While Large Language Models (LLMs) have demonstrated they can do many things well enough, it’s important to remember that these are not “thinking machines” so much as impressively competent “writing machines” (able to figure out what words are likely to follow).
Case in point: both OpenAI’s ChatGPT and Microsoft Copilot lost to the chess playing engine of an old Atari game (Video Chess) which takes up a mere 4 KB of memory to work (compared with the billions of parameters and GB’s of specialized accelerator memory needed to make LLMs work).
It’s a small (yet potent) reminder that (1) different kinds of AI are necessary for different tasks (i.e. Google’s revolutionary AlphaZero probably would’ve made short work of the Atari engine) and (2) don’t underestimate how small but highly specialized algorithms can perform.
Last month we reported on the somewhat-surprising news that an emulated Atari 2600 running the 1979 software Video Chess had “absolutely wrecked” an overconfident ChatGPT at the game of kings. Fans of schadenfreude rejoice, because Microsoft Copilot thought this was a chance to show its superiority to ChatGPT: And the Atari gave it a beating.
Thankfully, Keras 3 lived up to it’s multi-backend promise and made switching to JAX remarkably easy. For my code, I simply had to make three sets of tweaks.
First, I had to change the definition of my container images. Instead of starting from Tensorflow’s official Docker images, I instead installed JAX and Keras on Modal’s default Debian image and set the appropriate environmental variables to configure Keras to use JAX as a backend:
jax_image = (
modal.Image.debian_slim(python_version='3.11')
.pip_install('jax[cuda12]==0.4.35', extra_options="-U")
.pip_install('keras==3.6')
.pip_install('keras-hub==0.17')
.env({"KERAS_BACKEND":"jax"}) # sets Keras backend to JAX .env({"XLA_PYTHON_CLIENT_MEM_FRACTION":"1.0"})
Code language:Python(python)
Second, because tf.data pipelines convert everything to Tensorflow tensors, I had to switch my preprocessing pipelines from using Keras’s ops library (which, because I was using JAX as a backend, expected JAX tensors) to Tensorflow native operations:
Lastly, I had a few lines of code which assumed Tensorflow tensors (where getting the underlying value required a .numpy() call). As I was now using JAX as a backend, I had to remove the .numpy() calls for the code to work.
Everything else — the rest of the tf.data preprocessing pipeline, the code to train the model, the code to serve it, the previously saved model weights and the code to save & load them — remained the same! Considering that the training time per epoch and the time the model took to evaluate (a measure of inference time) both seemed to improve by 20-40%, this simple switch to JAX seemed well worth it!
Model Architecture Improvements
There were two major improvements I made in the model architecture over the past few months.
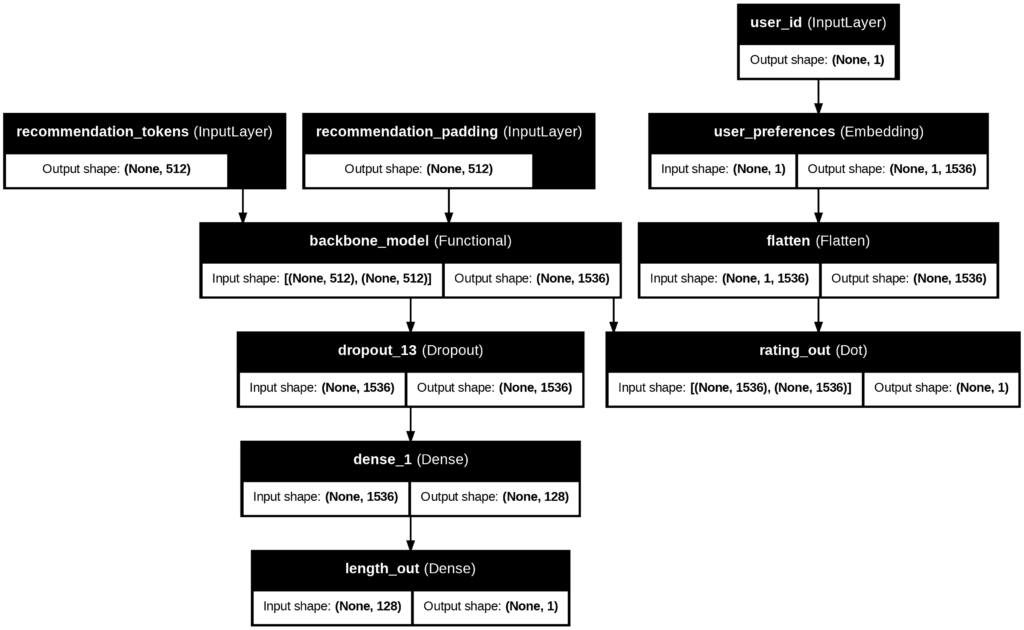
First, having run my news reader for the better part of a year now, I now have accumulated enough data where my strategy to simultaneously train on two related tasks (predicting the human rating and predicting the length of an article) no longer required separate inputs. This reduced the memory requirement as well as simplified the data pipeline for training (see architecture diagram below)
Secondly, I was successfully able to train a version of my algorithm which can use dot products natively. This not only allowed me to remove several layers from my previous model architecture (see architecture diagram below), but because the Supabase postgres database I’m using supports pgvector, it means I can even compute ratings for articles through a SQL query:
UPDATE articleuser
SET ai_rating = 0.5 + 0.5 * (1 - (a.embedding <=> u.embedding)),
rating_timestamp = NOW(),
updated_at = NOW()
FROM articles a,
users u
WHERE articleuser.article_id = a.id
AND articleuser.user_id = u.id
AND articleuser.ai_rating ISNULL;
Code language:SQL (Structured Query Language)(sql)
The result is much greater simplicity in architecture as well as greater operational flexibility as I can now update ratings from the database directly as well as from serving a deep neural network from my serverless backend.
Model architecture (output from Keras plot_model function)
Making Sources a First-Class Citizen
As I used the news reader, I realized early on that the ability to just have sorted content from one source (i.e. a particular blog or news site) would be valuable to have. To add this, I created and populated a new sources table within the database to track these independently (see database design diagram below) which was linked to the articles table.
Newsreader database design diagram (produced by a Supabase tool)
I then modified my scrapers to insert the identifier for each source alongside each new article, as well as made sure my fetch calls all JOIN‘d and pulled the relevant source information.
With the data infrastructure in place, I added the ability to add a source parameter to the core fetch URLs to enable single (or multiple) source feeds. I then added a quick element at the top of the feed interface (see below) to let a user know when the feed they’re seeing is limited to a given source. I also made all the source links in the feed clickable so that they could take the user to the corresponding single source feed.
One recurring issue I noticed in my use of the news reader pertained to slow load times. While some of this can be attributed to the “cold start” issue that serverless applications face, much of this was due to how the news reader was fetching pertinent articles from the database. It was deciding at the moment of the fetch request what was most relevant to send over by calculating all the pertinent scores and rank ordering. As the article database got larger, this computation became more complicated.
To address this, I decided to move to a “pre-calculated” ranking system. That way, the system would know what to fetch in advance of a fetch request (and hence return much faster). Couple that with a database index (which effectively “pre-sorts” the results to make retrieval even faster), and I saw visually noticeable improvements in load times.
But with any pre-calculated score scheme, the most important question is how and when re-calculation should happen. Too often and too broadly and you incur unnecessary computing costs. Too infrequently and you risk the scores becoming stale.
The compromise I reached derived itself from the three ways articles are ranked in my system:
The AI’s rating of an article plays the most important role (60%)
How recently the article was published is tied with… (20%)
How similar an article is with the 10 articles a user most recently read (20%
These factors lent themselves to very different natural update cadences:
Newly scraped articles would have their AI ratings and calculated score computed at the time they enter the database
AI ratings for the most recent and the previously highest scoring articles would be re-computed after model training updates
On a daily basis, each article’s score was recomputed (focusing on the change in article recency)
The article similarity for unread articles is re-evaluated after a user reads 10 articles
This required modifying the reader’s existing scraper and post-training processes to update the appropriate scores after scraping runs and model updates. It also meant tracking article reads on the users table (and modifying the /read endpoint to update these scores at the right intervals). Finally, it also meant adding a recurring cleanUp function set to run every 24 hours to perform this update as well as others.
Next Steps
With some of these performance and architecture improvements in place, my priorities are now focused on finding ways to systematically improve the underlying algorithms as well as increase the platform’s usability as a true news tool. To that end some of the top priorities for next steps in my mind include:
Testing new backbone models — The core ranking algorithm relies on Roberta, a model released 5 years ago before large language models were common parlance. Keras Hub makes it incredibly easy to incorporate newer models like Meta’s Llama 2 & 3, OpenAI’s GPT2, Microsoft’s Phi-3, and Google’s Gemma and fine-tune them.
Solving the “all good articles” problem — Because the point of the news reader is to surface content it considers good, users will not readily see lower quality content, nor will they see content the algorithm struggles to rank (i.e. new content very different from what the user has seen before). This makes it difficult to get the full range of data needed to help preserve the algorithm’s usefulness.
Creating topic and author feeds — Given that many people think in terms of topics and authors of interest, expanding what I’ve already done with Sources but with topics and author feeds sounds like a high-value next step
I also endeavor to make more regular updates to the public Github repository (instead of aggregate many updates I had already made into two large ones). This will make the updates more manageable and hopefully help anyone out there who’s interested in building a similar product.
A recent preprint from Stanford has demonstrated something remarkable: AI agents working together as a team solving a complex scientific challenge.
While much of the AI discourse focuses on how individual large language models (LLMs) compare to humans, much of human work today is a team effort, and the right question is less “can this LLM do better than a single human on a task” and more “what is the best team-up of AI and human to achieve a goal?” What is fascinating about this paper is that it looks at it from the perspective of “what can a team of AI agents achieve?”
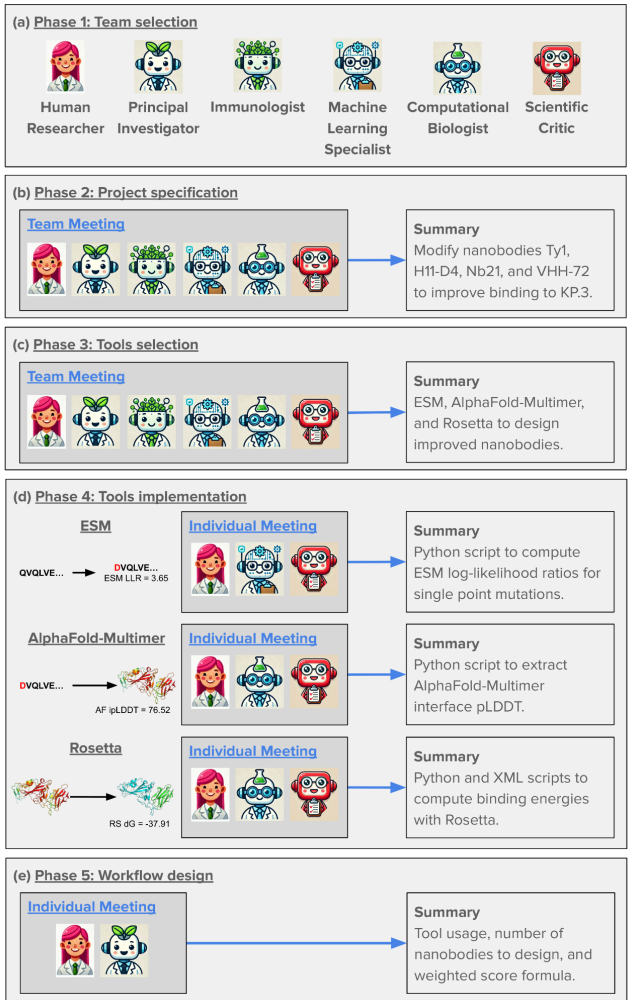
The researchers tackled an ambitious goal: designing improved COVID-binding proteins for potential diagnostic or therapeutic use. Rather than relying on a single AI model to handle everything, the researchers tasked an AI “Principal Investigator” with assembling a virtual research team of AI agents! After some internal deliberation, the AI Principal Investigator selected an AI immunologist, an AI machine learning specialist, and an AI computational biologist. The researchers made sure to add an additional role, one of a “scientific critic” to help ground and challenge the virtual lab team’s thinking.
The team composition and phases of work planned and carried out by the AI principal investigator (Source: Figure 2 from Swanson et al.)
What makes this approach fascinating is how it mirrors high functioning human organizational structures. The AI team conducted meetings with defined agendas and speaking orders, with a “devil’s advocate” to ensure the ideas were grounded and rigorous.
Example of a virtual lab meeting between the AI agents; note the roles of the Principal Investigator (to set agenda) and Scientific Critic (to challenge the team to ground their work) (Source: Figure 6 from Swanson et al.)
One tactic that the researchers said helped with boosting creativity that is harder to replicate with humans is running parallel discussions, whereby the AI agents had the same conversation over and over again. In these discussions, the human researchers set the “temperature” of the LLM higher (inviting more variation in output). The AI principal investigator then took the output of all of these conversations and synthesized them into a final answer (this time with the LLM temperature set lower, to reduce the variability and “imaginativeness” of the answer).
The use of parallel meetings to get “creativity” and a diverse set of options (Source: Supplemental Figure 1 from Swanson et al.)
The results? The AI team successfully designed nanobodies (small antibody-like proteins — this was a choice the team made to pursue nanobodies over more traditional antibodies) that showed improved binding to recent SARS-CoV-2 variants compared to existing versions. While humans provided some guidance, particularly around defining coding tasks, the AI agents handled the bulk of the scientific discussion and iteration.
Experimental validation of some of the designed nanobodies; the relevant comparison is the filled in circles vs the open circles. The higher ELISA assay intensity for the filled in circles shows that the designed nanbodies bind better than their un-mutated original counterparts (Source: Figure 5C from Swanson et al.)
This work hints at a future where AI teams become powerful tools for human researchers and organizations. Instead of asking “Will AI replace humans?”, we should be asking “How can humans best orchestrate teams of specialized AI agents to solve complex problems?”
The implications extend far beyond scientific research. As businesses grapple with implementing AI, this study suggests that success might lie not in deploying a single, all-powerful AI system, but in thoughtfully combining specialized AI agents with human oversight. It’s a reminder that in both human and artificial intelligence, teamwork often trumps individual brilliance.
I personally am also interested in how different team compositions and working practices might lead to better or worse outcomes — for both AI teams and human teams. Should we have one scientific critic, or should their be specialist critics for each task? How important was the speaking order? What if the group came up with their own agendas? What if there were two principal investigators with different strengths?
The next frontier in AI might not be building bigger models, but building better teams.
The 2022 CHIPS and Science Act earmarked hundreds of billions in subsidies and tax credits to bolster a U.S. domestic semiconductor (and especially semiconductor manufacturing) industry. If it works, it will dramatically reposition the U.S. in the global semiconductor value chain (especially relative to China).
With such large amounts of taxpayer money practically “gifted” to large (already very profitable) corporations like Intel, the U.S. taxpayer can reasonably assume that these funds should be allocated carefully and thoughtfully and with processes in place to make sure every penny furthered the U.S.’s strategic goals.
But, when the world’s financial decisions are powered by Excel spreadsheets, even the best laid plans can go awry.
The team behind the startup Rowsie created a large language model (LLM)-powered tool which can understand Excel spreadsheets and answer questions posed to it. They downloaded a spreadsheet that the US government provided as an example of the information and calculations they want applicants fill out in order to qualify. They then applied their AI tool to the spreadsheet to understand it’s structure and formulas.
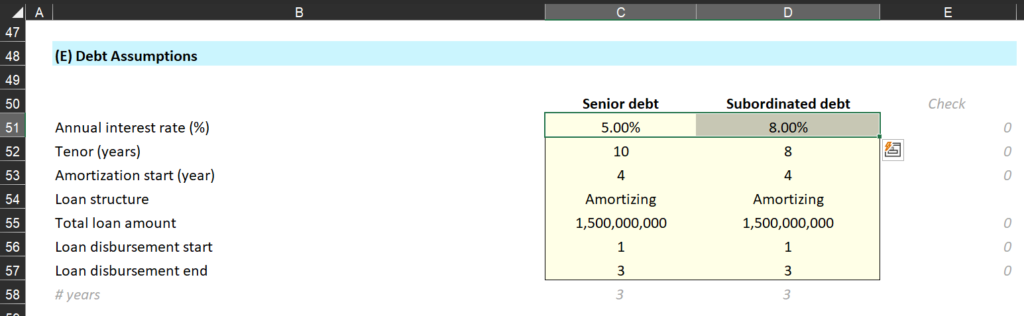
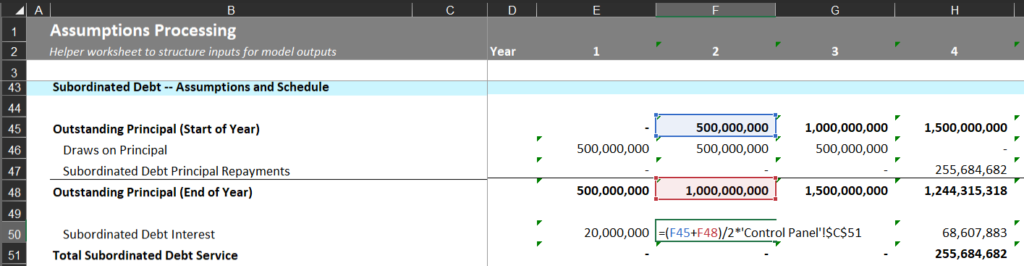
Interestingly, Rowsie was able to find a single-cell spreadsheet error (see images below) which resulted in a $178 million understatement of interest payments!
The Control Panel tab in the Example Pre-App-Simple-Financial-Model spreadsheet from the CHIPS Act funding application website. Notice cells C51 and D51 corresponding to the senior debt interest rate (5%) and the subordinated debt interest rate (8%)The Assumptions Processing tab in the Example Pre-App-Simple-Financial-Model spreadsheet from the CHIPS Act funding application website. Notice row 50. Despite the section being about Subordinated Debt (see Cell B50), they’re using cell C51 from the Control Panel tab (which points to the Senior Debt rate of 5%) rather than the correct cell of D51 (which points to the Subordinated Debt rate of 8%).
To be clear, this is not a criticism of the spreadsheet’s architects. In this case, what seems to have happened, is that the spreadsheet creator copied an earlier row (row 40) and forgot to edit the formula to account for the fact that row 50 is about subordinated debt and row 40 is about senior debt. It’s a familiar story to anyone who’s ever been tasked with doing something complicated in Excel. Features like copy and paste and complex formulas are very powerful, but also make it very easy for a small mistake to cascade. It’s also remarkably hard to catch!
Hopefully the Department of Commerce catches on and fixes this little clerical mishap, and that applicants are submitting good spreadsheets, free of errors. But, this case underscores how (1) so many of the world’s financial and policy decisions rest on Excel spreadsheets and you just have to hope 🤞🏻 no large mistakes were made, and (2) the potential for tools like Rowsie to be tireless proofreaders and assistants who can help us avoid mistakes and understand those critical spreadsheets quickly.
Unless you’ve been under a rock, you’ll know the tech industry has been rocked by the rapid advance in performance by large language models (LLMs) such as ChatGPT. By adapting self-supervised learning methods, LLMs “learn” to sound like a human being by learning how to fill in gaps in language and, by doing so, become remarkably adept at solving not just language problems but understanding & creativity.
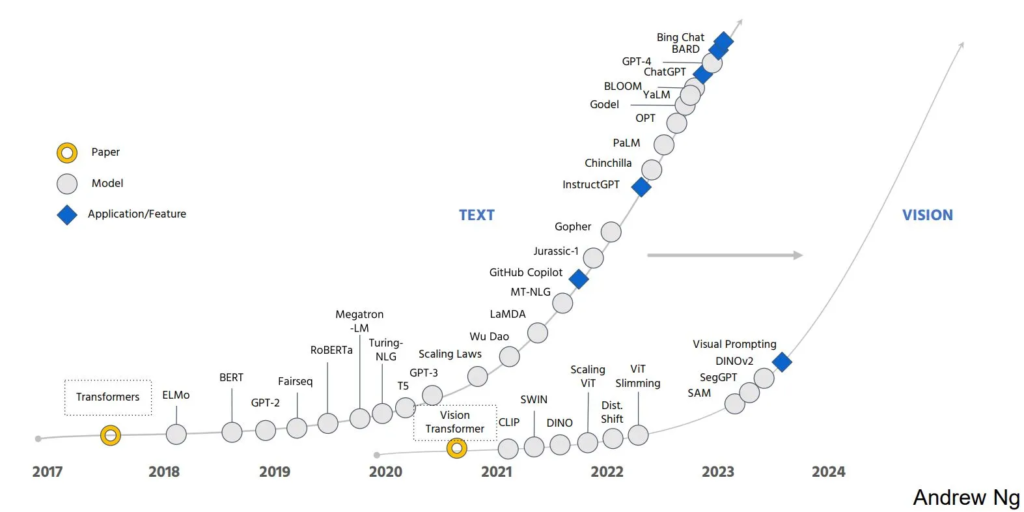
At a talk, Andrew Ng captured it well, by pointing out the parallels between the advances in language modeling that happened after the seminal Transformer paper and what is happening in the “large vision model” world with this great illustration.
“The revolution we’ve seen for text will be coming to images,” renowned computer scientist Andrew Ng asserted in a keynote talk he gave at the recent AI Hardware Summit here.