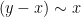Until I read this Verge article, I had assumed that video codecs were a boring affair. In my mind, every few years, the industry would get together and come up with a new standard that promised better compression and better quality for the prevailing formats and screen types and, after some patent licensing back and forth, the industry would standardize around yet another MPEG standard that everyone uses. Rinse and repeat.
The article was an eye-opening look at how video streamers like Netflix are pushing the envelope on using video codecs. Since one of a video streamer’s core costs is the cost of video bandwidth, it would make sense that they would embrace new compression approaches (like different kinds of compression for different content, etc.) to reduce those costs. As Netflix embraces more live streaming content, it seems they’ll need to create new methods to accommodate.
But what jumped out to me the most was that, in order to better test and develop the next generation of codec, they produced a real 12 minute noir film called Meridian (you can access it on Netflix, below is someone who uploaded it to YouTube) which presents scenes that have historically been more difficult to encode with conventional video codecs (extreme lights and shadows, cigar smoke and water, rapidly changing light balance, etc).
Absolutely wild.
While contributing to the development of new video codecs, Aaron and her team stumbled across another pitfall: video engineers across the industry have been relying on a relatively small corpus of freely available video clips to train and test their codecs and algorithms, and most of those clips didn’t look at all like your typical Netflix show. “The content that they were using that was open was not really tailored to the type of content we were streaming,” recalled Aaron. “So, we created content specifically for testing in the industry.”
In 2016, Netflix released a 12-minute 4K HDR short film called Meridian that was supposed to remedy this. Meridian looks like a film noir crime story, complete with shots in a dusty office with a fan in the background, a cloudy beach scene with glistening water, and a dark dream sequence that’s full of contrasts. Each of these shots has been crafted for video encoding challenges, and the entire film has been released under a Creative Commons license. The film has since been used by the Fraunhofer Institute and others to evaluate codecs, and its release has been hailed by the Creative Commons foundation as a prime example of “a spirit of cooperation that creates better technical standards.”
The Dartmouth College Class of 2024, for their graduation, got a very special commencement address from tennis legend Roger Federer.
There is a wealth of good advice in it, but the most interesting point that jumped out to me is that while Federer won a whopping 80% of the matches he played in his career, he only won 54% of the points. It underscores the importance of letting go of small failures (“When you lose every second point, on average, you learn not to dwell on every shot”) but also of keeping your eye on the right metric (games, not points).
In tennis, perfection is impossible… In the 1,526 singles matches I played in my career, I won almost 80% of those matches… Now, I have a question for all of you… what percentage of the POINTS do you think I won in those matches?
Only 54%.
In other words, even top-ranked tennis players win barely more than half of the points they play.
Strong regional industrial ecosystems like Silicon Valley (tech), Boston (life science), and Taiwan (semiconductors) are fascinating. Their creation is rare and requires local talent, easy access to supply chains and distribution, academic & government support, business success, and a good amount of luck.
But, once set in place, they can be remarkably difficult to unseat. Take the semiconductor industry as an example. It’s geopolitical importance has directed billions of dollars towards re-creating a domestic US industry. But, it faces an uphill climb. After all, it’s not only a question of recreating the semiconductor manufacturing factories that have gone overseas, but also:
the advanced and low-cost packaging technologies and vendors that are largely based in Asia
the engineering and technician talent that is no longer really in the US
the ecosystem of contractors and service firms that know exactly how to maintain the facilities and equipment
the supply chain for advanced chemicals and specialized parts that make the process technology work
the board manufacturers and ODMs/EMSs who do much of the actual work post-chip production that are also concentrated in Asia
A similar thing has happened in the life sciences CDMO (contract development and manufacturing organization) space. In much the same way that Western companies largely outsourced semiconductor manufacturing to Asia, Western biopharma companies outsourced much of their core drug R&D and manufacturing to Chinese companies like WuXi AppTec and WuXi Biologics. This has resulted in a concentration of talent and an ecosystem of talent and suppliers there that would be difficult to supplant.
Enter the BIOSECURE Act, a bill being discussed in the House with a strong possibility of becoming a law. It prohibits the US government from working with companies that obtain technology from Chinese biotechnology companies of concern (including WuXi AppTec and WuXi Biologics, among others). This is causing the biopharma industry significant anxiety as they are forced to find (and potentially fund) an alternative CDMO ecosystem that currently does not exist at the level of scale and quality as it does with WuXi.
According to [Harvey Berger, CEO of Kojin Therapeutics], China’s CDMO industry has evolved to a point that no other country comes close to. “Tens of thousands of people work in the CDMO industry in China, which is more than the rest of the world combined,” he says.
Meanwhile, Sound’s Kil says he has worked with five CDMOs over the past 15 years and is sure he wouldn’t return to three of them. The two that he finds acceptable are WuXi and a European firm.
“When we asked the European CDMO about their capacity to make commercial-stage quantities, they told us they would have to outsource it to India,” Kil says. WuXi, on the other hand, is able to deliver large quantities very quickly. “It would be terrible for anyone to restrict our ability to work with WuXi AppTec.”
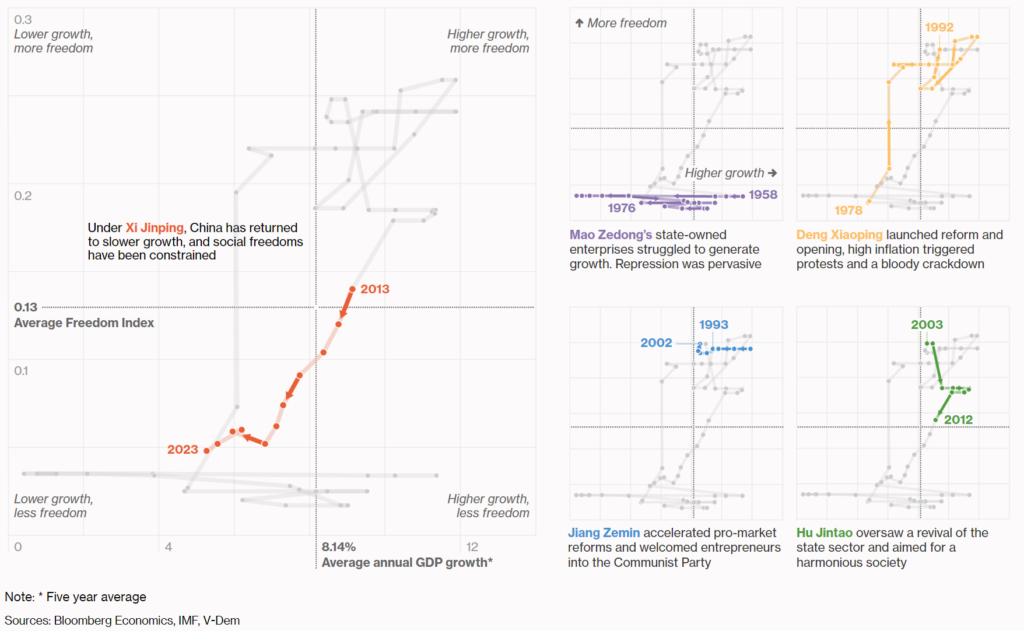
Fascinating chart from Bloomberg showing level of economic freedom and prosperity under different Chinese rulers and how Xi Jinping is the first Chinese Communist Party ruler in history to have presided over sharp declines in both freedom and prosperity.
Given China’s rising influence in economic and geopolitical affairs, how it’s leaders (and in particular, Xi) and it’s people react to this will have significant impacts on the world
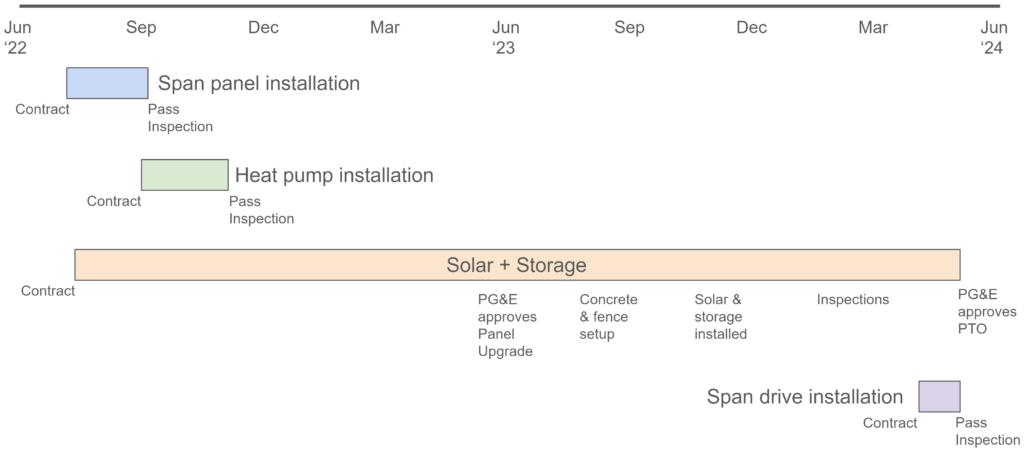
Electrifying our (Bay Area) home was a complex and drawn-out process, taking almost two years.
Installing solar panels and storage was particularly challenging, involving numerous hurdles and unexpected setbacks.
We worked with a large solar installer (Sunrun) and, while the individuals we worked with were highly competent, handoffs within Sunrun and with other entities (like local utility PG&E and the local municipality) caused significant delays.
While installing the heat pumps, smart electric panel, and EV charger was more straightforward, these projects also featured greater complexity than we expected.
The project resulted in significant quality of improvements around home automation and comfort. However, bad pricing dynamics between electricity and natural gas meant direct cost savings from electrifying gas loads are, at best, small. While solar is an economic slam-dunk (especially given the rising PG&E rates our home sees), the batteries, in the absence of having backup, have less obvious economic value.
Our experience underscored the need for the industry to adopt a more holistic approach to electrification and for policymakers to make the process more accessible for all homeowners to achieve the state’s ambitious goals.
Why
The decision to electrify our home was an easy one. From my years of investing in & following climate technologies, I knew that the core technologies were reliable and relatively inexpensive. As parents of young children, my wife and I were also determined to contribute positively to the environment. We also knew there were abundant financial supports from local governments and utilities to help make this all work.
Yet, as we soon discovered, what we expected to be a straightforward path turned into a nearly two-year process!
Even for a highly motivated household which had budgeted significant sums for it all, it was still shocking how long (and much money) it took. It made me skeptical that households across California would be able to do the same to meet California’s climate goals without additional policy changes and financial support.
The Plan
Two years ago, we set out a plan:
Smart electrical panel — From my prior experience, I knew that many home electrification projects required a main electrical panel upgrade. These were typically costly and left you at the mercy of the utility to actually carry them out (I would find out how true this was later!). Our home had an older main panel rated for 125 A and we suspected we would normally need a main panel upgrade to add on all the electrical loads we were considering.
To try to get around this, we decided to get a smart electrical panel which could:
use software smarts to deal with the times where peak electrical load got high enough to need the entire capacity of the electrical line
give us the ability to intelligently manage backups and track solar production
In doing our research, Span seemed like the clear winner. They were the most prominent company in the space and had the slickest looking device and app (many of their team had come from Tesla). They also had an EV charger product we were interested in, the Span Drive.
Heat pumps — To electrify is to ditch natural gas. As the bulk of our gas consumption was heating air and water, this involved replacing our gas furnace and gas water heater with heat pumps. In addition to significant energy savings — heat pumps are famous for their >200% efficiency (as they move heat rather than “create” it like gas furnaces do) — heat pumps would also let us add air conditioning (just run the heat pump in reverse!) and improve our air quality (from not combusting natural gas indoors). We found a highly rated Bay Area HVAC installer who specializes in these types of energy efficiency projects (called Building Efficiency) and trusted that they would pick the right heat pumps for us.
Solar and Batteries — No electrification plan is complete without solar. Our goal was to generate as much clean electricity as possible to power our new electric loads. We also wanted energy storage for backup power during outages (something that, while rare, we seemed to run into every year) and to take advantage of time-of-use rates (by storing solar energy when the price of electricity is low and then using it when the price is high).
We looked at a number of solar installers and ultimately chose Sunrun. A friend of ours worked there at the time and spoke highly of a prepaid lease they offered that was vastly cheaper all-in than every alternative. It offered minimum energy production guarantees, came with a solid warranty, and the “peace of mind” that the installation would be done with one of the largest and most reputable companies in the solar industry.
EV Charger — Finally, with our plan to buy an electric vehicle, installing a home charger at the end of the electrification project was a simple decision. This would allow us to conveniently charge the car at home, and, with solar & storage, hopefully let us “fuel up” more cost effectively. Here, we decided to go with the Span Drive. It’s winning feature was the ability to provide Level 2 charging speeds without a panel upgrade (it does this by ramping up or down charging speeds depending on how much electricity the rest of the house needed). While pricey, the direct integration into our Span smart panel (and its app) and the ability to hit high charging rates without a panel upgrade felt like the smart path forward.
What We Left Out — There were two appliances we decided to defer “fully going green” on.
The first was our gas stove (with electric oven). While induction stoves have significant advantages, because our current stove is still relatively new, works well, uses relatively little gas, and an upgrade would have required additional electrical work (installing a 240 V outlet), we decided to keep our current stove and consider a replacement at it’s end of life.
The second was our electric resistive dryer. While heat pump based dryers would certainly save us a great deal of electricity, the existing heat pump dryers on the market have much smaller capacities than traditional resistive dryers, which may have necessitated our family of four doing additional loads of drying. As our current dryer was also only a few years old, and already running on electricity, we decided we would also wait to consider heat pump dryer only after it’s end of life.
With what we thought was a well-considered plan, we set out and lined up contractors.
But as Mike Tyson put it, “Everyone has a plan ’till they get punched in the face.”
The Actual Timeline
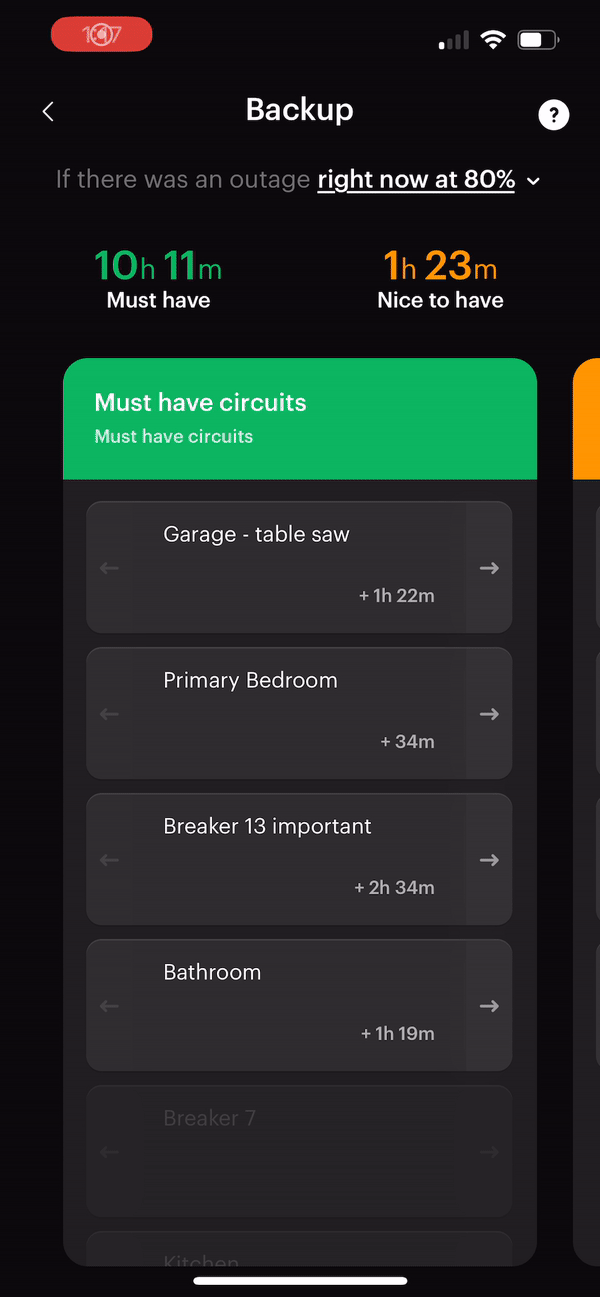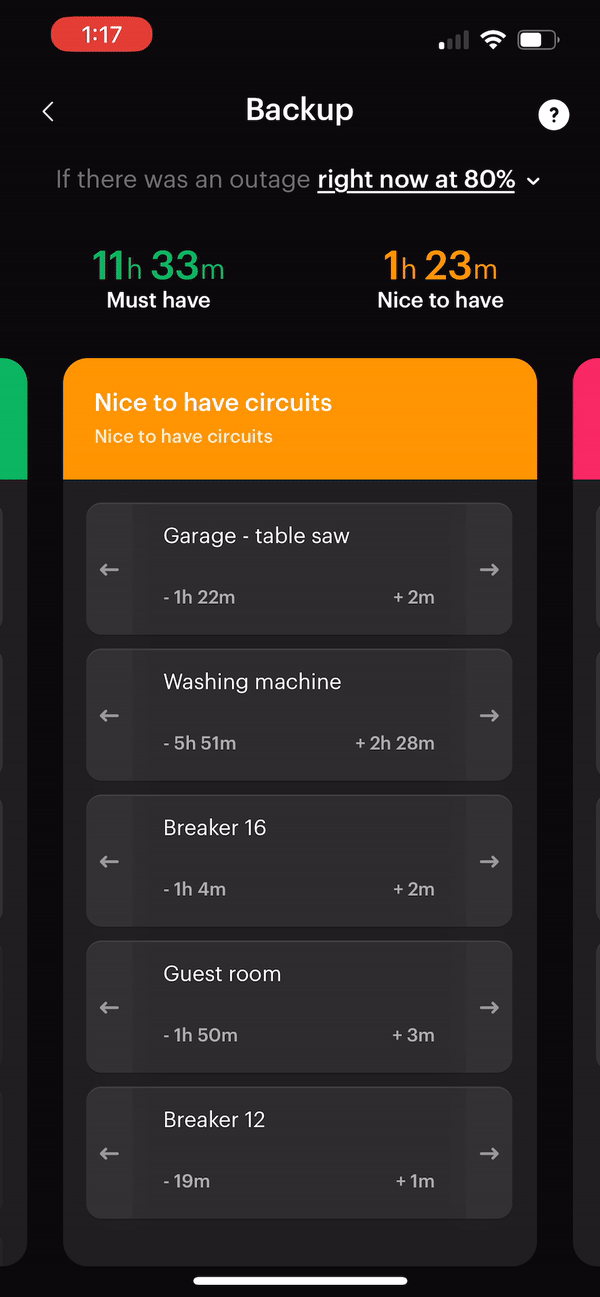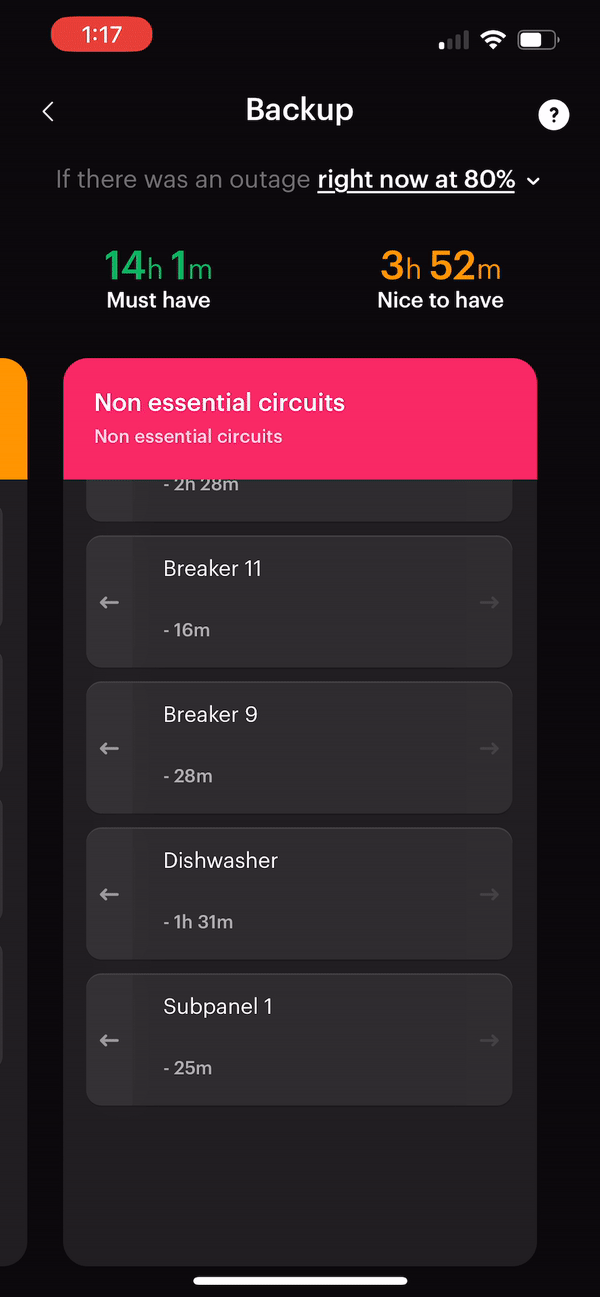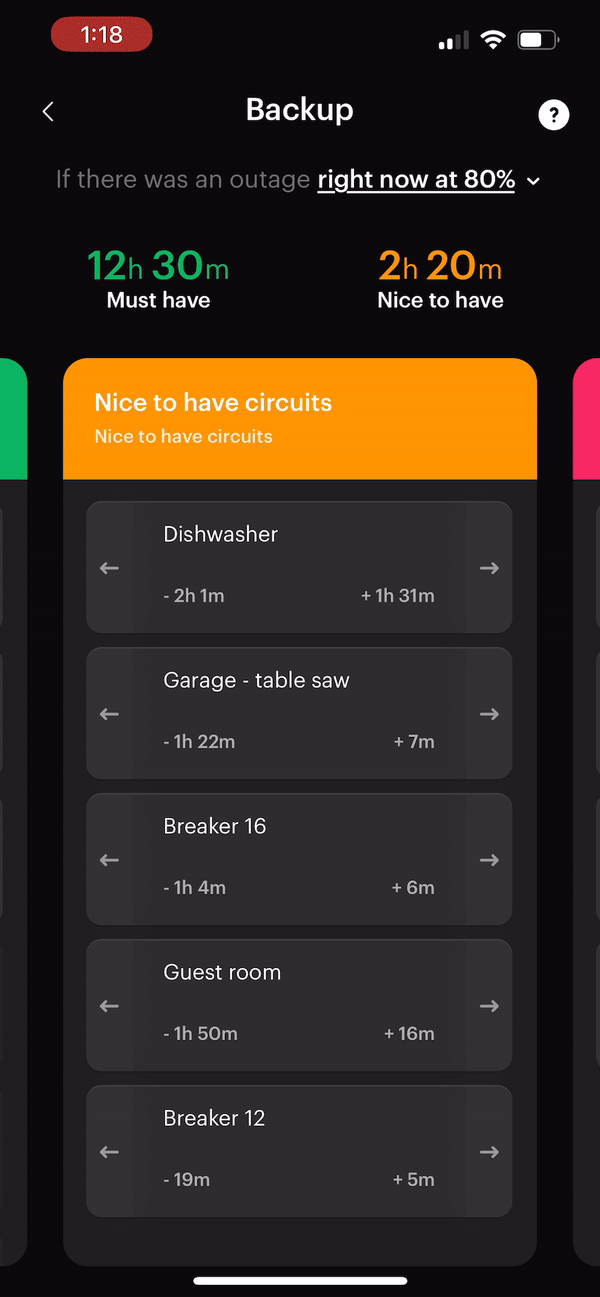
Smart Panel
The smart panel installation was one of the more straightforward parts of our electrification journey. Span connected us with a local electrician who quickly assessed our site, provided an estimate, and completed the installation in a single day. However, getting the permits to pass inspection was a different story.
We failed the first inspection due to a disagreement over the code between the electrician and the city inspector. This issue nearly turned into a billing dispute with the electrician, who wanted us to cover the extra work needed to meet the code (an unexpected cost). Fortunately, after a few adjustments and a second inspection, we passed.
The ability to control and monitor electric flows with the smart panel is incredibly cool. For the first few days, I checked the charts in the apps every few minutes tracking our energy use while running different appliances. It was eye-opening to see just how much power small, common household items like a microwave or an electric kettle could draw!
However, the true value of a smart panel is only achieved when it’s integrated with batteries or significant electric loads that necessitate managing peak demand. Without these, the monitoring and control benefits are more novelties and might not justify the cost.
Note: if you, like us, use Pihole to block tracking ads, you’ll need to disable it for the Span app. The app uses some sort of tracker that Pihole flags by default. It’s an inconvenience, but worth mentioning for anyone considering this path.
Heating
Building Efficiency performed an initial assessment of our heating and cooling needs. We had naively assumed they’d be able to do a simple drop-in replacement for our aging gas furnace and water heater. While the water heater was a straightforward replacement (with a larger tank), the furnace posed more challenges.
Initially, they proposed multiple mini-splits to provide zoned control, as they felt the crawlspace area where the gas furnace resided was too small for a properly sized heat pump. Not liking the aesthetics of mini-splits, we requested a proposal involving two central heat pump systems instead.
Additionally, during the assessment, they found some of our old vents, in particular the ones sending air to our kids’ rooms, were poorly insulated and too small (which explains why their rooms always seemed under-heated in the winter). To fix this, they had to cut a new hole through our garage concrete floor (!!) to run a larger, better-insulated vent from our crawlspace. They also added insulation to the walls of our kids’ rooms to improve our home’s ability to maintain a comfortable temperature (but which required additional furniture movement, drywall work, and a re-paint).
Building Efficiency spec’d an Ecobee thermostat to control the two central heat pumps. As we already had a Nest Learning Thermostat (with Nest temperature sensors covering rooms far from the thermostat), we wanted to keep our temperature control in the Nest app. At the time, we had gotten a free thermostat from Nest after signing with Sunrun. We realized later, what Sunrun gifted us was the cheaper (and, less attractive) Nest Thermostat which doesn’t support Nest temperature sensors (why?), so we had to buy our own Nest Learning Thermostat to complete the setup.
Despite some of these unforeseen complexities, the whole process went relatively smoothly. There were a few months of planning and scheduling, but the actual installation was completed in about a week. It was a very noisy (cutting a hole through concrete is not quiet!) and chaotic week, but, the process was quick, and the city inspection was painless.
Solar & Storage
The installation of solar panels and battery storage was a lengthy ordeal. Sunrun proposed a system with LONGI solar panels, two Tesla Powerwalls, a SolarEdge inverter, and a Tesla gateway. Despite the simplicity of the plan, we encountered several complications right away.
First, a main panel upgrade was required. Although we had installed the Span smart panel to avoid this, Sunrun insisted on the upgrade and offered to cover the cost. Our utility PG&E took over a year (!!) to approve our request, which started a domino of delays.
After PG&E’s approval, Sunrun discovered that local ordinances needed a concrete pad to be poured and safety fence erected around the panel, requiring a subcontractor and yet more coordination.
After the concrete pad was in place and the panel installed, we faced another wait for PG&E to connect the new setup. Ironically, during this wait, I received a request from Sunrun to pour another concrete pad. This was, thankfully, a false alarm and occurred because the concrete pad / safety fence work had not been logged in Sunrun’s tracking system!
The solar and storage installation itself took only a few days, but during commissioning, a technician found that half the panels weren’t connected properly, necessitating yet another visit before Sunrun could request an inspection from the city.
Sadly, we failed our first city inspection. Sunrun’s team had missed a local ordinance that required the Powerwalls to have a minimum distance between them and the sealing off of vents within a certain distance from each Powerwall. This necessitated yet another visit from Sunrun’s crew, and another city inspection (which we thankfully passed).
The final step was obtaining Permission to Operate (PTO) from PG&E. The application for this was delayed due to a clerical error. About four weeks after submission, we finally received approval.
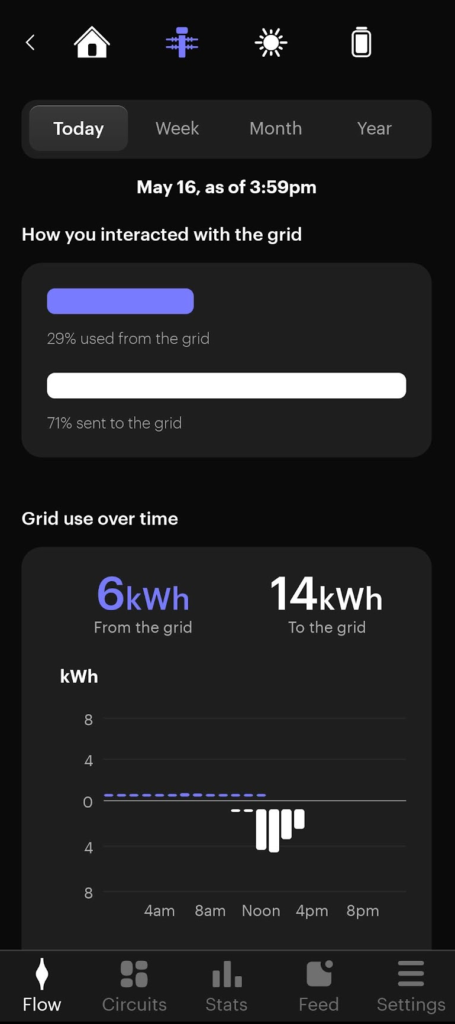
Seeing the flow of solar electricity in my Span app (below) almost brought a tear to my eye. Finally!
EV Charger
When my wife bought a Nissan Ariya in early 2023, it came with a year of free charging with EVgo. We hoped this would allow us enough time to install solar before needing our own EV charger. However, the solar installation took longer than expected (by over a year!), so we had to expedite the installation of a home charger.
Span connected us with the same electrician who installed our smart panel. Within two weeks of our free charging plan expiring, the Span Drive was installed. The process was straightforward, with only two notable complications we had to deal with:
The 20 ft cable on the Span Drive sounds longer than it is in practice. We adjusted our preferred installation location to ensure it comfortably reached the Ariya’s charging port.
The Span software initially didn’t recognize the Span Drive after installation. This required escalated support from Span to reset the software, costing the poor electrician who had expected the commissioning step to be a few minute affair to stick around my home for several hours.
Result
So, “was it worth it?” Yes! There are significant environmental (our carbon footprint is meaningfully lower) benefits. But there were also quality of life improvements and financial gains from these investments in what are just fundamentally better appliances.
Quality of Life
Our programmable, internet-connected water heater allows us to adjust settings for vacations, saving energy and money effortlessly. It also lets us program temperature cycles to avoid peak energy pricing, heating water before peak rates hit.
With the new heat pumps, our home now has air conditioning, which is becoming increasingly necessary in the Bay Area’s warmer summers. Improved vents and insulation have also made our home (and, in particular, our kids’ rooms) more comfortable. We’ve also found that the heat from the heat pumps is more even and less drying compared to the old gas furnace, which created noticeable hot spots.
Backup power during outages is another significant benefit. Though we haven’t had to use it since we received permission to operate, we had an accidental trial run early on when a Sunrun technician let our batteries be charged for a few days in the winter. During two subsequent outages in the ensuing months, our system maintained power to our essential appliances, ensuring our kids didn’t even notice the disruptions!
The EV charger has also been a welcome change. While free public charging was initially helpful, reliably finding working and available fast chargers could be time-consuming and stressful. Now, charging at home is convenient and cost-effective, reducing stress and uncertainty.
Financial
There are two financial aspects to consider: the cost savings from replacing gas-powered appliances with electric ones and the savings from solar and storage.
On the first, the answer is not promising.
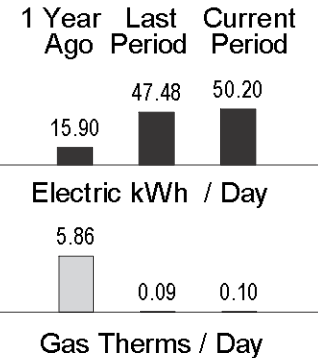
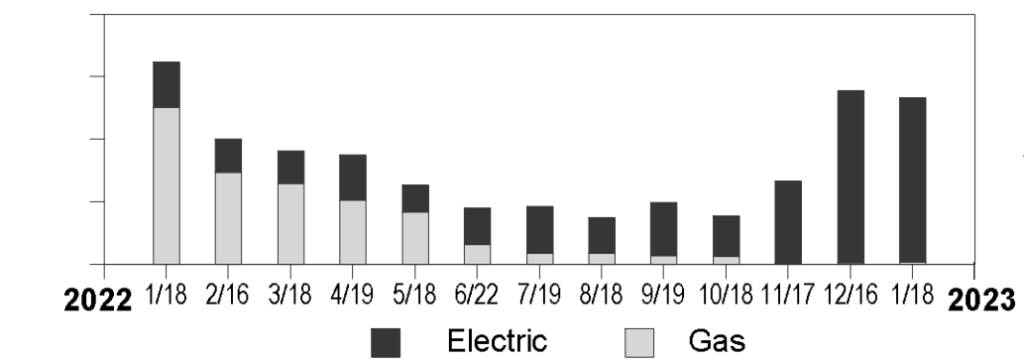
The chart below comes from our PG&E bill for Jan 2023. It shows our energy usage year-over-year. After installing the heat pumps in late October 2022, our natural gas consumption dropped by over 98% (from 5.86 therms/day to 0.10), while our electricity usage more than tripled (from 15.90 kWh/day to 50.20 kWh/day). Applying the conversion of 1 natural gas therm = ~29 kWh of energy shows that our total energy consumption decreased by over 70%, a testament to the much higher efficiency of heat pumps.
Our PG&E bill from Feb 2023 (for Jan 2023)
Surprisingly, however, our energy bills remained almost unchanged despite this! The graph below shows our PG&E bills over the 12 months ending in Jan 2023. Despite a 70% reduction in energy consumption, the bill stayed roughly the same. This is due to the significantly lower cost of gas in California compared to the equivalent amount of energy from electricity. It highlights a major policy failing in California: high electricity costs (relative to gas) will deter households from switching to greener options.
Our PG&E bill from Feb 2023 (for Jan 2023)
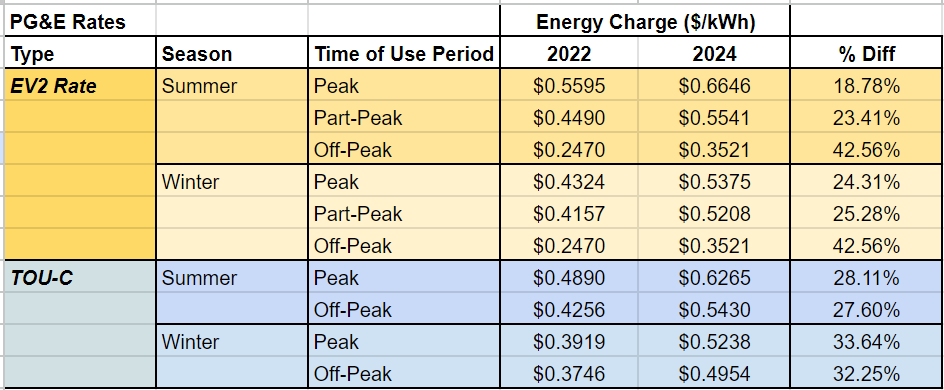
Solar, however, is a clear financial winner. With our prepaid lease, we’d locked in savings compared to 2022 rates (just by dividing the total prepaid lease amount by the expected energy production over the lifetime of the lease), and these savings have only increased as PG&E’s rates have risen (see chart below).
Batteries, on the other hand, are much less clear-cut financially due to their high initial cost and only modest savings from time-shifting electricity use. However, the peace of mind from having backup power during outages is valuable (not to mention the fact that, without a battery, solar panels can’t be used to power your home during an outage), and, with climate change likely to increase both peak/off-peak rate disparities and the frequency of outages, we believe this investment will pay off in the long run.
Taking Advantage of Time of Use Rates
Time of Use (TOU) rates, like PG&E’s electric vehicle time of use rates, offer a smart way to reduce electricity costs for homes with solar panels, energy storage, and smart automation. This approach has fundamentally changed how we manage home energy use. Instead of merely conserving energy by using efficient appliances or turning off devices when not needed, we now view our home as a giant configurable battery. We “save” energy when it’s cheap and use it when it’s expensive.
Backup Reserve: We’ve set our Tesla Powerwall to maintain a 25% reserve. This ensures we always have a good supply of backup power for essential appliances (roughly 20 hours for our highest priority circuits by the Span app’s latest estimates) during outages
Summer Strategy: During summer, our Powerwall operates in “Self Power” mode, meaning solar energy powers our home first, then charges the battery, and lastly any excess goes to the grid. This maximizes the use of our “free” solar energy. We also schedule our heat pumps to run during midday when solar production peaks and TOU rates are lower. This way, we “store” cheaper energy in the form of pre-chilled or pre-heated air and water which helps maintain the right temperatures for us later (when the energy is more expensive).
Winter Strategy: In winter, we will switch the Powerwall to “Time-Based Control.” This setting preferentially charges the battery when electricity is cheap and discharges it when prices are high, maximizing the financial value of our solar energy during the months where solar production is likely to be limited.
This year will be our first full cycle with all systems in place, and we expect to make adjustments as rates and energy usage evolve. For those considering home electrification, hopefully these strategies give hints to what is possible to improve economic value of your setup.
Takeaways
Two years is too long: The average household might not have started this journey if they knew the extent of time and effort involved. This doesn’t even consider the amount of carbon emissions from running appliances off grid energy due to the delays. Streamlining the process is essential to make electrification more accessible and appealing.
Align gas and electricity prices with climate goals: The current pricing dynamics make it financially challenging for households to switch from gas appliances to greener options like heat pumps. To achieve California’s ambitious climate goals, it’s crucial to align the cost of electricity more closely with electrification.
Streamline permitting: Electrification projects are slowed by complex, inconsistent permitting requirements across different jurisdictions. Simplifying and unifying these processes will reduce time and costs for homeowners and their contractors.
Accelerate utility approvals: The two-year timeframe was largely due to delays from our local utility, PG&E. As utilities lack incentives to expedite these processes, regulators should build in ways to encourage utilities to move faster on home electrification-related approvals and activities, especially as many homes will likely need main panel upgrades to properly electrify.
Improve financing accessibility: High upfront costs make it difficult for households to adopt electrification, even when there are significant long-term savings. Expanding financing options (like Sunrun’s leases) can encourage more households to invest in these technologies. Policy changes should be implemented so that even smaller installers have the ability to offer attractive financing options to their clients.
Break down electrification silos: Coordination between HVAC specialists, solar installers, electricians, and smart home companies is sorely missing today. As a knowledgeable early adopter, I managed to integrate these systems on my own, but this shouldn’t be the expectation if we want broad adoption of electrification. The industry (in concert with policymakers) should make it easier for different vendors to coordinate and for the systems to interoperate more easily in order to help homeowners take full advantage of the technology.
This long journey highlighted to me, in a very visceral way, both the rewards and practical challenges of home electrification. While the environmental, financial, and quality-of-life benefits are clear, it’s also clear that we have a ways to go on the policy and practical hurdles before electrification becomes an easy choice for many more households. I only hope policymakers and technologists are paying attention. Our world can’t wait much longer.
The Merchant Marine Act of 1920 (aka “The Jones Act”) is a law which requires ships operating between US ports to be owned by, made in, and crewed by US citizens.
While many “Made in the USA” laws are on the books and attract the anger of economists and policy wonks, the Jones Act is particularly egregious as the costs and effects are so large. The Jones Act costs states like Hawaii and Alaska and territories like Puerto Rico dramatically as they rely so much on ships for basic commerce that it was actually cheaper for Hawaii and New England to import oil from other countries (like Hawaii did from Russia until the Ukraine war) than it was to have oil shipped from the Gulf of Mexico (where American oil is abundant).
In the case of offshore wind, the Jones Act has pushed those companies willing to experiment with the promising technology, to ship the required parts and equipment from overseasbecause there are no Jones Act-compliant ships capable of moving the massive equipment that is involved.
This piece from Canary Media captures some of the dynamics and the “launch” of the still-in-construction $625 million Jones Act-compliant ship the Charybdis Dominion Energy will use to support its offshore wind facility.
To satisfy that mandate, Dominion commissioned the first-ever Jones Act–compliant vessel for offshore wind installation, which hit the water in Brownsville, Texas, last week. The hull welding on the 472-foot vessel is complete, as are its four enormous legs, which will hoist it out of the water during turbine installation. This $625 million leviathan, named Charybdis after the fearsome sea-monster foe of Odysseus, still needs some finishing touches before it sets sail to Virginia, which is expected to happen later this year.
Charybdis’ completion will be a win for what’s left of the American shipbuilding industry. The Jones Act, after all, was intended to bolster American shipbuilders and merchant seamen in the isolationist spell following World War I. But a century later, it creates a series of confounding and counterintuitive challenges for America’s energy industry, which frequently redound poorly for most Americans.
…
Elsewhere in the energy industry, the expense and difficulty associated with finding scarce Jones Act–compliant ships push certain American communities to rely more on foreign energy suppliers. Up until 2022, Hawaii turned to Russia for one-third of the oil that powered its cars and power plants. The Jones Act made it too hard or costly to import abundant American oil to the U.S. state, leaving Hawaii scrambling for other sources when Russia invaded Ukraine.
Over in New England, constraints on fossil-gas pipelines sometimes force the region to import gas via LNG terminals. The U.S. has plenty of fossil gas to tap in the Gulf of Mexico, but a lack of U.S. ships pushes Massachusetts and its neighbors to buy gas from other countries instead.
But, over time, as the server has picked up more uses, it’s also become a vulnerability. If any of the drives on my machine ever fail, I’ll lose data that is personally (and sometimes economically) significant.
I needed a home server backup plan.
Duplicati
Duplicati is open source software that helps you efficiently and securely backup specific partitions and folders to any destination. This could be another home server or it can be a cloud service provider (like Amazon S3 or Backblaze B2 or even a consumer service like Dropbox, Google Drive, and OneDrive). While there are many other tools that can support backup, I went with Duplicati because I wanted:
Support for consumer storage services as a target: I am a customer of Google Drive (through Google One) and Microsoft 365 (which comes with generous OneDrive subscription) and only intend to backup some of the files I’m currently storing (mainly some of the network storage I’m using to hold important files)
A web-based control interface so I could access this from any computer (and not just whichever machine had the software I wanted)
If you haven’t already, make sure you have OMV Extras and Docker Compose installed (refer to the section Docker and OMV-Extras in my previous post, you’ll want to follow all 10 steps as I refer to different parts of the process throughout this post) and have a static local IP address assigned to your server.
Login to your OpenMediaVault web admin panel, and then go to [Services > Compose > Files] in the sidebar. Press the button in the main interface to add a new Docker compose file.
Under Name put down Duplicati and under File, adapt the following (making sure the number of spaces are consistent)
Under ports:, make sure to add an unused port number (I went with 8200).
Replace <absolute path to shared config folder> with the absolute path to the config folder where you want Docker-installed applications to store their configuration information (accessible by going to [Storage > Shared Folders] in the administrative panel).
You’ll notice there’s extra lines under volumes: for <absolute paths to folders to backup>. This should correspond with the folders you are interested in backing up. You should map them to names that will show up in the Duplicati interface that you recognize. For example, I directed my <absolute path to shared config folder> to /containerconfigs as one of the things I want to make sure I backup are my containers.
Once you’re done, hit Save and you should be returned to your list of Docker compose files for the next step. Notice that the new Duplicati entry you created has a Down status, showing the container has yet to be initialized.
To start your Duplicati container, click on the new Duplicati entry and press the (up) button. This will create the container, download any files needed, and run it.
To show it worked, go to your-servers-static-ip-address:8200 from a browser that’s on the same network as your server (replacing 8200 if you picked a different port in the configuration file above) and you should see the Duplicati web interface which should look something like below
You can skip this step if you didn’t set up Pihole and local DNS / Nginx proxy or if you don’t care about having a user-readable domain name for Duplicati. But, assuming you do and you followed my instructions, open up WeTTy (which you can do by going to wetty.home in your browser if you followed my instructions or by going to [Services > WeTTY] from OpenMediaVault administrative panel and pressing Open UI button in the main panel) and login as the root user. Run:
cd /etc/nginx/conf.d
ls
nano <your file name>.confCode language:Shell Session(shell)
This opens up the text editor nano with the file you just listed. Use your cursor to go to the very bottom of the file and add the following lines (making sure to use tabs and end each line with a semicolon)
And then hit Ctrl+X to exit, Y to save, and Enter to overwrite the existing file. Then in the command line run the following to restart Nginx with your new configuration loaded.
systemctl restart nginx
Now, if your server sees a request for duplicati.home (or whichever domain you picked), it will direct them to Duplicati. With the additional proxy_http_version and proxy_set_header‘s, it will also properly forward the Websocket requests the web interface uses.
Login to your Pihole administrative console (you can just go to pi.hole in a browser) and click on [Local DNS > DNS Records] from the sidebar. Under the section called Add a new domain/IP combination, fill out under Domain: the domain you just added above (i.e. duplicati.home) and next to IP Address: you should add your server’s static IP address. Press the Add button and it will show up below.
To make sure it all works, enter the domain you just added (duplicati.home if you went with my default) in a browser and you should see the Duplicati interface!
Configuring your Backups
Duplicati conceives of each “backup” as a “source” (folder of files to backup), a “destination” (the place the files should be backed up to), a schedule (how often does the backup run), and some options to configure how the backup works.
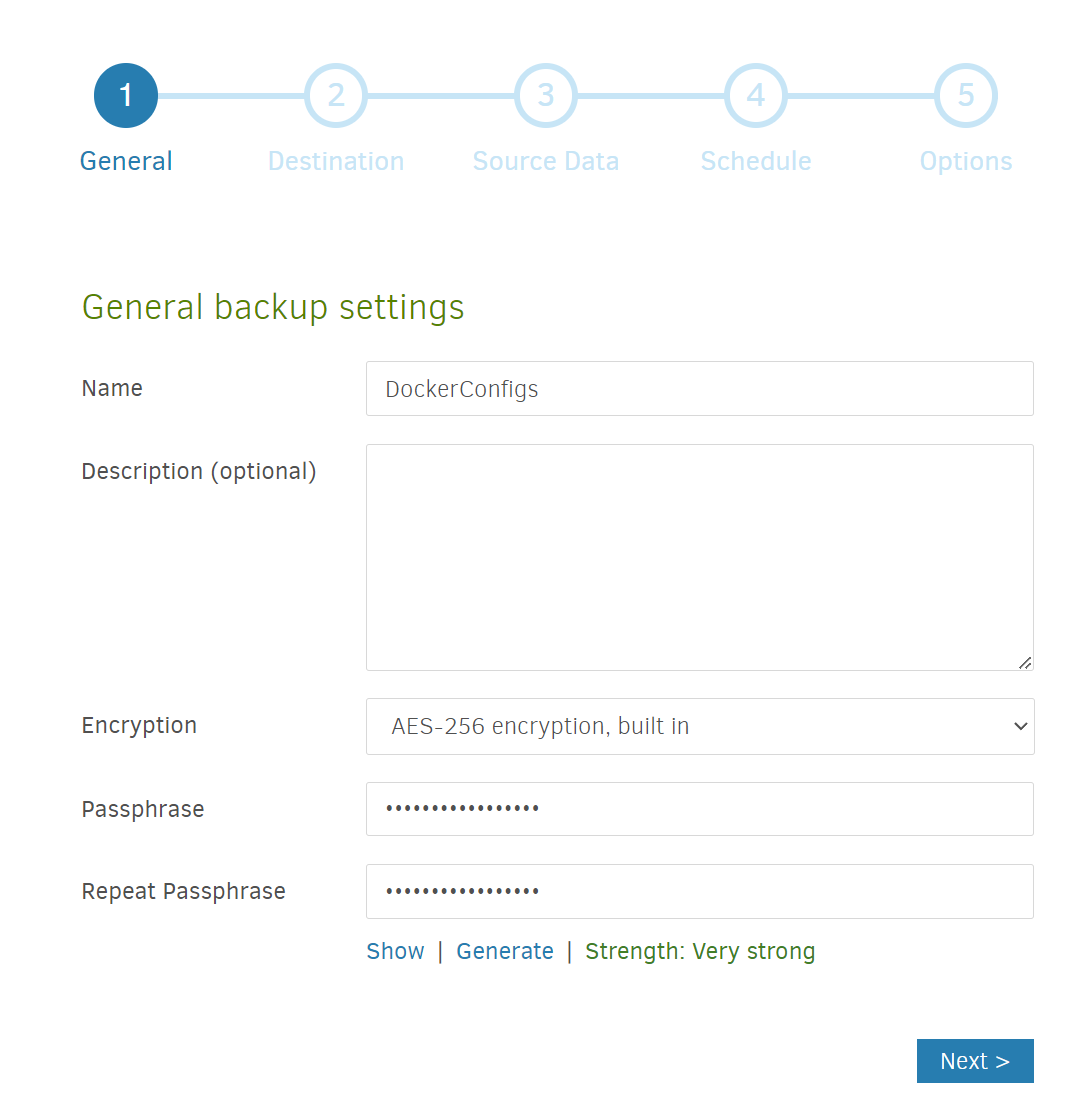
After logging in (with the password you specified in the Docker compose file), to configure a “backup”, click on +Add Backup button on the menu on the lefthand side. I’ll show you the screens I went through to backup my Docker container configurations:
Add a name (I called it DockerConfigs) and enter a Passphrase (you can use the Generate link to create a strong password) which you’d use to restore from backup. Then hit Next
Enter a destination. Here, you can select another computer or folder connected to your network. You can also select an online storage service.
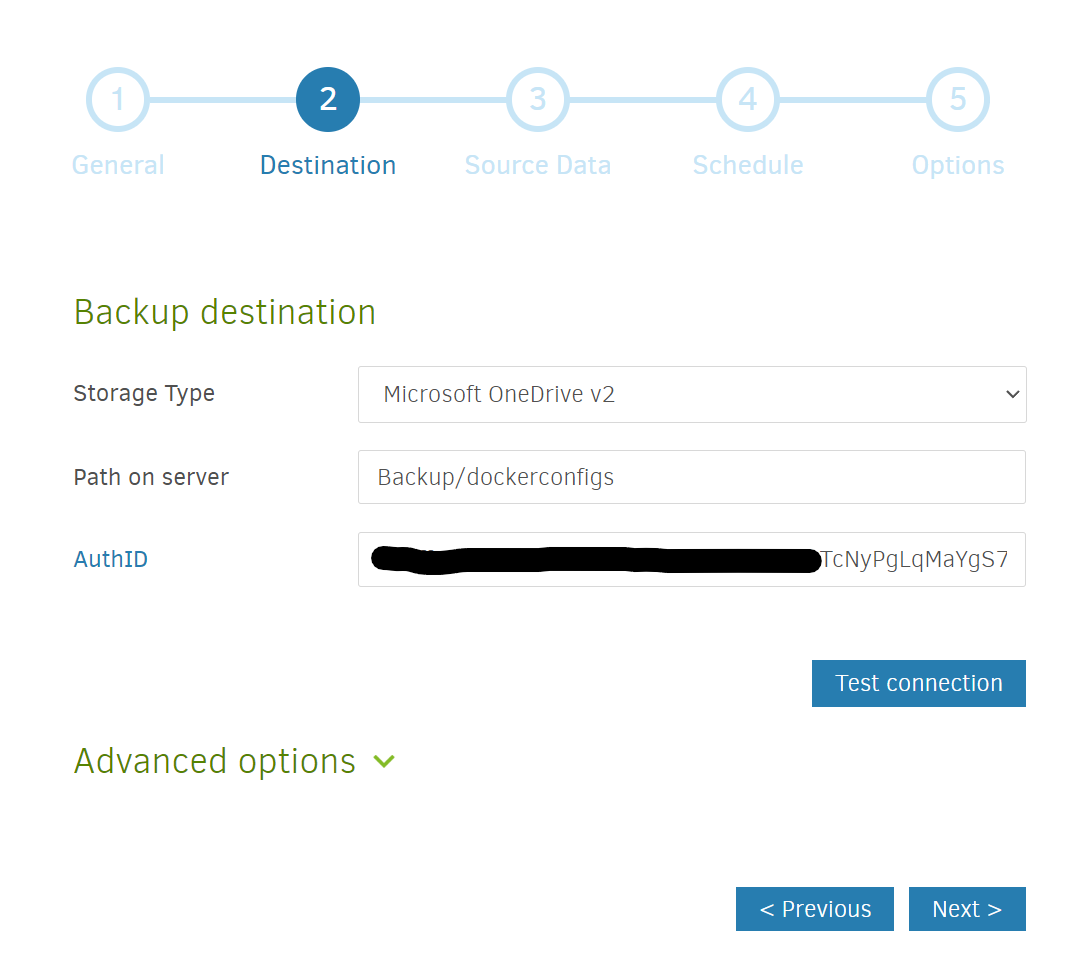
I’m using Microsoft OneDrive — for a different service, a quick Google search or a search of the Duplicati how-to forum can give you more specific instructions, but the basic steps of generating an AuthID link appear to be similar across many services.
I selected Microsoft OneDrive v2 and picked a path in my OneDrive for the backup to go to (Backup/dockerconfigs). I then clicked on the AuthID link and went through an authentication process to formally grant Duplicati access to OneDrive. Depending on the service, you may need to manually copy a long string of letters and numbers and colons into the text field. After all of that, to prove it all worked, press Test connection!
Then hit Next
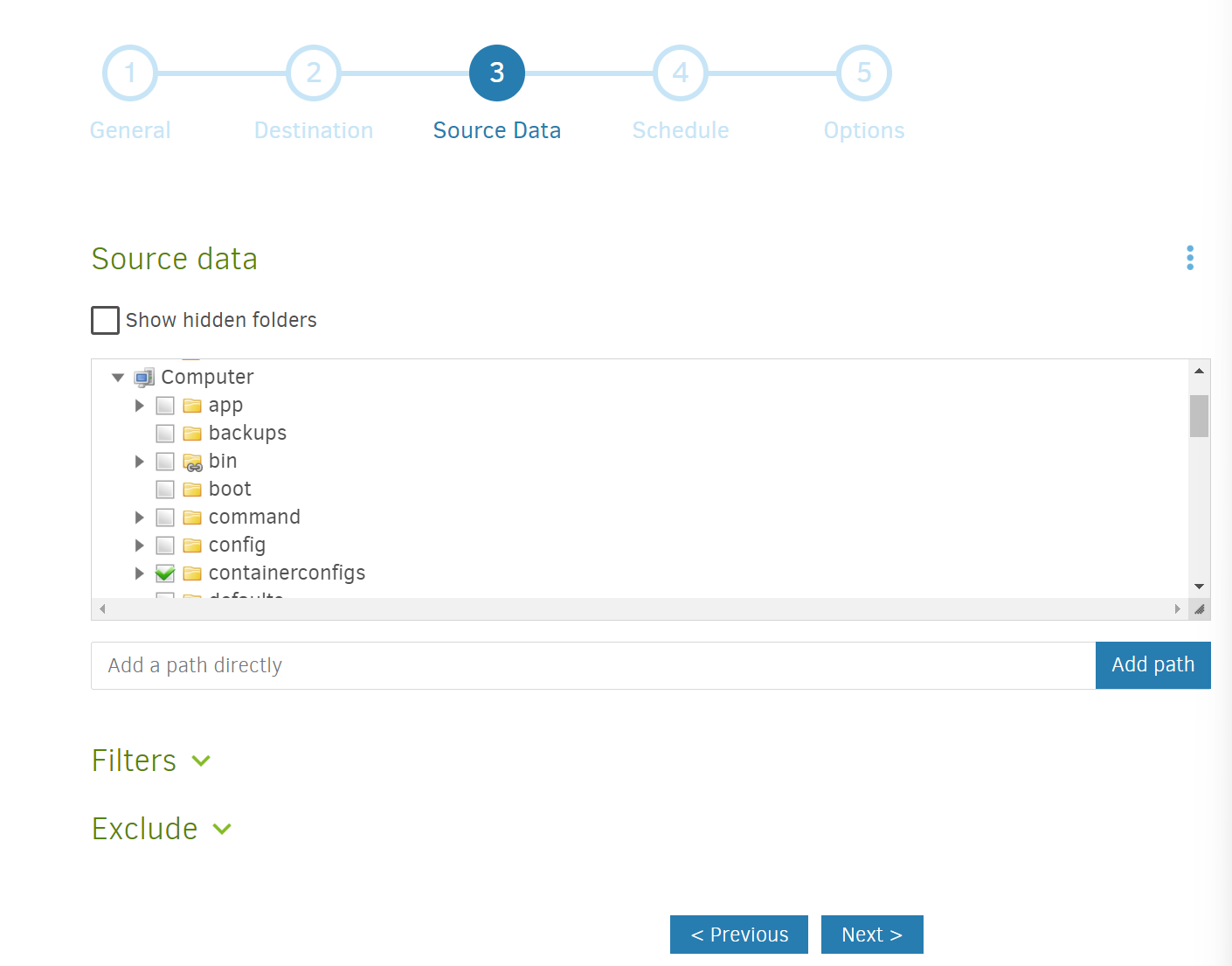
Select the source. Use the folder browsing widget on the interface to select the folder you wish to backup.
If you recall in my configuration step, I mapped the <absolute path to shared config folder> to /containerconfigs which is why I selected this as a one-click way to backup all my Docker container configurations. If necessary, feel free to shut down and delete your current container and start over with a configuration where you point and map the folders in a better way.
Then hit Next
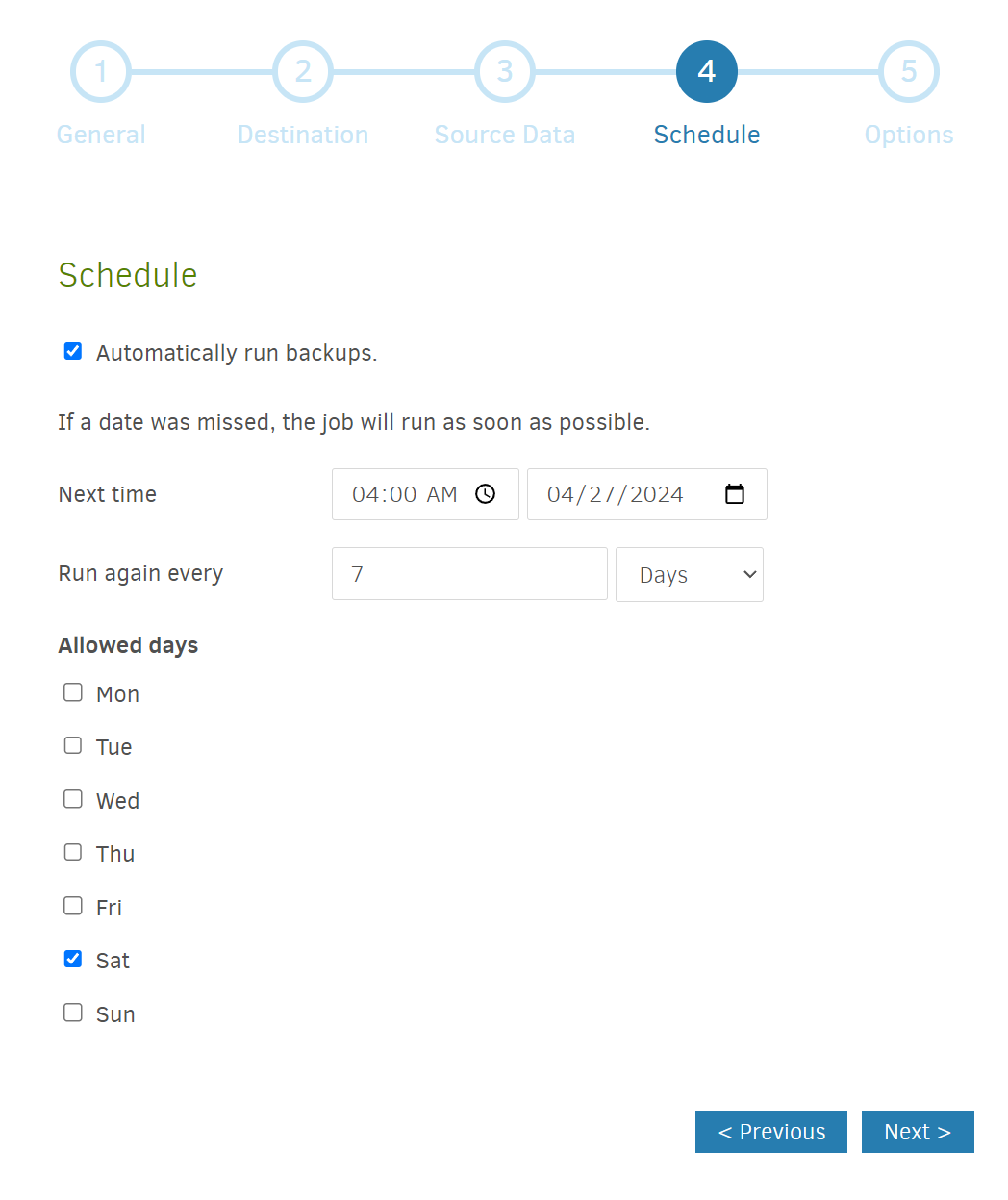
Pick a schedule. Do you want to backup every day? Once a week? Twice a week? Since my docker container configurations don’t change that frequently, I decided to schedule weekly backups on Saturday early morning (so it wouldn’t interfere with something else I might be doing).
Pick your option and then hit Next
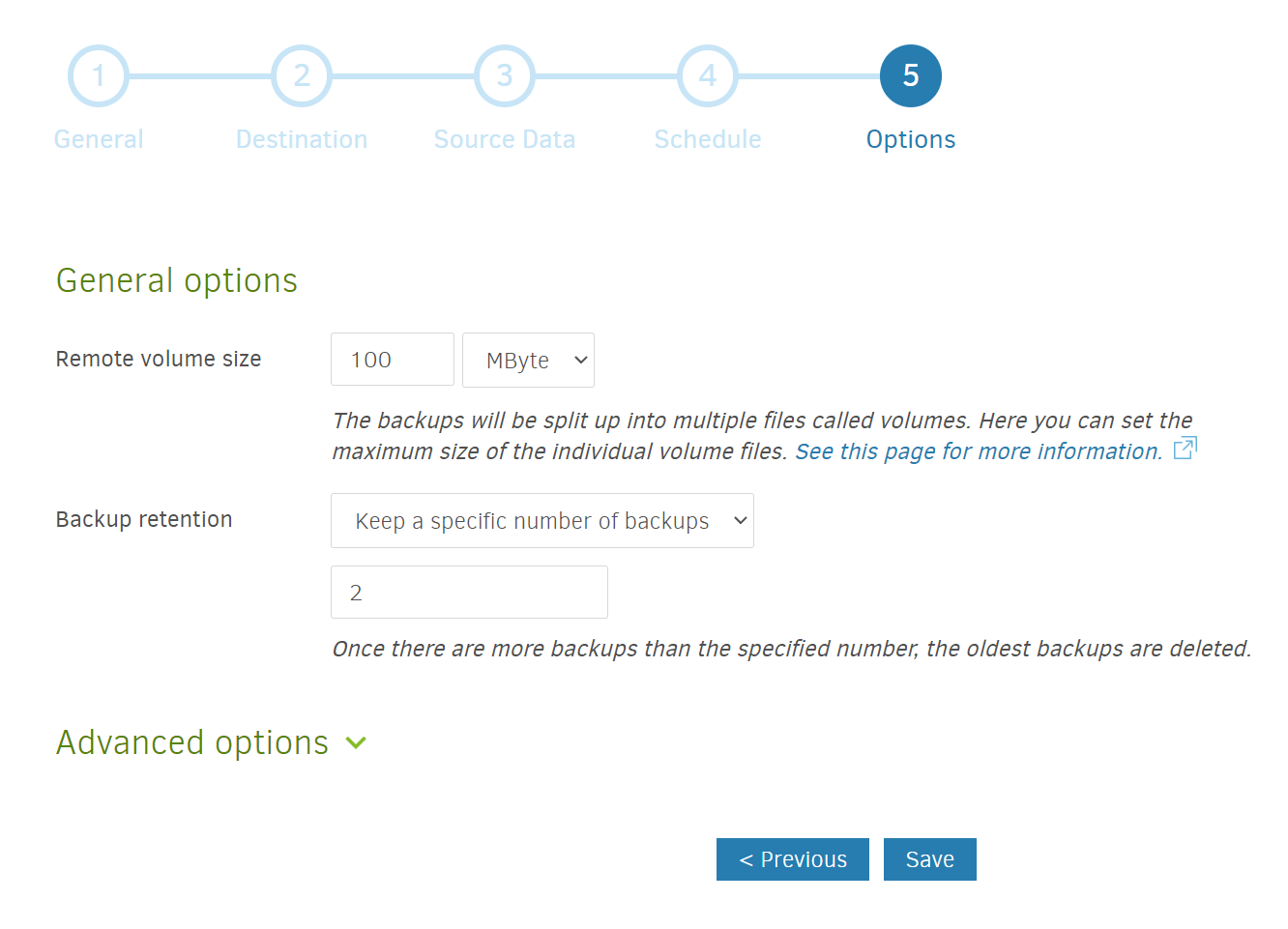
Select your backup options. Unless you have a strong reason to, I would not change the remote volume size from the default (50 MB). The backup retention, however, is something you may want to think about. Duplicati gives you the option to hold on to every backup (something I would not do unless you have a massive amount of storage relative to the amount of data you want to backup), to hold on to backups younger than a certain age, to hold on to a specific number of backups, or customized permutations of the above.
The option you should choose depends on your circumstances, but to share what I did. For some of my most important files, I’m using Duplicati’s smart backup retention option (which gives me one backup from the last week, one for each of the last 4 weeks, and one for each of the last 12 months). For some of my less important files (for example, my docker container configurations), I’m holding on to just the last 2 weeks worth of backups.
Then hit Save and you’re set!
I hope this helps you on your self-hosted backup journey.
It was quite the shock when I discovered recently (HT: Axios Markets newsletter) that, according to NerdWallet, California actually has some of the cheapest homeowners insurance rates in the country!
It begs the Econ 101 question — is it really that the cost of wildfires are too high? Or that the price insurance companies can charge (something heavily regulated by state insurance commissions) is kept too low / not allowed to vary enough based on actual fire risk?
Historically, Intel has (1) designed and (2) manufactured its chips that it sells (primarily into computer and server systems). It prided itself on having the most advanced (1) designs and (2) manufacturing technology, keeping both close to its chest.
In the late 90s/00s, semiconductor companies increasingly embraced the “fabless model”, whereby they would only do the (1) design while outsourcing the manufacturing to foundries like TSMC. This made it much easier and less expensive to build up a burgeoning chip business and is the secret to the success of semiconductor giants like NVIDIA and Qualcomm.
Companies like Intel scoffed at this, arguing that the combination of (1) design and (2) manufacturing gave their products an advantage, one that they used to achieve a dominant position in the computing chip segment. And, it’s an argument which underpins why they have never made a significant effort in becoming a contract manufacturer — after all, if part of your technological magic is the (2) manufacturing, why give it to anyone else?
The success of TSMC has brought a lot of questions about Intel’s advantage in manufacturing and, given recent announcements by Intel and the US’s CHIPS Act, a renewed focus on actually becoming a contract manufacturer to the world’s leading chip designers.
While much of the attention has been paid to the manufacturing prowess rivalry and the geopolitical reasons behind this, I think the real reason Intel has to make the foundry business work is simple: their biggest customers are all becoming chip designers.
While a lot of laptops and desktops and servers are still sold in the traditional fashion, the reality is more and more of the server market is being dominated by a handful of hyperscale data center operators like Amazon, Google, Meta/Facebook, and Microsoft, companies that have historically been able to obtain the best prices from Intel because of their volume. But, in recent years, in the chase for better and better performance and cost and power consumption, they have begun designing their own chips adapted to their own systems (as this latest Google announcement for Google’s own ARM-based server chips shows).
Are these chips as good as Intel’s across every dimension? Almost certainly not. It’s hard to overtake a company like Intel’s decades of design prowess and market insight. But, they don’t have to be. They only have to be better at the specific use case Google / Microsoft / Amazon / etc need it to be for.
And, in that regard, that leaves Intel with really only one option: it has to make the foundry business work, or it risks losing not just the revenue from (1) designing a data center chip, but from the (2) manufacturing as well.
Axion processors combine Google’s silicon expertise with Arm’s highest performing CPU cores to deliver instances with up to 30% better performance than the fastest general-purpose Arm-based instances available in the cloud today, up to 50% better performance and up to 60% better energy-efficiency than comparable current-generation x86-based instances1. That’s why we’ve already started deploying Google services like BigTable, Spanner, BigQuery, Blobstore, Pub/Sub, Google Earth Engine, and the YouTube Ads platform on current generation Arm-based servers and plan to deploy and scale these services and more on Axion soon.
On one level, this shouldn’t be a surprise. Globally always available satellite constellation = everyone and anyone will try to access this. This was, like many technologies, always going to have positive impacts — i.e. people accessing the internet where they otherwise couldn’t due to lack of telecommunications infrastructure or repression — and negative — i.e. terrorists and criminal groups evading communications blackouts.
The question is whether or not SpaceX had the foresight to realize this was a likely outcome and to institute security processes and checks to reduce the likelihood of the negative.
That remains to be seen…
In Yemen, which is in the throes of a decade-long civil war, a government official conceded that Starlink is in widespread use. Many people are prepared to defy competing warring factions, including Houthi rebels, to secure terminals for business and personal communications, and evade the slow, often censored internet service that’s currently available.
Or take Sudan, where a year-long civil war has led to accusations of genocide, crimes against humanity and millions of people fleeing their homes. With the regular internet down for months, soldiers of the paramilitary Rapid Support Forces are among those using the system for their logistics, according to Western diplomats.
One of the most disappointing outcomes in the US from the COVID pandemic was the rise of the antivaxxer / public health skeptic and the dramatic politicization of public health measures.
But, not everything disappointing has stemmed from that. Our lack of cheap rapid tests for diseases like Flu and RSV is a sad reminder of our regulatory system failing to learn from the COVID crisis of the value of cheap, rapid in-home testing or adopting to the new reality that many Americans now know how to do such testing.
Dr. Michael Mina, the chief science officer for the at-home testing company eMed, said the FDA tends to have strict requirements for over-the-counter tests. The agency often asks manufacturers to conduct studies that demonstrate that people can administer at-home tests properly — a process that may cost millions of dollars and delay the test’s authorization by months or years, Mina said.
“It’s taken a very long time in the past to get new self-tests authorized, like HIV tests or even pregnancy tests,” he said. “They’ve taken years and years and years and years. We have a pretty conservative regulatory approach.”
Anyone who’s done any AI work is familiar with Huggingface. They are a repository of trained AI models and maintainer of AI libraries and services that have helped push forward AI research. It is now considered standard practice for research teams with something to boast to publish their models to Huggingface for all to embrace. This culture of open sharing has helped the field make its impressive strides in recent years and helped make Huggingface a “center” in that community.
However, this ease of use and availability of almost every publicly accessible model under the sun comes with a price. Because many AI models require additional assets as well as the execution of code to properly initialize, Huggingface’s own tooling could become a vulnerability. Aware of this, Huggingface has instituted their own security scanning procedures on models they host.
But security researchers at JFrog have found that even with such measures, have identified a number of models that exploit gaps in Huggingface’s scanning which allow for remote code execution. One example model they identified baked into a Pytorch model a “phone home” functionality which would initiate a secure connection between the server running the AI model and another (potentially malicious) computer (seemingly based in Korea).
The JFrog researchers were also able to demonstrate that they could upload models which would allow them to execute other arbitrary Python code which would not be flagged by Huggingface’s security scans.
While I think it’s a long way from suggesting that Huggingface is some kind of security cesspool, the research reminds us that so long as a connected system is both popular and versatile, there will always be the chance for security risk, and it’s important to keep that in mind.
As with other open-source repositories, we’ve been regularly monitoring and scanning AI models uploaded by users, and have discovered a model whose loading leads to code execution, after loading a pickle file. The model’s payload grants the attacker a shell on the compromised machine, enabling them to gain full control over victims’ machines through what is commonly referred to as a “backdoor”. This silent infiltration could potentially grant access to critical internal systems and pave the way for large-scale data breaches or even corporate espionage, impacting not just individual users but potentially entire organizations across the globe, all while leaving victims utterly unaware of their compromised state.
The Dunning-Kruger effect encapsulates something many of us feel familiar with: that the least intelligent oftentimes assume they know more than they actually do. Wrap that sentiment in an academic paper written by two professors at an Ivy League institution and throw in some charts and statistics and you’ve got a easily citable piece of trivia to make yourself feel smarter than the person who you just caught commenting on something they know nothing about.
Well, according to this fascinating blog post (HT: Eric), we have it all wrong. The way that Dunning-Kruger constructed their statistical test was designed to always construct a positive relationship between skill and perceived ability.
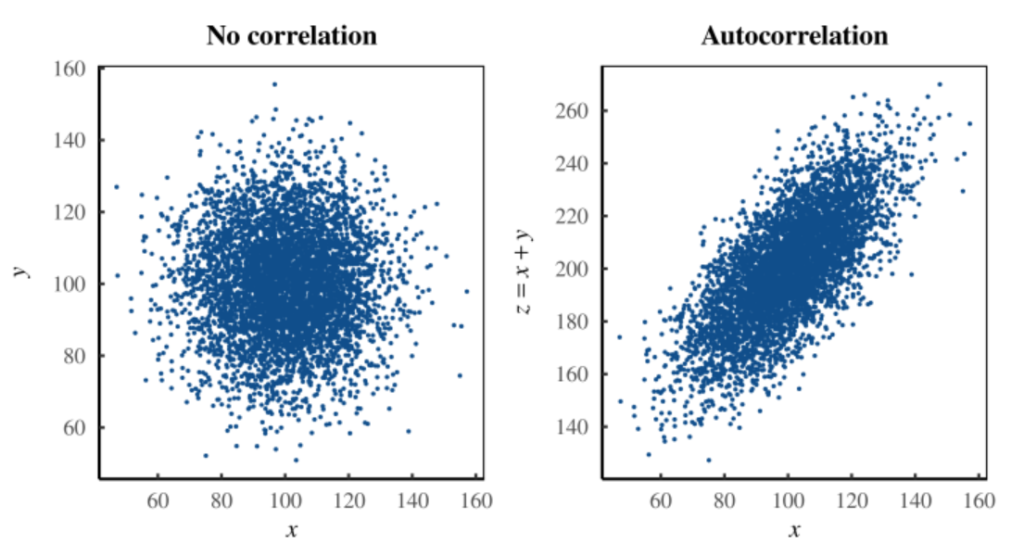
The whole thing is worth a read, but they showed that using completely randomly generated numbers (where there is no relationship between perceived ability and skill), you will always find a relationship between the “skill gap” (perceived ability – skill) and skill, or to put it more plainly,
With y being perceived ability and x being actual measured ability.
What you should be looking for is a relationship between perceived ability and measured ability (or directly between y and x) and when you do this with data, you find that the evidence for such a claim generally isn’t there!
In other words:
The Dunning-Kruger effect also emerges from data in which it shouldn’t. For instance, if you carefully craft random data so that it does not contain a Dunning-Kruger effect, you will still find the effect. The reason turns out to be embarrassingly simple: the Dunning-Kruger effect has nothing to do with human psychology. It is a statistical artifact — a stunning example of autocorrelation.
The human heart is an incredibly sophisticated organ that, in addition to being one of the first organs developed while embryos develop, is quite difficult to understand at a cellular level (where are the cells, how do they first develop, etc.).
Neil Chi’s group at UCSD (link to Nature paper) were able to use multiplex imaging of fluorescent-tagged RNA molecules to profile the gene expression profiles of different types of heart cells and see where they are located and how they develop!
The result is an amazing visualization, check it out at the video:
Until recently, I only knew of the existence of cat(astrophe) bonds — financial instruments used to raise money for insurance against catastrophic events where investors profit when no disaster happens.
I had no idea, until reading this Bloomberg article about the success of Fermat Capital Management, how large the space had gotten ($45 billion!!) or how it was one of the most profitable hedge fund strategies of 2023!
This is becoming an increasingly important intersection between climate change and finance as insurance companies and property owners struggle with the rising risk of rising damage from extreme climate events. Given how young much of the science of evaluating these types of risks is, it’s no surprise that quantitative minds and modelers are able to profit here.
The entire piece reminded me of Richard Zeckhauser’s famous 2006 article Investing in the Unknown and Unknowable which covers how massive investment returns can be realized by tackling problems that seem too difficult for other investors to understand.
Investing in cat bonds was the most profitable hedge fund strategy of 2023. Fermat delivered a 20% return, beating the average 8% achieved by hedge funds as a whole. While other cat bond funds did well too, Fermat’s $10 billion portfolio — capturing a quarter of the market — made it by far the most prolific investor to take advantage of a bumper year.
Cat bonds investors are gambling on nature. If a disaster they’ve bet on occurs, their money is used to settle insurance claims. If it doesn’t, they get handsome returns. For decades, the instruments were a last resort reserved for super-rare events, such as a cataclysmic storm on the scale of Hurricane Katrina. But multibillion-dollar calamities have become alarmingly frequent on a warmer planet.
“The insurance market is on edge,” says Seo. “It’s freaked out about risk and wants as little as possible.”
Maybe you have shopped on Shein or Temu. Maybe you only know someone (younger?) who has. Maybe you only know Temu because of their repeat Superbowl ads.
But these Chinese eCommerce companies are now the main driver behind air and ship cargo rates with Temu and Shein combined accounting for 9,000 tons per day of shipments!
This is scale.
Shein and Temu together send almost 600,000 packages to the United States every day, according to a June 2023 report by the U.S. Congress – is boosting air-freight costs from Asian hubs like Guangzhou and Hong Kong, making off-peak seasons almost disappear and causing capacity shortages, the sources said.
“The biggest trend impacting air freight right now is not the Red Sea, it’s Chinese e-commerce companies like Shein or Temu,” said Basile Ricard, director of Greater China operations at freight forwarder Bollore Logistics
The data centers that power AI and cloud services are limited by 3 things:
the server hardware (oftentimes limited by access to advanced semiconductors)
available space (their footprint is massive which makes it hard to put them close to where people live)
availability of cheap & reliable (and, generally, clean) power
If you, as a data center operator, can tap a new source of cheap & reliable power, you will go very far as you alleviate one of the main constraints on the ability to add to your footprint.
It’s no small wonder, then, that Google is willing to explore partnerships with next-gen geothermal startups like Fervo in a meaningful long-term fashion.
But Google is hoping the road to commercialization for next-generation geothermal will mimic the early days of the tech industry’s solar procurement efforts, Maud Texier, global director of clean energy and decarbonization development, told Latitude Media.
“While there are some important differences between solar and geothermal technologies, we would like to see geothermal power follow a similar trajectory as solar has over the last few decades in terms of rapid cost declines and performance improvements,” Texier said.
Cheap and accurate continuous glucose monitoring is a bit of a holy grail for consumer metabolic health as it allows people to understand how their diet and exercise impact their blood sugar levels, which can vary from person to person.
It’s also a holy grail for diabetes care as making sure blood sugar levels are neither too high nor too low is critical for health (too low and you can pass out or risk seizure or coma; too high and you risk diabetic neuropathy, kidney disease, and cardiovascular problems). For Type I diabetics and severe Type II diabetics, it’s also vital for dosing insulin.
Because insulin dosing needs to be done just right, I was always under the impression that one of two things would happen along the way to producing a cheap continuous glucose monitor, either:
The FDA would be hesitant to approve a device that wasn’t highly accurate to avoid the risk of a consumer using the reading to mis-dose insulin OR
The device makers (like Dexcom) would be hesitant to create an accurate enough glucose monitor that it might cannibalize their highly profitable prescription glucose monitoring business
As a result, I was pleasantly surprised that Dexcom’s over-the-counter Stelo continuous glucose monitor was approved by the FDA. It remains to be seen what the price will be and what level of information the Stelo will share with the customer, but I view this as a positive development and (at least for now) tip my hat to both the FDA and Dexcom here.
Dexcom shared Stelo’s name, and that the device had been submitted to the FDA for review in February. The sensor will be worn on the upper arm and lasts for up to 15 days before it needs to be replaced, according Dexcom.
Jake Leach, chief operating officer at Dexcom, told CNBC in February that Stelo will have a unique platform and branding. The platform will be tailored to the needs of these Type 2 patients, he said, which means it will not include many of the alerts and notifications meant for diabetes patients at risk of experiencing more serious emergencies.
“It’s designed to be a simpler experience,” Leach said in an interview. “There’s a lot of people who could benefit.”
Read an introspective piece by famed ex-Frog Design leader Robert Fabricant about the state of the design industry and the unease that he says many of his peers are feeling. While I disagree with some of the concerns he lays out around AI / diversity being the drivers of this unease, he makes a strong case for how this is a natural pendulum swing after years of seeing “Chief Design Officers” and design innovation groups added to many corporate giants.
I’ve had the privilege of working with very strong designers. This has helped me appreciate the value of design thinking as something that goes far beyond “making things pretty” and believe, wholeheartedly, that it’s something that should be more broadly adopted.
At the same time, it’s also not a surprise to me that during a time of layoffs and cost cutting, a design function which has become a little “spoiled” in the past years and of which calculating financial returns is experiencing some painful transition especially for creative-minded designers who struggle with that ROI evolution.
If Phase 1 was getting companies to recognize that design thinking is needed, Phase 2 will be the space learning how to measure, communicate, and optimize what the value of a team of seasoned designers brings to the bottom line.
In recent years, there has also been a shift in the very nature of design leadership inside companies. Where the early corporate pioneers were in “building mode” to establish and integrate design capabilities, these functions are now focused on optimization. That is where the professionals at IBM and Accenture/Song come in, with creativity giving way to utilization as the primary metric of success, particularly in an economic downturn.
Magowan of Design Leaders is hearing this sentiment from his clients on the hiring side. “Companies are still adjusting,” he says. “Trying to understand how to embed design properly and not make the mistakes they made by hiring folks into design leadership roles who were not equipped.”
This transition is not well-suited to most creative leaders, even proven ones like Powell. “Scaling takes attention,” he says. “But once you get there, then you need to keep turning the dial so that this [design] machine runs more and more efficiently. For me that is where it got to be not as fun.” Perhaps 2024, then, is the right moment for the big handoff to the folks at McKinsey Design to lead the charge armed with their corporate reports and CDO roundtables on business value and design effectiveness?
Nice piece in the Economist about how Costco’s model of operational simplicity leads to a unique position in modern retail: beloved by customers, investors, AND workers:
sell fewer things ➡️
get better prices from suppliers & less inventory needed ➡️
lower costs for customers ➡️
more customers & more willing to pay recurring membership fee ➡️
strong, recurring profits ➡️
ability to pay well and promote from within 📈💪🏻
Customers are not the only fans of Costco, as the outpouring of affection from Wall Street analysts after Mr Galanti announced his retirement on February 6th made clear. The firm’s share price is 430 times what it was when he took the job nearly four decades ago, compared with 25 times for the s&p 500 index of large companies. It has continued to outperform the market in recent years.