9:])
elif response[0:10] == 'Unsplash: ':
return search_unsplash.remote(response[10:])
elif response[0:8] == 'Vector: ':
return pinecone_query.remote(response[7:], 7) Code language: Python (python)Because Modal functions like parse_response can be invoked remotely, to speed up the overall response time, each call to parse_response was made in parallel rather than sequentially using Modal’s Function.map API.
results = parse_response.map(responses)Code language: Python (python)The results are then collated and rendered into HTML to be returned to the requesting browser.
Calling The Services
As mentioned above, the nuances of each service was handled by a dedicated service function. These functions would handle service authentication, would execute the relevant search, and parse the response into a Python dictionary with the appropriate structure.
Searching Wikipedia (search_wikipedia) involved url-encoding the query and adding it to a base URL (http://www.wikipedia.org/search-redirect.php?search=) that effectively surfaces Wikipedia pages if the query has a good match and conducts keyword searches on Wikipedia if not. (I use that URL as a keyword short cut in my browsers for this purpose)
Because of the different types of page responses, the resulting page needed to be parsed to determine if the result was a full Wikipedia entry, a Search results page (in which case the top two results were taken), or a disambiguation page (a query that could point to multiple possible pages but which had a different template than the others) before extracting the information needed for presenting the results.
# handle Wikipedia
@stub.function()
def search_wikipedia(query: str):
import requests
import urllib.parse
from bs4 import BeautifulSoup
# base_search_url works well if search string is spot-on, else does search
base_search_url = 'https://en.wikipedia.org/w/index.php?title=Special:Search&search={query}'
base_url = 'https://en.wikipedia.org'
results = []
r = requests.get(base_search_url.format(query = urllib.parse.quote(query)))
soup = BeautifulSoup(r.content, 'html.parser') # parse results
if '/wiki/Special:Search' in r.url: # its a search, get top two results
search_results = soup.find_all('li', class_='mw-search-result')
for search_result in search_results[0:2]:
...
results.append(result)
else: # not a search page, check if disambiguation or legit page
...
return resultsCode language: Python (python)The Reddit API is only accessible via OAuth. This requires an initial authentication token generation step. This generated token can then authenticate subsequent API requests for information. The endpoint of interest (/search) returns a large JSON object encapsulating all the returned results. Trial-and-error helped establish the schema and the rules of thumb needed for extracting the best preview images. Note: the Reddit access token was re-generated for each search because the expiry on each was only one hour
# handle Reddit
@stub.function(secret=Secret.from_name('reddit_secret'))
def search_reddit(query: str):
import requests
import base64
import os
reddit_id = os.environ['REDDIT_USER']
user_agent = os.environ['REDDIT_AGENT']
reddit_secret = os.environ['REDDIT_KEY']
# set up for auth token request
auth_string = reddit_id + ':' + reddit_secret
encoded_auth_string = base64.b64encode(auth_string.encode('ascii')).decode('ascii')
auth_headers = {
'Authorization': 'Basic ' + encoded_auth_string,
'User-agent': user_agent
}
auth_data = {
'grant_type': 'client_credentials'
}
# get auth token
r = requests.post('https://www.reddit.com/api/v1/access_token', headers = auth_headers, data = auth_data)
if r.status_code == 200:
if 'access_token' in r.json():
reddit_access_token = r.json()['access_token']
else:
return [{'error':'auth token failure'}]
results = []
# set up headers for search requests
headers = {
'Authorization': 'Bearer ' + reddit_access_token,
'User-agent': user_agent
}
# execute subreddit search
params = {
'sort': 'relevance',
't': 'year',
'limit': 4,
'q': query[:512]
}
r = requests.get('https://oauth.reddit.com/search', params=params, headers=headers)
if r.status_code == 200:
body = r.json()
...
return resultsCode language: Python (python)Authenticating Unsplash searches was simpler and required passing a client ID as a request header. The results could then be obtained by simply passing the query parameters to https://api.unsplash.com/search/photos
# handle Unsplash Search
@stub.function(secret = Secret.from_name('unsplash_secret'))
def search_unsplash(query: str, num_matches: int = 5):
import os
import requests
# set up and make request
unsplash_client = os.environ['UNSPLASH_ACCESS']
unsplash_url = 'https://api.unsplash.com/search/photos'
headers = {
'Authorization': 'Client-ID ' + unsplash_client,
'Accept-Version': 'v1'
}
params = {
'page': 1,
'per_page': num_matches,
'query': query
}
r = requests.get(unsplash_url, params=params, headers=headers)
# check if request is good
if r.status_code == 200:
...
return results
else:
return [{'error':'auth failure'}]Code language: Python (python)To search podcast episodes, I turned to Taddy’s API. Unlike Reddit and Unsplash, Taddy operates a GraphQL-based query engine where, instead of requesting specific data for specific fields at specific endpoints (i.e. GET api.com/podcastTitle/, GET api.com/podcastDescription/), you request all the data from an endpoint at once by passing the fields of interest (i.e. GET api.com/podcastData/).
As I did not want the overhead of creating a schema and running a Python GraphQL library, I constructed the request manually.
# handle Podcast Search via Taddy
@stub.function(secret = Secret.from_name('taddy_secret'))
def search_podcasts(query: str):
import os
import requests
# prepare headers for querying taddy
taddy_user_id = os.environ['TADDY_USER']
taddy_secret = os.environ['TADDY_KEY']
url = 'https://api.taddy.org'
headers = {
'Content-Type': 'application/json',
'X-USER-ID': taddy_user_id,
'X-API-KEY': taddy_secret
}
# query body for podcast search
queryString = """{
searchForTerm(
term: """
queryString += '"' + query + '"\n'
queryString += """
filterForTypes: PODCASTEPISODE
searchResultsBoostType: BOOST_POPULARITY_A_LOT
limitPerPage: 3
) {
searchId
podcastEpisodes {
uuid
name
subtitle
websiteUrl
audioUrl
imageUrl
description
podcastSeries {
uuid
name
imageUrl
websiteUrl
}
}
}
}
"""
# make the graphQL request and parse the JSON body
r = requests.post(url, headers=headers, json={'query': queryString})
if r.status_code != 200:
return []
else:
responseBody = r.json()
if 'errors' in responseBody:
return [{'error': 'authentication issue with Taddy'}]
else:
results = []
...
return resultsCode language: Python (python)Serving Results
To keep the architecture and front-end work simple, the entire application is served out of a single endpoint. Queries are passed as simple URL parameters (?query=) which are both easy to handle with FastAPI but are readily generated using HTML <form> elements with method='get' as an attribute and name='query' on the text field.
The interface is fairly simple: a search bar at the top and search results (if any) beneath (see below)
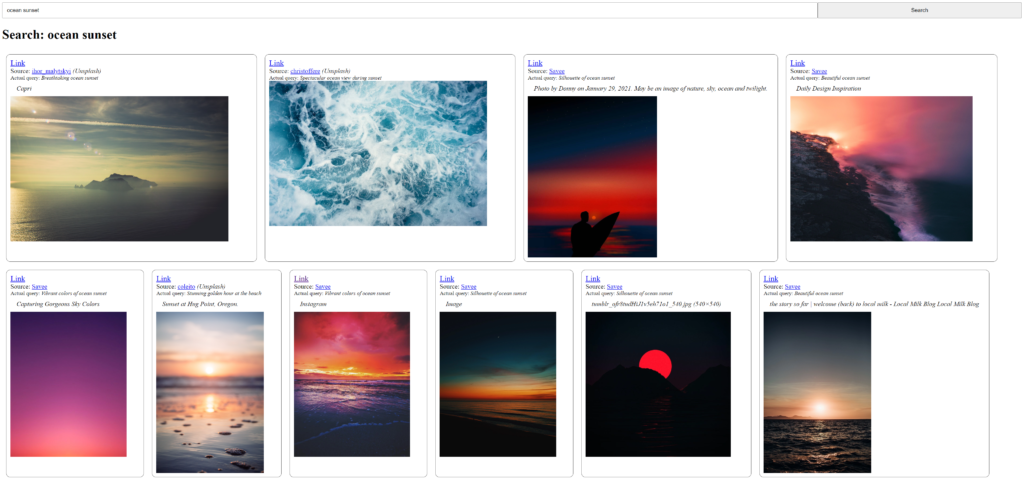
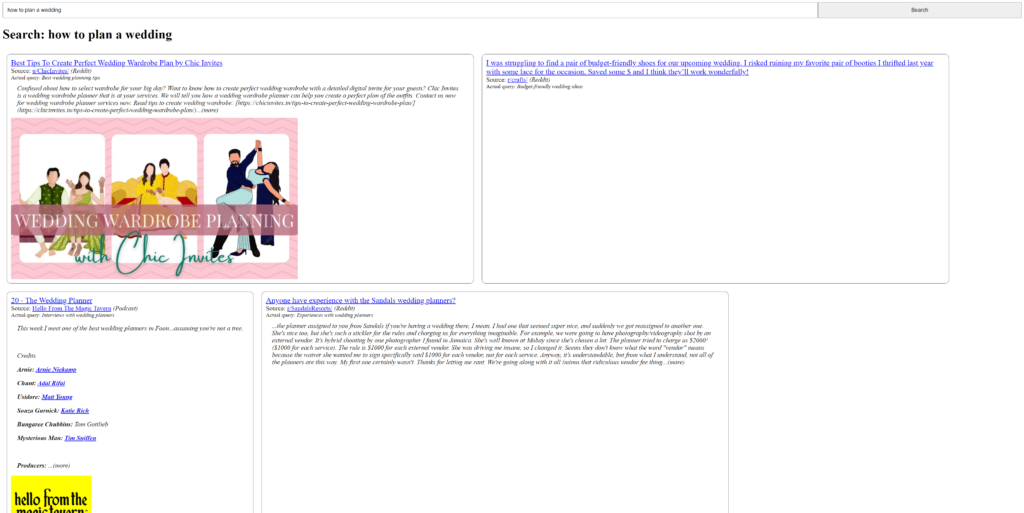
To get a more flexible layout, each search result (rowchild) is added to a flexbox container (row) configured to “fill up” each horizontal row before proceeding. The search results themselves are also given minimum widths and maximum widths to guarantee at least 2 items per row. To prevent individual results from becoming too tall, maximum heights are applied to image containers (imagecontainer) inside the search results.
<style type='text/css'>
.row {
display: flex;
flex-flow: row wrap
}
.rowchild {
border: 1px solid #555555;
border-radius: 10px;
padding: 10px;
max-width: 45%;
min-width: 300px;
margin: 10px;
}
...
.imagecontainer {max-width: 90%; max-height: 400px;}
....
</style>Code language: CSS (css)Limitations & Future Directions
Limitations
While this resulted in a functioning metasearch engine, a number of limitations became obvious as I built and tested it.
- Latency — Because LLM’s have significant latency, start-to-finish search times will take a meaningful hit, even excluding the time needed to query the additional services. Given the tremendous body of research showing how search latency decreases usage and clickthrough, this poses a significant barrier for this approach to work. At the minimum, the search user interface needs to accommodate for this latency.
- Result Robustness [LLM] — Because large language models sample over a distribution, the same prompt will result in different responses over time. As a result, this approach will result in large variance in results even with the same user query. While this can help with ideation and exploration for general queries, it is a limiting factor if the expectation is to produce the best results time and time again for specific queries.
- Dependence on Third Party Search Quality — Even with perfectly tailored queries, metasearch ultimately relies on third party search engines to perform well. Unfortunately, as evidenced in multiple tests, all of the services used here regularly produce irrelevant results. This is likely due to the computational difficulty of going beyond the simple text matching and categorization that is likely used.
future areas for exporation
To improve the existing metasearch engine, there are four areas of exploration that are likely to be the most promising:
- Caching search results: Given latency inherent to LLMs and metasearch services, caching high quality and frequently searched-for results could drive a significant impact on performance.
- Asynchronous searches & load states: While the current engine executes individual sub-queries in parallel, the results are delivered monolithically (in one go). There may be perception and performance gains to be derived by serving results as they come with loading state animations to provide visual feedback to the user as to what is happening. This will be especially necessary if the best results are to be a combination of cached and newly pulled results.
- Building scoring engine for search results: One of the big weaknesses of the current engine is that it treats all results equally. Results should be ranked on relevancy or value and should also be pruned of irrelevant content. This can only be done if a scoring engine or model is applied.
- Train own models for query optimization: Instead of relying on high-latency LLM requests, it may be possible for some services to generate high quality service-specific queries with smaller sequence to sequence models. This would result in lower latency and possibly better performance due to the focus on the particular task.
Update – Sep 2024: Updated Wikipedia address due to recent changes; replaced .call with .remote due to Modal deprecation of .call
Update – Apr 2024: Sadly, due to Pinecone aggressively pushing it’s paid plan on me and not providing a way to export vectors or convert a paid vectorstore to a starter/free one, I have lost my Pinecone database and have had to disable the vector search. The service will continue to run on Unsplash and to support the text modalities but it will no longer query the image vector store hosted there or risk paying exorbitant fees for a hobby project.