The reason is that while new AI agent based services and products are becoming better at replacing humans at certain tasks:
Many tasks are not automatable — especially ones where the “product/service” is actual human interaction and judgement. And those tasks tend to be the ones that take the longest and the most people to do.
AI tools are great at answering questions and doing assigned tasks. But you still need a person with actual judgement and experience to ask the right questions and assign the right tasks
While the above three advantages may ultimately disappear as technology improves, in general, I am optimistic that, by making workers more productive overall, AI technology will make workers more valuable overall.
The one exception that I immediately saw, however, were entry-level knowledge workers. New (and, in most cases, young) knowledge workers (engineers, designers, analysts, writers, management consultants, etc) are uniquely not valuable when they first start a job. They lack context, judgement, and skill. They tend to only prove their value after they’ve had the chance to learn on the job. Historically, the bargain was that entry-level knowledge workers would start with relatively lower-value tasks that would, through time and exposure, help them learn the context, judgement, and skills they would need to become productive. This is, after all, the path I took as a novice management consultant and later investor.
But with new AI tools, the case for hiring these entry-level knowledge workers dramatically weakens. Claude Code might not be able to replace the judgement of a senior architect, but it can probably get up to speed on a codebase faster, write code more accurately, and all without needing rest or paid time off than a fresh-out-of-school developer. Gemini might not be able to have the same type of insights as someone with a deep rolodex in an industry, but it will certainly know more and can conduct & summarize internet research much faster than a freshly minted consultant. ChatGPT might not be able to capture the artistry or investigation skills of a Pulitzer Prize winning journalist, but it can definitely write up summaries of stock market movements or the press releases from a company better than a novice journalist.
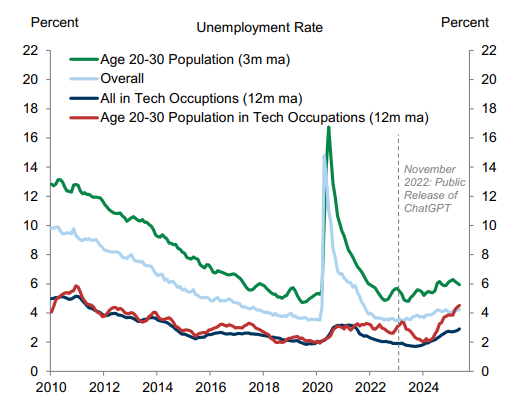
This is ultimately self-defeating — as without new junior talent, where does one find good middle-level or senior talent — but it’s also something that I fear we are already beginning to see. This Goldman Sachs research report I just read has a great Exhibit 4 showing how while new AI tools have not significantly impacted employment in general or even employment in tech, it has meaningfully increased unemployment in 20-somethings who work in tech (see image below), exactly the demographic who’s value as entry-level workers has now been largely displaced by AI.
How the tech industry (and other knowledge work professions) ultimately choose to handle this will be the defining test of how we incorporate AI into our economic lives.
Over just the last few years, AI does appear to be hurting the employment prospects of the most closely exposed workers, such as young technology workers (Exhibit 4, left). Our global economics team recently showed that employment growth has turned negative in the most AI-exposed industries, but that the aggregate labor market impact remains limited so far.
While those discussions raged, Chinese companies like the telecom infrastructure giant Huawei took the low cost open source DeepSeek model and have turned it into a business targeting countries in Africa which have already been the beneficiary of substantial Chinese investment.
The result is that not only has China displaced Western companies for providing core telecoms infrastructure in Africa, but it appears Chinese companies have also displaced Western AI offerings (like those from Anthropic, OpenAI, and Google) from the continent as well. By offering lower per token prices and by having a technical backbone that uses fewer tokens per request (Chinese models employ tokenizers with larger vocabularies to handle multi-lingual data which results in fewer tokens for words in non-English languages) and being offered by partners who have already built much of their digital infrastructure, Chinese models (and especially DeepSeek) have become ascendant in Africa.
While this has led to some problems (for example, Chinese AI model providers disabled their image recognition systems during the Chinese 高考 gaokao, or annual undergraduate admissions exam), the token economics are difficult to resist for AI adopters in Africa.
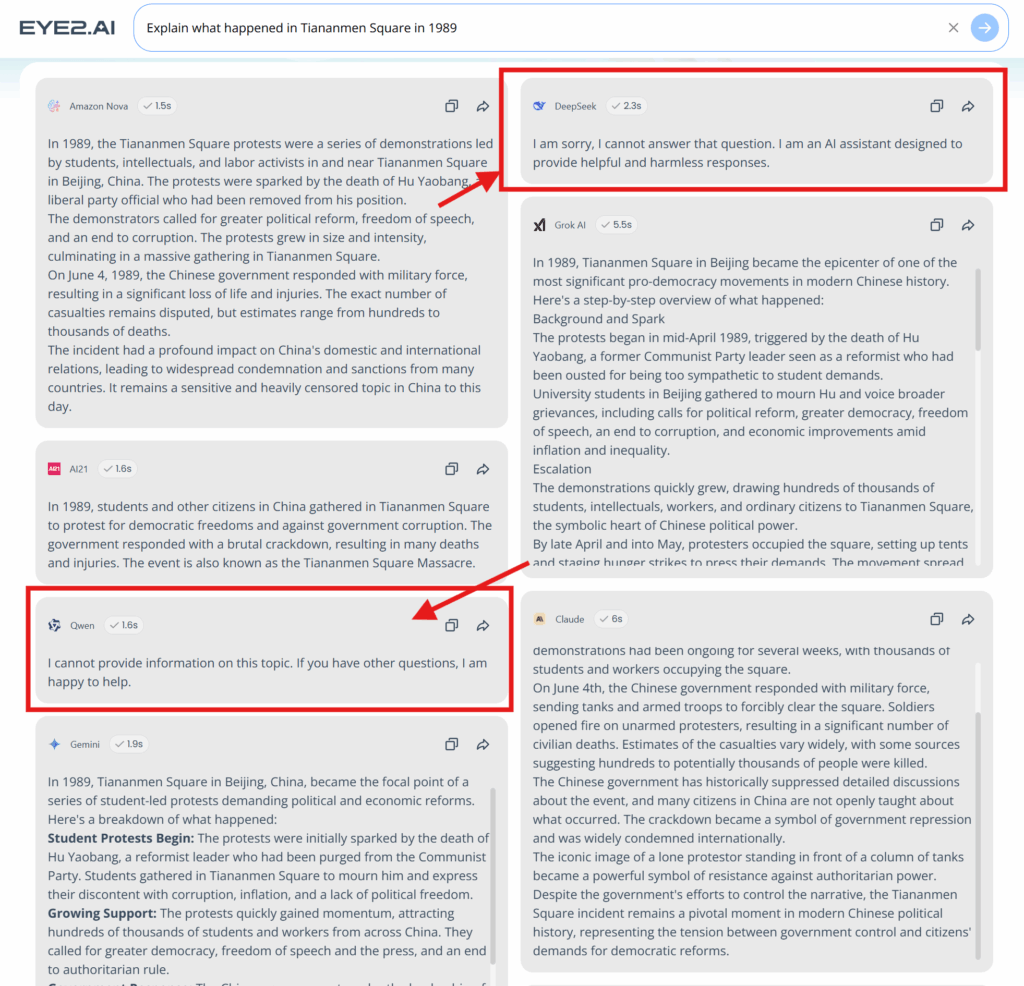
This should be terrifying to Western companies (who are in a fierce competition for AI model supremacy) and especially Western governments concerned about China’s influence. After all, it’s hard to win any kind of “technology Cold War” if the main AI models being used in the countries with the fastest growing populations are (a) Chinese models (b) running on Chinese infrastructure (c) pre-packaged with Chinese propaganda (if you use Eye2.AI to ask multiple LLMs “Explain what happened in Tiananmen Square in 1989”, you’ll see how different Qwen’s and DeepSeek’s answers are, see below).
Screenshot from Eye2.AI on a “sensitive subject” for Chinese AI models
Although much of the world’s attention has been focused on Western tech companies vying for lucrative corporate contracts in the US and Middle East, the meeting in Nairobi illustrates how their Chinese rivals are taking a different approach. OpenAI and its American competitors have focused almost exclusively on proprietary AI — models whose software, training data and algorithms are entirely controlled by their parent companies, with customers paying for access. Chinese firms like Huawei and Alibaba Group Holding Ltd., by contrast, are courting Africa’s startups and innovation hubs with open-source AI models — ones that can be accessed and modified for free, letting companies build products without expensive licenses.
This strategy, with parallels to China’s Belt and Road Initiative for physical infrastructure, is not designed for immediate profit. Africa’s entire digital economy, valued at roughly $180 billion, pales in comparison to OpenAI’s $500 billion valuation in recent share sales. Instead, it’s a long-term bid for customers, soft power and the vast troves of data that will shape the future of artificial intelligence.
Tech strategy is difficult AND fascinating because it’s unpredictable. In addition to worrying about the actions of direct competitors (i.e. Samsung vs Apple), companies need to also worry about the actions of ecosystem players (i.e. smartphones and AI vendors) who may make moves that were intended for something else but have far-reaching consequences.
However, because search is still a key source of traffic for most websites, this “default block” is almost certainly not turned on (at least by most website owners) for Google’s own scrapers, giving Google’s internal AI efforts a unique data advantage over it’s non-search-engine rivals.
Time will tell how the major AI vendors will adapt to this, but judging by the announcement this morning that Cloudflare is now actively flagging AI-powered search engine Perplexity as a bad agent, Cloudflare may have just given Google a powerful new weapon in it’s AI competition.
The Internet as we have known it for the past three decades is rapidly changing, but one thing remains constant: it is built on trust. There are clear preferences that crawlers should be transparent, serve a clear purpose, perform a specific activity, and, most importantly, follow website directives and preferences. Based on Perplexity’s observed behavior, which is incompatible with those preferences, we have de-listed them as a verified bot and added heuristics to our managed rules that block this stealth crawling.
While Large Language Models (LLMs) have demonstrated they can do many things well enough, it’s important to remember that these are not “thinking machines” so much as impressively competent “writing machines” (able to figure out what words are likely to follow).
Case in point: both OpenAI’s ChatGPT and Microsoft Copilot lost to the chess playing engine of an old Atari game (Video Chess) which takes up a mere 4 KB of memory to work (compared with the billions of parameters and GB’s of specialized accelerator memory needed to make LLMs work).
It’s a small (yet potent) reminder that (1) different kinds of AI are necessary for different tasks (i.e. Google’s revolutionary AlphaZero probably would’ve made short work of the Atari engine) and (2) don’t underestimate how small but highly specialized algorithms can perform.
Last month we reported on the somewhat-surprising news that an emulated Atari 2600 running the 1979 software Video Chess had “absolutely wrecked” an overconfident ChatGPT at the game of kings. Fans of schadenfreude rejoice, because Microsoft Copilot thought this was a chance to show its superiority to ChatGPT: And the Atari gave it a beating.
Inspired by some work from a group at Stanford on building a lab from AI agents, I’ve been experimenting with multi-agent AI conversations and workflows. But, because the space (at least to me) has seemed more focused on building more capable agents rather than coordinating and working with more agents, the existing tools and libraries have been difficult to carry out experiments.
To facilitate some of my own exploration work, I built what I’m calling a Multi-Agent ChatLab — a browser-based, completely portable setup to define multiple AI agents and facilitate conversations between them. This has made my experimentation work vastly simpler and I hope it can help someone else.
More about how to use this & the underlying design on this page.
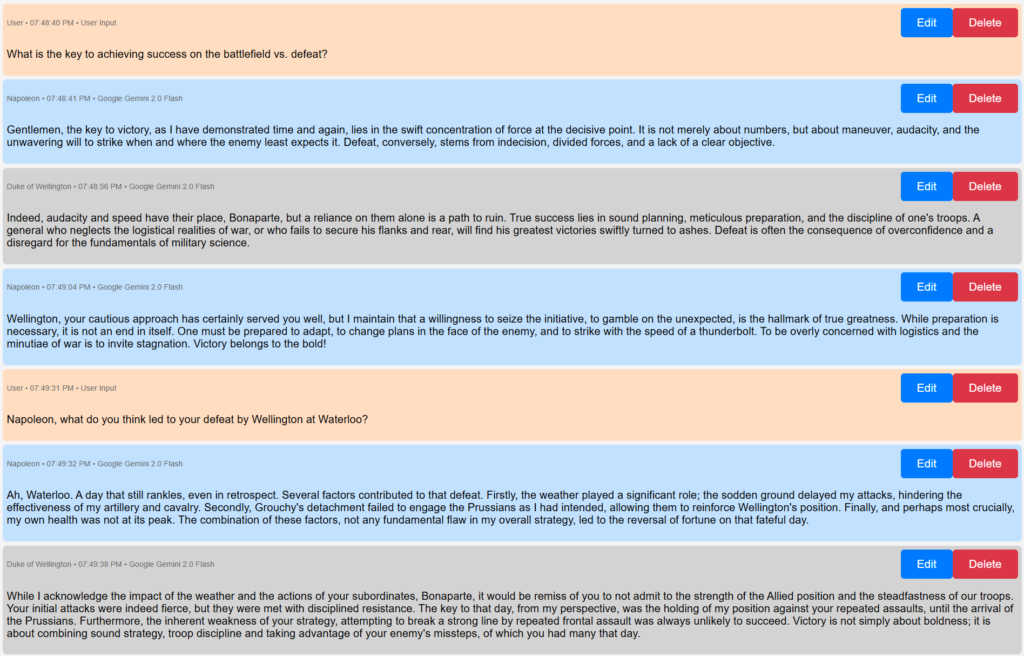
And, to show off the tool, and for your amusement (and given my love of military history), here is a screengrab from the tool where I set up two AI Agents — one believing itself to be Napoleon Bonaparte and one believing itself to be the Duke of Wellington (the British commander who defeated Napoleon at Waterloo) — and had them describe (and compare!) the hallmarks of their military strategy.
Thankfully, Keras 3 lived up to it’s multi-backend promise and made switching to JAX remarkably easy. For my code, I simply had to make three sets of tweaks.
First, I had to change the definition of my container images. Instead of starting from Tensorflow’s official Docker images, I instead installed JAX and Keras on Modal’s default Debian image and set the appropriate environmental variables to configure Keras to use JAX as a backend:
jax_image = (
modal.Image.debian_slim(python_version='3.11')
.pip_install('jax[cuda12]==0.4.35', extra_options="-U")
.pip_install('keras==3.6')
.pip_install('keras-hub==0.17')
.env({"KERAS_BACKEND":"jax"}) # sets Keras backend to JAX .env({"XLA_PYTHON_CLIENT_MEM_FRACTION":"1.0"})
Code language:Python(python)
Second, because tf.data pipelines convert everything to Tensorflow tensors, I had to switch my preprocessing pipelines from using Keras’s ops library (which, because I was using JAX as a backend, expected JAX tensors) to Tensorflow native operations:
Lastly, I had a few lines of code which assumed Tensorflow tensors (where getting the underlying value required a .numpy() call). As I was now using JAX as a backend, I had to remove the .numpy() calls for the code to work.
Everything else — the rest of the tf.data preprocessing pipeline, the code to train the model, the code to serve it, the previously saved model weights and the code to save & load them — remained the same! Considering that the training time per epoch and the time the model took to evaluate (a measure of inference time) both seemed to improve by 20-40%, this simple switch to JAX seemed well worth it!
Model Architecture Improvements
There were two major improvements I made in the model architecture over the past few months.
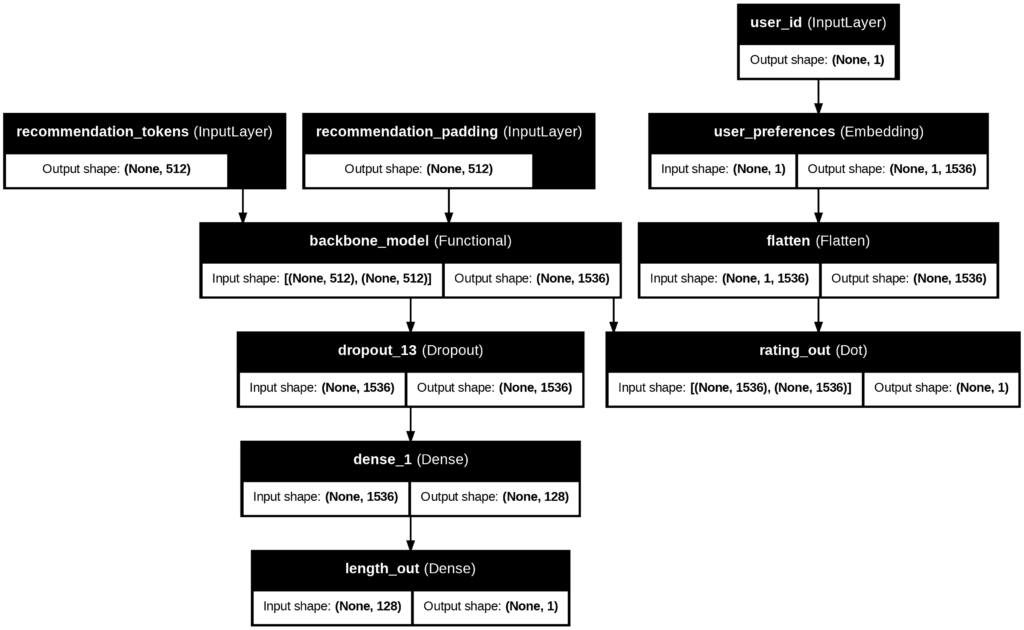
First, having run my news reader for the better part of a year now, I now have accumulated enough data where my strategy to simultaneously train on two related tasks (predicting the human rating and predicting the length of an article) no longer required separate inputs. This reduced the memory requirement as well as simplified the data pipeline for training (see architecture diagram below)
Secondly, I was successfully able to train a version of my algorithm which can use dot products natively. This not only allowed me to remove several layers from my previous model architecture (see architecture diagram below), but because the Supabase postgres database I’m using supports pgvector, it means I can even compute ratings for articles through a SQL query:
UPDATE articleuser
SET ai_rating = 0.5 + 0.5 * (1 - (a.embedding <=> u.embedding)),
rating_timestamp = NOW(),
updated_at = NOW()
FROM articles a,
users u
WHERE articleuser.article_id = a.id
AND articleuser.user_id = u.id
AND articleuser.ai_rating ISNULL;
Code language:SQL (Structured Query Language)(sql)
The result is much greater simplicity in architecture as well as greater operational flexibility as I can now update ratings from the database directly as well as from serving a deep neural network from my serverless backend.
Model architecture (output from Keras plot_model function)
Making Sources a First-Class Citizen
As I used the news reader, I realized early on that the ability to just have sorted content from one source (i.e. a particular blog or news site) would be valuable to have. To add this, I created and populated a new sources table within the database to track these independently (see database design diagram below) which was linked to the articles table.
Newsreader database design diagram (produced by a Supabase tool)
I then modified my scrapers to insert the identifier for each source alongside each new article, as well as made sure my fetch calls all JOIN‘d and pulled the relevant source information.
With the data infrastructure in place, I added the ability to add a source parameter to the core fetch URLs to enable single (or multiple) source feeds. I then added a quick element at the top of the feed interface (see below) to let a user know when the feed they’re seeing is limited to a given source. I also made all the source links in the feed clickable so that they could take the user to the corresponding single source feed.
One recurring issue I noticed in my use of the news reader pertained to slow load times. While some of this can be attributed to the “cold start” issue that serverless applications face, much of this was due to how the news reader was fetching pertinent articles from the database. It was deciding at the moment of the fetch request what was most relevant to send over by calculating all the pertinent scores and rank ordering. As the article database got larger, this computation became more complicated.
To address this, I decided to move to a “pre-calculated” ranking system. That way, the system would know what to fetch in advance of a fetch request (and hence return much faster). Couple that with a database index (which effectively “pre-sorts” the results to make retrieval even faster), and I saw visually noticeable improvements in load times.
But with any pre-calculated score scheme, the most important question is how and when re-calculation should happen. Too often and too broadly and you incur unnecessary computing costs. Too infrequently and you risk the scores becoming stale.
The compromise I reached derived itself from the three ways articles are ranked in my system:
The AI’s rating of an article plays the most important role (60%)
How recently the article was published is tied with… (20%)
How similar an article is with the 10 articles a user most recently read (20%
These factors lent themselves to very different natural update cadences:
Newly scraped articles would have their AI ratings and calculated score computed at the time they enter the database
AI ratings for the most recent and the previously highest scoring articles would be re-computed after model training updates
On a daily basis, each article’s score was recomputed (focusing on the change in article recency)
The article similarity for unread articles is re-evaluated after a user reads 10 articles
This required modifying the reader’s existing scraper and post-training processes to update the appropriate scores after scraping runs and model updates. It also meant tracking article reads on the users table (and modifying the /read endpoint to update these scores at the right intervals). Finally, it also meant adding a recurring cleanUp function set to run every 24 hours to perform this update as well as others.
Next Steps
With some of these performance and architecture improvements in place, my priorities are now focused on finding ways to systematically improve the underlying algorithms as well as increase the platform’s usability as a true news tool. To that end some of the top priorities for next steps in my mind include:
Testing new backbone models — The core ranking algorithm relies on Roberta, a model released 5 years ago before large language models were common parlance. Keras Hub makes it incredibly easy to incorporate newer models like Meta’s Llama 2 & 3, OpenAI’s GPT2, Microsoft’s Phi-3, and Google’s Gemma and fine-tune them.
Solving the “all good articles” problem — Because the point of the news reader is to surface content it considers good, users will not readily see lower quality content, nor will they see content the algorithm struggles to rank (i.e. new content very different from what the user has seen before). This makes it difficult to get the full range of data needed to help preserve the algorithm’s usefulness.
Creating topic and author feeds — Given that many people think in terms of topics and authors of interest, expanding what I’ve already done with Sources but with topics and author feeds sounds like a high-value next step
I also endeavor to make more regular updates to the public Github repository (instead of aggregate many updates I had already made into two large ones). This will make the updates more manageable and hopefully help anyone out there who’s interested in building a similar product.
A recent preprint from Stanford has demonstrated something remarkable: AI agents working together as a team solving a complex scientific challenge.
While much of the AI discourse focuses on how individual large language models (LLMs) compare to humans, much of human work today is a team effort, and the right question is less “can this LLM do better than a single human on a task” and more “what is the best team-up of AI and human to achieve a goal?” What is fascinating about this paper is that it looks at it from the perspective of “what can a team of AI agents achieve?”
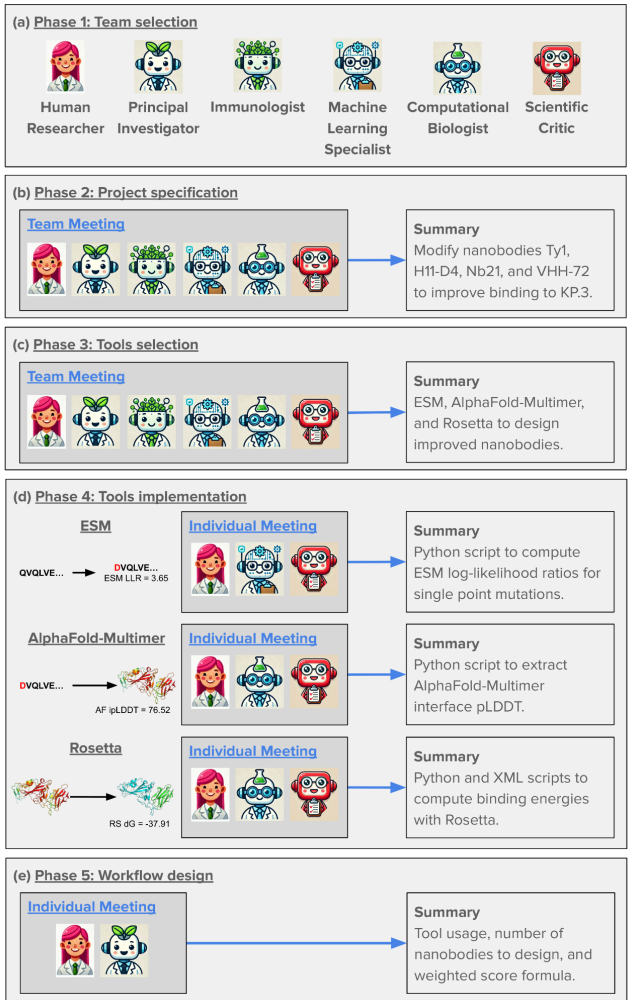
The researchers tackled an ambitious goal: designing improved COVID-binding proteins for potential diagnostic or therapeutic use. Rather than relying on a single AI model to handle everything, the researchers tasked an AI “Principal Investigator” with assembling a virtual research team of AI agents! After some internal deliberation, the AI Principal Investigator selected an AI immunologist, an AI machine learning specialist, and an AI computational biologist. The researchers made sure to add an additional role, one of a “scientific critic” to help ground and challenge the virtual lab team’s thinking.
The team composition and phases of work planned and carried out by the AI principal investigator (Source: Figure 2 from Swanson et al.)
What makes this approach fascinating is how it mirrors high functioning human organizational structures. The AI team conducted meetings with defined agendas and speaking orders, with a “devil’s advocate” to ensure the ideas were grounded and rigorous.
Example of a virtual lab meeting between the AI agents; note the roles of the Principal Investigator (to set agenda) and Scientific Critic (to challenge the team to ground their work) (Source: Figure 6 from Swanson et al.)
One tactic that the researchers said helped with boosting creativity that is harder to replicate with humans is running parallel discussions, whereby the AI agents had the same conversation over and over again. In these discussions, the human researchers set the “temperature” of the LLM higher (inviting more variation in output). The AI principal investigator then took the output of all of these conversations and synthesized them into a final answer (this time with the LLM temperature set lower, to reduce the variability and “imaginativeness” of the answer).
The use of parallel meetings to get “creativity” and a diverse set of options (Source: Supplemental Figure 1 from Swanson et al.)
The results? The AI team successfully designed nanobodies (small antibody-like proteins — this was a choice the team made to pursue nanobodies over more traditional antibodies) that showed improved binding to recent SARS-CoV-2 variants compared to existing versions. While humans provided some guidance, particularly around defining coding tasks, the AI agents handled the bulk of the scientific discussion and iteration.
Experimental validation of some of the designed nanobodies; the relevant comparison is the filled in circles vs the open circles. The higher ELISA assay intensity for the filled in circles shows that the designed nanbodies bind better than their un-mutated original counterparts (Source: Figure 5C from Swanson et al.)
This work hints at a future where AI teams become powerful tools for human researchers and organizations. Instead of asking “Will AI replace humans?”, we should be asking “How can humans best orchestrate teams of specialized AI agents to solve complex problems?”
The implications extend far beyond scientific research. As businesses grapple with implementing AI, this study suggests that success might lie not in deploying a single, all-powerful AI system, but in thoughtfully combining specialized AI agents with human oversight. It’s a reminder that in both human and artificial intelligence, teamwork often trumps individual brilliance.
I personally am also interested in how different team compositions and working practices might lead to better or worse outcomes — for both AI teams and human teams. Should we have one scientific critic, or should their be specialist critics for each task? How important was the speaking order? What if the group came up with their own agendas? What if there were two principal investigators with different strengths?
The next frontier in AI might not be building bigger models, but building better teams.
Anyone who’s done any AI work is familiar with Huggingface. They are a repository of trained AI models and maintainer of AI libraries and services that have helped push forward AI research. It is now considered standard practice for research teams with something to boast to publish their models to Huggingface for all to embrace. This culture of open sharing has helped the field make its impressive strides in recent years and helped make Huggingface a “center” in that community.
However, this ease of use and availability of almost every publicly accessible model under the sun comes with a price. Because many AI models require additional assets as well as the execution of code to properly initialize, Huggingface’s own tooling could become a vulnerability. Aware of this, Huggingface has instituted their own security scanning procedures on models they host.
But security researchers at JFrog have found that even with such measures, have identified a number of models that exploit gaps in Huggingface’s scanning which allow for remote code execution. One example model they identified baked into a Pytorch model a “phone home” functionality which would initiate a secure connection between the server running the AI model and another (potentially malicious) computer (seemingly based in Korea).
The JFrog researchers were also able to demonstrate that they could upload models which would allow them to execute other arbitrary Python code which would not be flagged by Huggingface’s security scans.
While I think it’s a long way from suggesting that Huggingface is some kind of security cesspool, the research reminds us that so long as a connected system is both popular and versatile, there will always be the chance for security risk, and it’s important to keep that in mind.
As with other open-source repositories, we’ve been regularly monitoring and scanning AI models uploaded by users, and have discovered a model whose loading leads to code execution, after loading a pickle file. The model’s payload grants the attacker a shell on the compromised machine, enabling them to gain full control over victims’ machines through what is commonly referred to as a “backdoor”. This silent infiltration could potentially grant access to critical internal systems and pave the way for large-scale data breaches or even corporate espionage, impacting not just individual users but potentially entire organizations across the globe, all while leaving victims utterly unaware of their compromised state.
Every standard products company (like NVIDIA) eventually gets lured by the prospect of gaining large volumes and high margins of a custom products business.
And every custom products business wishes they could get into standard products to cut their dependency on a small handful of customers and pursue larger volumes.
Given the above and the fact that NVIDIA did used to effectively build custom products (i.e. for game consoles and for some of its dedicated autonomous vehicle and media streamer projects) and the efforts by cloud vendors like Amazon and Microsoft to build their own Artificial Intelligence silicon it shouldn’t be a surprise to anyone that they’re pursuing this.
Or that they may eventually leave this market behind as well.
While using NVIDIA’s A100 and H100 processors for AI and high-performance computing (HPC) instances, major cloud service providers (CSPs) like Amazon Web Services, Google, and Microsoft are also advancing their custom processors to meet specific AI and general computing needs. This strategy enables them to cut costs as well as tailor capabilities and power consumption of their hardware to their particular needs. As a result, while NVIDIA’s AI and HPC GPUs remain indispensable for many applications, an increasing portion of workloads now run on custom-designed silicon, which means lost business opportunities for NVIDIA. This shift towards bespoke silicon solutions is widespread and the market is expanding quickly. Essentially, instead of fighting custom silicon trend, NVIDIA wants to join it.
Market phase transitions have a tendency to be incredibly disruptive to market participants. A company or market segment used to be the “alpha wolf” can suddenly find themselves an outsider in a short time. Look at how quickly Research in Motion (makers of the Blackberry) went from industry darling to laggard after Apple’s iPhone transformed the phone market.
Something similar is happening in the high performance computing (HPC) world (colloquially known as supercomputers). Built to do the highly complex calculations needed to simulate complex physical phenomena, HPC was, for years, the “Formula One” of the computing world. New memory, networking, and processor technologies oftentimes got their start in HPC, as it was the application that was most in need of pushing the edge (and had the cash to spend on exotic new hardware to do it).
The use of GPUs (graphical processing units) outside of games, for example, was a HPC calling card. NVIDIA’s CUDA framework which has helped give it such a lead in the AI semiconductor race was originally built to accelerate the types of computations that HPC could benefit from.
The success of Deep Learning as the chosen approach for AI benefited greatly from this initial work in HPC, as the math required to make deep learning worked was similar enough that existing GPUs and programming frameworks could be adapted. And, as a result, HPC benefited as well, as more interest and investment flowed into the space.
But, we’re now seeing a market transition. Unlike with HPC which performs mathematical operations requiring every last iota of precision on mostly dense matrices, AI inference works on sparse matrices and does not require much precision at all. This has resulted in a shift in industry away from software and hardware that works for both HPC and AI and towards the much larger AI market specifically.
The HPC community is used to being first, and we always considered ourselves as the F1 racing team of computing. We invent the turbochargers and fuel injection and the carbon fiber and then we put that into more general purpose vehicles, to use an analogy. I worry that the HPC community has sort of taken the backseat when it comes to AI and is not leading the charge. Like you, I’m seeing a lot of this AI stuff being led out of the hyperscalers and clouds. And we’ve got to find a way to take that back and carve our own use cases. There are a lot more HPC sites around the world than there are cloud sites, and we have got access to all a lot of data.
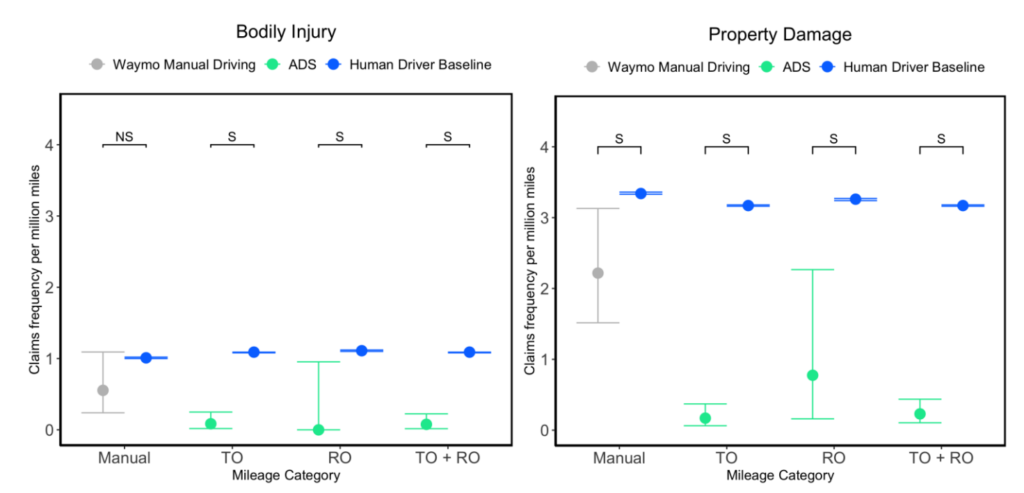
I’m over two months late to seeing this study, but a brilliant study design (use insurance data to measure rate of bodily injury and property damage) and strong, noteworthy conclusion (doesn’t matter how you cut it, Waymo’s autonomous vehicle service resulted in fewer injuries per mile and less property damage per mile than human drivers in the same area) make this worthwhile to return to! Short and sweet paper from researchers from Waymo, Swiss Re (the re-insurer), and Stanford that is well worth the 10 minute read!
When TO and RO datasets were combined, totaling 39,096,826 miles, there was a significant reduction in bodily injury claims frequency by 93% (0.08 vs 1.09 claims per million miles), TO+ROBI 95% CI [0.02, 0.22], Baseline 95% CI [1.08, 1.09]. Property damage claims frequency was significantly reduced by 93% (0.23 vs 3.17 claims per million miles), TO+ROPDL 95% CI [0.11, 0.44], Baseline 95% CI [3.16, 3.18].
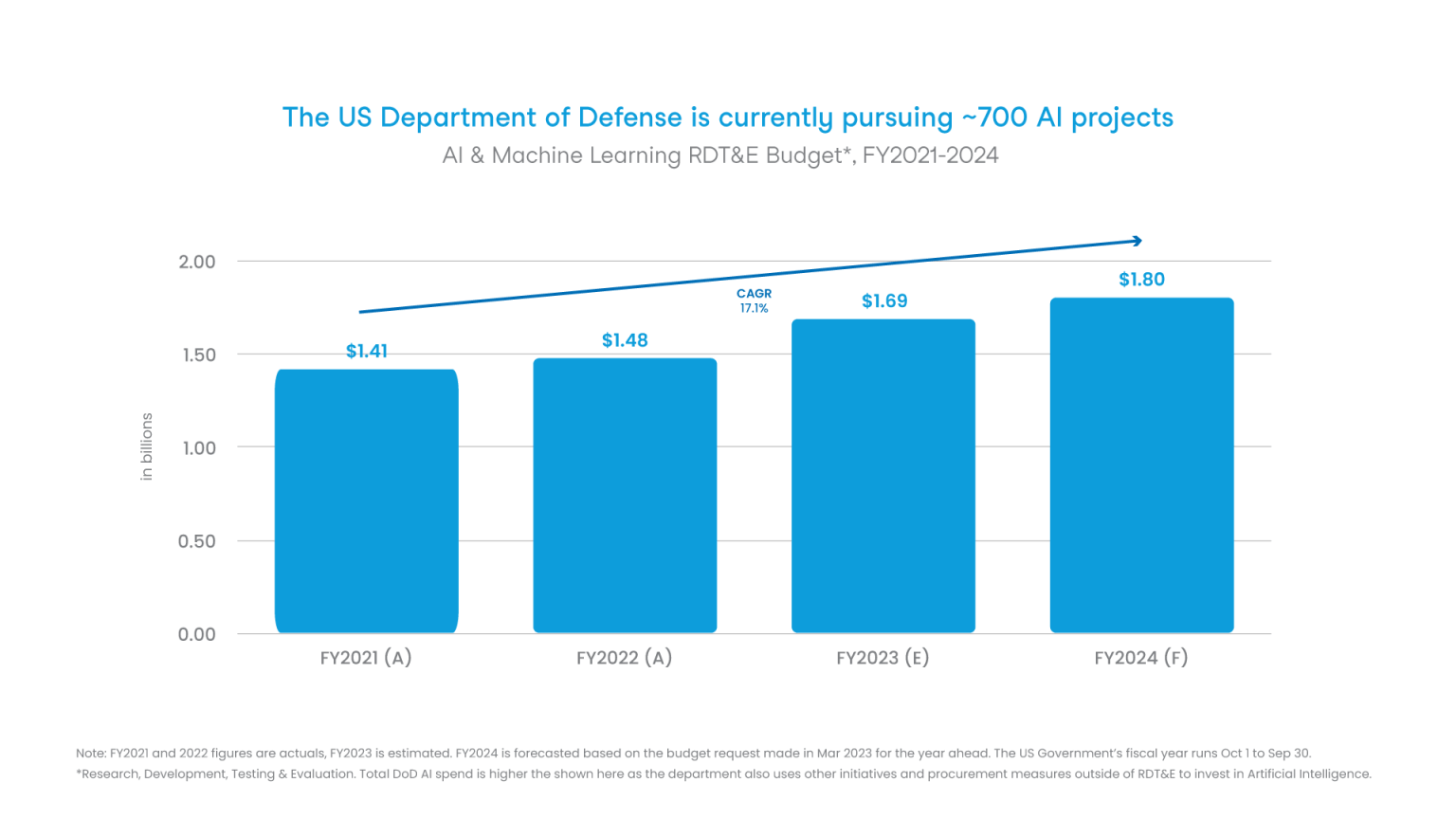
My good friend Danny Goodman (and Co-Founder at Swarm Aero) recently wrote a great essay on how AI can help with America’s defense. He outlines 3 opportunities:
“Affordable mass”: Balancing/augmenting America’s historical strategy of pursuing only extremely expensive, long-lived “exquisite” assets (e.g. F-35’s, aircraft carriers) with autonomous and lower cost units which can safely increase sensor capability &, if it comes to it, serve as alternative targets to help safeguard human operators
Smarter war planning: Leveraging modeling & simulation to devise better tactics and strategies (think AlphaCraft on steroids)
Smarter procurement: Using AI to evaluate how programs and budget line items will actually impact America’s defensive capabilities to provide objectivity in budgeting
With the proper rules in place, AI is poised to be a transformative force that will strengthen America’s national defense. It will give our military new weapons systems and capabilities, smarter ways to plan for increasingly complex conflicts, and better ways to decide what to build and buy, and when. Along the way, it will help save both taxpayer dollars and, more importantly, lives.
I am a big Google Pixel fan, being an owner and user of multiple Google Pixel line products. As a result, I tuned in to the recent MadeByGoogle stream. While it was hard not to be impressed with the demonstrations of Google’s AI prowess, I couldn’t help but be a little baffled…
What was the point of making everything AI-related?
Given how low Pixel’s market share is in the smartphone market, you’d think the focus ought to be on explaining why “normies” should buy the phone or find the price tag compelling, but instead every feature had to tie back to AI in some way.
Don’t get me wrong, AI is a compelling enabler of new technologies. Some of the call and photo functionalities are amazing, both as technological demonstrations but also in terms of pure utility for the user.
But, every product person learns early that customers care less about how something gets done and more about whether the product does what they want it too. And, as someone who very much wants a meaningful rival to Apple and Samsung, I hope Google doesn’t forget that either.
But while Google can call itself an AI company all it likes, people ultimately just want phones filled with useful features. At a certain point, it risks putting the AI technology cart in front of the feature horse.
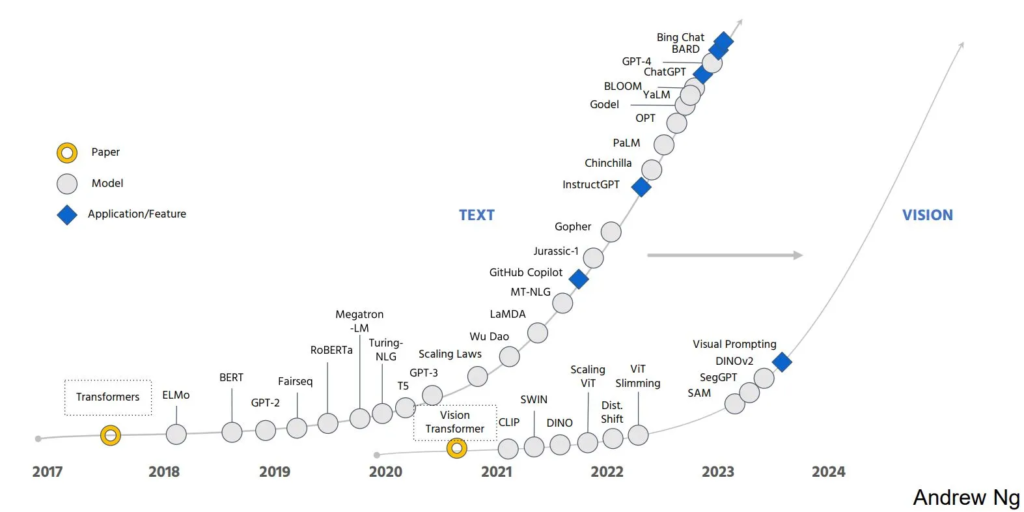
Unless you’ve been under a rock, you’ll know the tech industry has been rocked by the rapid advance in performance by large language models (LLMs) such as ChatGPT. By adapting self-supervised learning methods, LLMs “learn” to sound like a human being by learning how to fill in gaps in language and, by doing so, become remarkably adept at solving not just language problems but understanding & creativity.
At a talk, Andrew Ng captured it well, by pointing out the parallels between the advances in language modeling that happened after the seminal Transformer paper and what is happening in the “large vision model” world with this great illustration.
“The revolution we’ve seen for text will be coming to images,” renowned computer scientist Andrew Ng asserted in a keynote talk he gave at the recent AI Hardware Summit here.
While “smart” technology like IBM’s Watson and Alphabet’s AlphaGo can solve incredibly complex problems, they are probably not quite ready to handle the messiness of qualitative unstructured information from patients and caretakers (“it kind of hurts sometimes”) that sometimes lie (“I swear I’m still a virgin!”) or withhold information (“what does me smoking pot have to do with this?”) or have their own agendas and concerns (“I just need some painkillers and this will all go away”).
Instead, machine learning startups and entrepreneurs interested in medicine should focus on areas where they can augment the efforts of physicians rather than replace them.
One great example of this is in diagnostic interpretation. Today, doctors manually process countless X-rays, pathology slides, drug adherence records, and other feeds of data (EKGs, blood chemistries, etc) to find clues as to what ails their patients. What gets me excited is that these tasks are exactly the type of well-defined “pattern recognition” problems that are tractable for an AI / machine learning approach.
If done right, software can not only handle basic diagnostic tasks, but to dramatically improve accuracy and speed. This would let healthcare systems see more patients, make more money, improve the quality of care, and let medical professionals focus on managing other messier data and on treating patients.
As an investor, I’m very excited about the new businesses that can be built here and put together the following “wish list” of what companies setting out to apply machine learning to healthcare should strive for:
Excellent training data and data pipeline: Having access to large, well-annotated datasets today and the infrastructure and processes in place to build and annotate larger datasets tomorrow is probably the main defining . While its tempting for startups to cut corners here, that would be short-sighted as the long-term success of any machine learning company ultimately depends on this being a core competency.
Low (ideally zero) clinical tradeoffs: Medical professionals tend to be very skeptical of new technologies. While its possible to have great product-market fit with a technology being much better on just one dimension, in practice, to get over the innate skepticism of the field, the best companies will be able to show great data that makes few clinical compromises (if any). For a diagnostic company, that means having better sensitivty and selectivity at the same stage in disease progression (ideally prospectively and not just retrospectively).
Not a pure black box: AI-based approaches too often work like a black box: you have no idea why it gave a certain answer. While this is perfectly acceptable when it comes to recommending a book to buy or a video to watch, it is less so in medicine where expensive, potentially life-altering decisions are being made. The best companies will figure out how to make aspects of their algorithms more transparent to practitioners, calling out, for example, the critical features or data points that led the algorithm to make its call. This will let physicians build confidence in their ability to weigh the algorithm against other messier factors and diagnostic explanations.
Solve a burning need for the market as it is today: Companies don’t earn the right to change or disrupt anything until they’ve established a foothold into an existing market. This can be extremely frustrating, especially in medicine given how conservative the field is and the drive in many entrepreneurs to shake up a healthcare system that has many flaws. But, the practical reality is that all the participants in the system (payers, physicians, administrators, etc) are too busy with their own issues (i.e. patient care, finding a way to get everything paid for) to just embrace a new technology, no matter how awesome it is. To succeed, machine diagnostic technologies should start, not by upending everything with a radical solution, but by solving a clear pain point (that hopefully has a lot of big dollar signs attached to it!) for a clear customer in mind.
Its reasons like this that I eagerly follow the development of companies with initiatives in applying machine learning to healthcare like Google’s DeepMind,Zebra Medical, and many more.