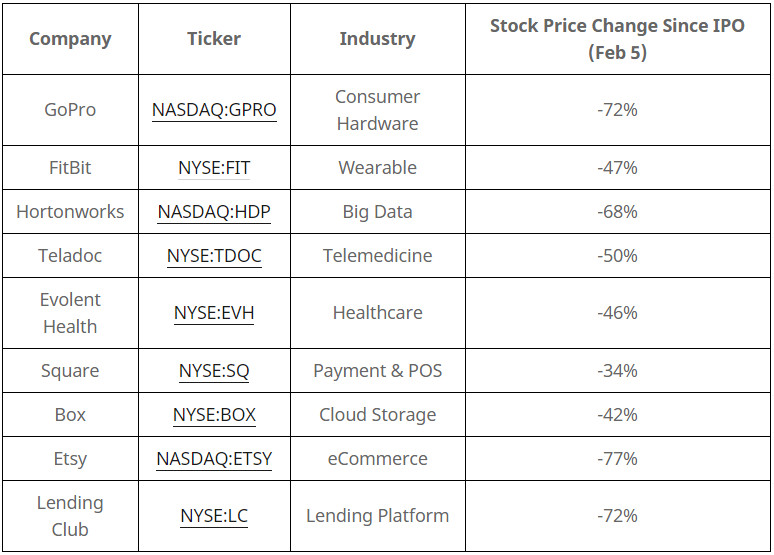
The reason is that while new AI agent based services and products are becoming better at replacing humans at certain tasks:
Many tasks are not automatable — especially ones where the “product/service” is actual human interaction and judgement. And those tasks tend to be the ones that take the longest and the most people to do.
AI tools are great at answering questions and doing assigned tasks. But you still need a person with actual judgement and experience to ask the right questions and assign the right tasks
While the above three advantages may ultimately disappear as technology improves, in general, I am optimistic that, by making workers more productive overall, AI technology will make workers more valuable overall.
The one exception that I immediately saw, however, were entry-level knowledge workers. New (and, in most cases, young) knowledge workers (engineers, designers, analysts, writers, management consultants, etc) are uniquely not valuable when they first start a job. They lack context, judgement, and skill. They tend to only prove their value after they’ve had the chance to learn on the job. Historically, the bargain was that entry-level knowledge workers would start with relatively lower-value tasks that would, through time and exposure, help them learn the context, judgement, and skills they would need to become productive. This is, after all, the path I took as a novice management consultant and later investor.
But with new AI tools, the case for hiring these entry-level knowledge workers dramatically weakens. Claude Code might not be able to replace the judgement of a senior architect, but it can probably get up to speed on a codebase faster, write code more accurately, and all without needing rest or paid time off than a fresh-out-of-school developer. Gemini might not be able to have the same type of insights as someone with a deep rolodex in an industry, but it will certainly know more and can conduct & summarize internet research much faster than a freshly minted consultant. ChatGPT might not be able to capture the artistry or investigation skills of a Pulitzer Prize winning journalist, but it can definitely write up summaries of stock market movements or the press releases from a company better than a novice journalist.
This is ultimately self-defeating — as without new junior talent, where does one find good middle-level or senior talent — but it’s also something that I fear we are already beginning to see. This Goldman Sachs research report I just read has a great Exhibit 4 showing how while new AI tools have not significantly impacted employment in general or even employment in tech, it has meaningfully increased unemployment in 20-somethings who work in tech (see image below), exactly the demographic who’s value as entry-level workers has now been largely displaced by AI.
How the tech industry (and other knowledge work professions) ultimately choose to handle this will be the defining test of how we incorporate AI into our economic lives.
Over just the last few years, AI does appear to be hurting the employment prospects of the most closely exposed workers, such as young technology workers (Exhibit 4, left). Our global economics team recently showed that employment growth has turned negative in the most AI-exposed industries, but that the aggregate labor market impact remains limited so far.
While Large Language Models (LLMs) have demonstrated they can do many things well enough, it’s important to remember that these are not “thinking machines” so much as impressively competent “writing machines” (able to figure out what words are likely to follow).
Case in point: both OpenAI’s ChatGPT and Microsoft Copilot lost to the chess playing engine of an old Atari game (Video Chess) which takes up a mere 4 KB of memory to work (compared with the billions of parameters and GB’s of specialized accelerator memory needed to make LLMs work).
It’s a small (yet potent) reminder that (1) different kinds of AI are necessary for different tasks (i.e. Google’s revolutionary AlphaZero probably would’ve made short work of the Atari engine) and (2) don’t underestimate how small but highly specialized algorithms can perform.
Last month we reported on the somewhat-surprising news that an emulated Atari 2600 running the 1979 software Video Chess had “absolutely wrecked” an overconfident ChatGPT at the game of kings. Fans of schadenfreude rejoice, because Microsoft Copilot thought this was a chance to show its superiority to ChatGPT: And the Atari gave it a beating.
One of the most exciting areas of technology development, but that doesn’t get a ton of mainstream media coverage, is the race to build a working quantum computer that exhibits “below threshold quantum computing” — the ability to do calculations utilizing quantum mechanics accurately.
One of the key limitations to achieving this has been the sensitivity of quantum computing systems — in particular the qubits that capture the superposition of multiple states that allow quantum computers to exploit quantum mechanics for computation — to the world around them. Imagine if your computer’s accuracy would change every time someone walked in the room — even if it was capable of amazing things, it would not be especially practical. As a result, much research to date has been around novel ways of creating physical systems that can protect these quantum states.
Google has (in a pre-print in Nature) demonstrated their new Willow quantum computing chip which demonstrates a quantum error correction method that spreads the quantum state information of a single “logical” qubit across multiple entangled“physical” qubits to create a more robust system. Beyond proving that their quantum error correction method worked, what is most remarkable to me, is that they’re able to extrapolate a scaling law for their error correction — a way of guessing how much better their system is at avoiding loss of quantum state as they increase the number of physical qubits per logical qubit — which could suggest a “scale up” path towards building functional, practical quantum computers.
I will confess that quantum mechanics was never my strong suit (beyond needing it for a class on statistical mechanics eons ago in college), and my understanding of the core physics underlying what they’ve done in the paper is limited, but this is an incredibly exciting feat on our way towards practical quantum computing systems!
The company’s new chip, called Willow, is a larger, improved version of that technology, with 105 physical qubits. It was developed in a fabrication laboratory that Google built at its quantum-computing campus in Santa Barbara, California, in 2021.
As a first demonstration of Willow’s power, the researchers showed that it could perform, in roughly 5 minutes, a task that would take the world’s largest supercomputer an estimated 1025 years, says Hartmut Neven, who heads Google’s quantum-computing division. This is the latest salvo in the race to show that quantum computers have an advantage over classical ones.
And, by creating logical qubits inside Willow, the Google team has shown that each successive increase in the size of a logical qubit cuts the error rate in half.
“This is a very impressive demonstration of solidly being below threshold,” says Barbara Terhal, a specialist in quantum error correction at the Delft University of Technology in the Netherlands. Mikhail Lukin, a physicist at Harvard University in Cambridge, Massachusetts, adds, “It clearly shows that the idea works.”
The rise of Asia as a force to be reckoned with in large scale manufacturing of critical components like batteries, solar panels, pharmaceuticals, chemicals, and semiconductors has left US and European governments seeking to catch up with a bit of a dilemma.
These activities largely moved to Asia because financially-motivated management teams in the West (correctly) recognized that:
they were low return in a conventional financial sense (require tremendous investment and maintenance)
most of these had a heavy labor component (and higher wages in the US/European meant US/European firms were at a cost disadvantage)
these activities tend to benefit from economies of scale and regional industrial ecosystems, so it makes sense for an industry to have fewer and larger suppliers
much of the value was concentrated in design and customer relationship, activities the Western companies would retain
What the companies failed to take into account was the speed at which Asian companies like WuXi, TSMC, Samsung, LG, CATL, Trina, Tongwei, and many others would consolidate (usually with government support), ultimately “graduating” into dominant positions with real market leverage and with the profitability to invest into the higher value activities that were previously the sole domain of Western industry.
Now, scrambling to reposition themselves closer to the forefront in some of these critical industries, these governments have tried to kickstart domestic efforts, only to face the economic realities that led to the outsourcing to begin with.
Northvolt, a major European effort to produce advanced batteries in Europe, is one example of this. Despite raising tremendous private capital and securing European government support, the company filed for bankruptcy a few days ago.
While much hand-wringing is happening in climate-tech circles, I take a different view: this should really not come as a surprise. Battery manufacturing (like semiconductor, solar, pharmaceutical, etc) requires huge amounts of capital and painstaking trial-and-error to perfect operations, just to produce products that are steadily dropping in price over the long-term. It’s fundamentally a difficult and not-very-rewarding endeavor. And it’s for that reason that the West “gave up” on these years ago.
But if US and European industrial policy is to be taken seriously here, the respective governments need to internalize that reality and be committed for the long haul. The idea that what these Asian companies are doing is “easily replicated” is simply not true, and the question is not if but when will the next recipient of government support fall into dire straits.
From the start, Northvolt set out to build something unprecedented. It didn’t just promise to build batteries in Europe, but to create an entire battery ecosystem, from scratch, in a matter of years. It would build the region’s biggest battery factories, develop and source its own materials, and recycle its own batteries. And, with some help from government subsidies, it would do so while matching prices from Asian manufacturers that had dominated global markets.
Northvolt’s ambitious attempt to compress decades of industry development into just eight years culminated last week, with its filing for Chapter 11 bankruptcy protection and the departure of several top executives, including CEO Peter Carlsson. The company’s downfall is a setback for Europe’s battery ambitions — as well as a signal of how challenging it is for the West to challenge Chinese dominance.
As a kid, I remember playing Microsoft Flight Simulator 5.0 — while I can’t say I really understood all the nuances of the several hundred page manual (which explained how ailerons and rudders and elevators worked), I remember being blown away with the idea that I could fly anywhere on the planet and see something reasonably representative there.
Flash forward a few decades and Microsoft Flight Simulator 2024 can safely be said to be one of the most detailed “digital twins” of the whole planet ever built. In addition to detailed photographic mapping of many locations (I would imagine a combination of aerial surveillance and satellite imagery) and an accurate real world inventory of every helipad (including offshore oil rigs!) and glider airport, they also simulate flocks of animals, plane wear and tear, how snow vs mud vs grass behave when you land on it, wake turbulence, and more! And, just as impressive, it’s being streamed from the cloud to your PC/console when you play!
Who said the metaverse is dead?
People are dressed in clothes and styles matching their countries of origin. They speak in the language of their home countries. Flying from the US to Finland on a commercial plane? Walk through the cabin: you’ll hear both English and Finnish being spoken by the passengers.
Neumann, who has a supervising producer credit on 2013’s Zoo Tycoon and a degree in biology, has a soft-spot for animals and wants to make sure they’re also being more realistically simulated in MSFS 2024. “I really didn’t like the implementation of the animal flights in 2020,” he admitted. “It really bothered me, it was like, ‘Hey, find the elephants!’ and there’s a stick in the UI and there’s three sad-looking elephants.
“There’s an open source database that has all wild species, extinct and living, and it has distribution maps with density over time,” Neumann continued. Asobo is drawing from that database to make sure animals are exactly where they’re supposed to be, and that they have the correct population densities. In different locations throughout the year, “you will find different stuff, but also they’re migrating,” so where you spot a herd of wildebeests or caribou one day might not be the same place you find them the next.
Until I read this Verge article, I had assumed that video codecs were a boring affair. In my mind, every few years, the industry would get together and come up with a new standard that promised better compression and better quality for the prevailing formats and screen types and, after some patent licensing back and forth, the industry would standardize around yet another MPEG standard that everyone uses. Rinse and repeat.
The article was an eye-opening look at how video streamers like Netflix are pushing the envelope on using video codecs. Since one of a video streamer’s core costs is the cost of video bandwidth, it would make sense that they would embrace new compression approaches (like different kinds of compression for different content, etc.) to reduce those costs. As Netflix embraces more live streaming content, it seems they’ll need to create new methods to accommodate.
But what jumped out to me the most was that, in order to better test and develop the next generation of codec, they produced a real 12 minute noir film called Meridian (you can access it on Netflix, below is someone who uploaded it to YouTube) which presents scenes that have historically been more difficult to encode with conventional video codecs (extreme lights and shadows, cigar smoke and water, rapidly changing light balance, etc).
Absolutely wild.
While contributing to the development of new video codecs, Aaron and her team stumbled across another pitfall: video engineers across the industry have been relying on a relatively small corpus of freely available video clips to train and test their codecs and algorithms, and most of those clips didn’t look at all like your typical Netflix show. “The content that they were using that was open was not really tailored to the type of content we were streaming,” recalled Aaron. “So, we created content specifically for testing in the industry.”
In 2016, Netflix released a 12-minute 4K HDR short film called Meridian that was supposed to remedy this. Meridian looks like a film noir crime story, complete with shots in a dusty office with a fan in the background, a cloudy beach scene with glistening water, and a dark dream sequence that’s full of contrasts. Each of these shots has been crafted for video encoding challenges, and the entire film has been released under a Creative Commons license. The film has since been used by the Fraunhofer Institute and others to evaluate codecs, and its release has been hailed by the Creative Commons foundation as a prime example of “a spirit of cooperation that creates better technical standards.”
Historically, Intel has (1) designed and (2) manufactured its chips that it sells (primarily into computer and server systems). It prided itself on having the most advanced (1) designs and (2) manufacturing technology, keeping both close to its chest.
In the late 90s/00s, semiconductor companies increasingly embraced the “fabless model”, whereby they would only do the (1) design while outsourcing the manufacturing to foundries like TSMC. This made it much easier and less expensive to build up a burgeoning chip business and is the secret to the success of semiconductor giants like NVIDIA and Qualcomm.
Companies like Intel scoffed at this, arguing that the combination of (1) design and (2) manufacturing gave their products an advantage, one that they used to achieve a dominant position in the computing chip segment. And, it’s an argument which underpins why they have never made a significant effort in becoming a contract manufacturer — after all, if part of your technological magic is the (2) manufacturing, why give it to anyone else?
The success of TSMC has brought a lot of questions about Intel’s advantage in manufacturing and, given recent announcements by Intel and the US’s CHIPS Act, a renewed focus on actually becoming a contract manufacturer to the world’s leading chip designers.
While much of the attention has been paid to the manufacturing prowess rivalry and the geopolitical reasons behind this, I think the real reason Intel has to make the foundry business work is simple: their biggest customers are all becoming chip designers.
While a lot of laptops and desktops and servers are still sold in the traditional fashion, the reality is more and more of the server market is being dominated by a handful of hyperscale data center operators like Amazon, Google, Meta/Facebook, and Microsoft, companies that have historically been able to obtain the best prices from Intel because of their volume. But, in recent years, in the chase for better and better performance and cost and power consumption, they have begun designing their own chips adapted to their own systems (as this latest Google announcement for Google’s own ARM-based server chips shows).
Are these chips as good as Intel’s across every dimension? Almost certainly not. It’s hard to overtake a company like Intel’s decades of design prowess and market insight. But, they don’t have to be. They only have to be better at the specific use case Google / Microsoft / Amazon / etc need it to be for.
And, in that regard, that leaves Intel with really only one option: it has to make the foundry business work, or it risks losing not just the revenue from (1) designing a data center chip, but from the (2) manufacturing as well.
Axion processors combine Google’s silicon expertise with Arm’s highest performing CPU cores to deliver instances with up to 30% better performance than the fastest general-purpose Arm-based instances available in the cloud today, up to 50% better performance and up to 60% better energy-efficiency than comparable current-generation x86-based instances1. That’s why we’ve already started deploying Google services like BigTable, Spanner, BigQuery, Blobstore, Pub/Sub, Google Earth Engine, and the YouTube Ads platform on current generation Arm-based servers and plan to deploy and scale these services and more on Axion soon.
On one level, this shouldn’t be a surprise. Globally always available satellite constellation = everyone and anyone will try to access this. This was, like many technologies, always going to have positive impacts — i.e. people accessing the internet where they otherwise couldn’t due to lack of telecommunications infrastructure or repression — and negative — i.e. terrorists and criminal groups evading communications blackouts.
The question is whether or not SpaceX had the foresight to realize this was a likely outcome and to institute security processes and checks to reduce the likelihood of the negative.
That remains to be seen…
In Yemen, which is in the throes of a decade-long civil war, a government official conceded that Starlink is in widespread use. Many people are prepared to defy competing warring factions, including Houthi rebels, to secure terminals for business and personal communications, and evade the slow, often censored internet service that’s currently available.
Or take Sudan, where a year-long civil war has led to accusations of genocide, crimes against humanity and millions of people fleeing their homes. With the regular internet down for months, soldiers of the paramilitary Rapid Support Forces are among those using the system for their logistics, according to Western diplomats.
Once upon a time, the hottest thing in chip design was “system-on-a-chip” (SOC). The idea is that you’d get the best cost and performance out of a chip by combining more parts into one piece of silicon. This would result in smaller area (less silicon = less cost) and faster performance (closer parts = faster communication) and resulted in more and more chips integrating more and more things.
While the laws of physics haven’t reversed any of the above, the cost of designing chips that integrate more and more components has gone up sharply. Worse, different types of parts (like on-chip memory and physical/analog componentry) don’t scale down as well as pure logic transistors, making it very difficult to design chips that combine all these pieces.
The rise of new types of packaging technologies, like Intel’s Foveros, Intel’s EMIB, TSMC’s InFO, new ways of separating power delivery from data delivery (backside power delivery), and more, has also made it so that you can more tightly integrate different pieces of silicon and improve their performance and size/cost.
The result is now that many of the most advanced silicon today is built as packages of chiplets rather than as massive SOC projects: a change that has happened over a fairly short period of time.
This interview with IMEC (a semiconductor industry research center)’s head of logic technologies breaks this out…
What we’re doing in CMOS 2.0 is pushing that idea further, with much finer-grained disintegration of functions and stacking of many more dies. A first sign of CMOS 2.0 is the imminent arrival of backside-power-delivery networks. On chips today, all interconnects—both those carrying data and those delivering power—are on the front side of the silicon [above the transistors]. Those two types of interconnect have different functions and different requirements, but they have had to exist in a compromise until now. Backside power moves the power-delivery interconnects to beneath the silicon, essentially turning the die into an active transistor layer which is sandwiched between two interconnect stacks, each stack having a different functionality.
An oldie but a goodie — the story of how the YouTube team, post-Google acquisition, put up a “we won’t support Internet Explorer 6 in the future” message without any permission from anyone. (HT: Eric S)
IE6 had been the bane of our web development team’s existence. At least one to two weeks every major sprint cycle had to be dedicated to fixing new UI that was breaking in IE6. Despite this pain, we were told we had to continue supporting IE6 because our users might be unable to upgrade or might be working at companies that were locked in. IE6 users represented around 18% of our user base at that point. We understood that we could not just drop support for it. However, sitting in that cafeteria, having only slept about a few hours each in the previous days, our compassion for these users had completely eroded away. We began collectively fantasizing about how we could exact our revenge on IE6. One idea rose to the surface that quickly captured everyone’s attention. Instead of outright dropping IE6 support, what if we just threatened to? How would users react? Would they revolt against YouTube? Would they mail death threats to our team like had happened in the past? Or would they suddenly become loud advocates of modern browsers?
Very cool that we’re still finding new things we can control that can be applied to making the lives of people better.
I found that a small, middle-ear muscle called the tensor tympani can be tensed voluntarily, otherwise known as “ear rumbling.”
In studies funded by the National Institute for Health and Care Research (NIHR), we found that about 55% of people could tense the muscle in isolation, and about 80% could do so when yawning.
We believe that some people with neurological disabilities retain control over the tensor tympani, even when they’ve lost almost all other functionality. The muscle also moves physiologically as the eyes move, a fact that presents a further opportunity to track people’s intent or augment how we communicate non-verbally.
The ear isn’t just an auditory input device; it also has the potential to be a complex input and output tool.
Intel has been interested in entering the foundry (semiconductor contract manufacturing) space for a long time. For years, Intel proudly boasted of being at the forefront of semiconductor technology — being first to market with the FinFET and smaller and smaller process geometries.
So it’s interesting how, with the exception of the RibbonFET (the successor to the FinFET), almost all of Intel’s manufacturing technology announcements (see whitepaper) in it’s whitepaper to appeal to prospective foundry customers, all of it’s announcements pertain to packaging / “back end” technologies.
I think it’s both a recognition that they are no longer the furthest ahead in that race, as well as recognition that Moore’s Law scaling has diminishing returns for many applications. Now, a major cost and performance driver is technology that was once considered easily outsourced to low cost assemblers in Asia is now front and center.
IN AN EXCLUSIVE INTERVIEW ahead of an invite-only event today in San Jose, Intel outlined new chip technologies it will offer its foundry customers by sharing a glimpse into its future data-center processors. The advances include more dense logic and a 16-fold increase in the connectivity within 3D-stacked chips, and they will be among the first top-end technologies the company has ever shared with chip architects from other companies.
While much attention is (rightly) focused on the role of TSMC (and its rivals Samsung and Intel) in “leading edge” semiconductor technology, the opportunity at the so-called “lagging edge” — older semiconductor process technologies which continue to be used — is oftentimes completely ignored.
The reality of the foundry model is that fab capacity is expensive to build and so the bulk of the profit made on a given process technology investment is when it’s years old. This is a natural consequence of three things:
Very few semiconductor designers have the R&D budget or the need to be early adopters of the most advanced technologies. (That is primarily relegated to the sexiest advanced CPUs, FPGAs, and GPUs, but ignores the huge bulk of the rest of the semiconductor market)
Because only a small handful of foundries can supply “leading edge” technologies and because new technologies have a “yield ramp” (where the technology goes from low yield to higher as the foundry gets more experience), new process technologies are meaningfully more expensive.
Some products have extremely long lives and need to be supported for decade-plus (i.e. automotive, industrial, and military immediately come to mind)
As a result, it was very rational for GlobalFoundries (formerly AMD’s in-house fab) to abandon producing advanced semiconductor technologies in 2018 to focus on building a profitable business at the lagging edge. Foundries like UMC and SMIC have largely made the same choice.
This means giving up on some opportunities (those that require newer technologies) — as GlobalFoundries is finding recently in areas like communications and data center — but provided you have the service capability and capacity, can still lead to not only a profitable outcome, but one which is still incredibly important to the increasingly strategic semiconductor space.
When GlobalFoundries abandoned development of its 7 nm-class process technology in 2018 and refocused on specialty process technologies, it ceased pathfinding, research, and development of all technologies related to bleeding-edge sub-10nm nodes. At the time, this was the correct (and arguably only) move for the company, which was bleeding money and trailing behind both TSMC and Samsung in the bleeding-edge node race. But in the competitive fab market, that trade-off for reduced investment was going to eventually have consequences further down the road, and it looks like those consequences are finally starting to impact the company. In a recent earnings call, GlobalFoundries disclosed that some of the company’s clients are leaving for other foundries, as they adopt sub-10nm technologies faster than GlobalFoundries expected.
Every standard products company (like NVIDIA) eventually gets lured by the prospect of gaining large volumes and high margins of a custom products business.
And every custom products business wishes they could get into standard products to cut their dependency on a small handful of customers and pursue larger volumes.
Given the above and the fact that NVIDIA did used to effectively build custom products (i.e. for game consoles and for some of its dedicated autonomous vehicle and media streamer projects) and the efforts by cloud vendors like Amazon and Microsoft to build their own Artificial Intelligence silicon it shouldn’t be a surprise to anyone that they’re pursuing this.
Or that they may eventually leave this market behind as well.
While using NVIDIA’s A100 and H100 processors for AI and high-performance computing (HPC) instances, major cloud service providers (CSPs) like Amazon Web Services, Google, and Microsoft are also advancing their custom processors to meet specific AI and general computing needs. This strategy enables them to cut costs as well as tailor capabilities and power consumption of their hardware to their particular needs. As a result, while NVIDIA’s AI and HPC GPUs remain indispensable for many applications, an increasing portion of workloads now run on custom-designed silicon, which means lost business opportunities for NVIDIA. This shift towards bespoke silicon solutions is widespread and the market is expanding quickly. Essentially, instead of fighting custom silicon trend, NVIDIA wants to join it.
While much of the commentary has been about Figma’s rapid rise and InVision’s inability to respond, I saw this post on Twitter/X from one of InVision’s founders Clark Valberg about what happened. The screenshotted message he left is well-worth a read. It is a great (if slightly self-serving / biased) retrospective.
As someone who was a mere bystander during the events (as a newly minted Product Manager working with designers), it felt very true to the moment.
I remember being blown away by how the entire product design community moved to Sketch (from largely Adobe-based solutions) and then, seemingly overnight, from Sketch to Figma.
While it’s fair to criticize the leadership for not seeing web-based design as a place to invest, I think the piece just highlights how because it wasn’t a direct competitor to InDesign (but to Sketch & Adobe XD) and because the idea of web-based wasn’t on anyone’s radar at the time, it became a lethal blind spot for the company. It’s Tech Strategy 101 and perfectly highlights Andy Grove’s old saying: “(in technology,) only the paranoid survive”.
Hey Jason…
“Clark from InVision” here…
I’ve been somewhat removed from the InVision business since transitioning out ~2 years ago, and this is the first time I’ve reacted to the latest news publicly. I’m choosing to do so here because in many ways your post is a full-circle moment for me. MANY (perhaps most) of the underlying philosophies that drove InVision from the very beginning were inspired by my co-founder @BenNadel and I reading and re-reading Getting Real. It was our early-stage hymnal.
Apologies for steam of consciousness rant and admitted inherent bias — I’m a founder after all 🙂
Stop me if you’ve heard this one before… Adoption of a technology is being impeded by too many standards. The solution? A new standard, of course, and before you know it, we now have another new standard to deal with.
The smart home industry needs to figure out how to properly embrace Thread (and Matter). It (or something like it) will be necessary for broader smart home / Internet of Things adoption.
The Thread protocol offers a robust mesh network designed to solve many of the smart home’s biggest problems. But only if everyone can agree on how to use it.
VPN — lets me connect to my storage and media server when I’m outside of my home
Until about a week ago, I had run a Plex media server on my aging (8 years old!) NVIDIA SHIELD TV. While I loved the device, it was starting to show it’s age – it would sometimes overheat and not boot for several days. My home technology setup had also shifted. I bought the SHIELD all those years ago to put Android TV functionality onto my “dumb” TV.
But, about a year ago, I upgraded to a newer Sony TV which had it built-in. Now, the SHIELD felt “extra” and the media server felt increasingly constrained by what it could not do (e.g., slow network access speeds, can only run services that are Android apps, etc.)
I considered buying a high-end consumer NAS from Synology or QNAP (which would have been much simpler!), but decided to build my own to both get better hardware for less money but also as a fun project which would teach me more about servers and let me configure everything to my heart’s content.
If you’re interested in doing something similar, let me walk you through my hardware choices and the steps I took to get to my current home server setup.
Note: on the recommendation of a friend, I’ve since reconfigured how external access works to not rely on a VPN with an open port and Dynamic DNS and instead use Twingate. For more information, refer to my post on Setting Up Pihole, Nginx Proxy, and Twingate with OpenMediaVault
Hardware
I purchased a Beelink EQ12 Mini, a “mini PC” (fits in your hand, power-efficient, but still capable of handling a web browser, office applications, or a media server), during Amazon’s Prime Day sale for just under $200.
While I’m very happy with the choice I made, for those of you contemplating something similar, the exact machine isn’t important. Many of the mini PC brands ultimately produce very similar hardware, and by the time you read this, there will probably be a newer and better product. But, I chose this particular model because:
It was from one of the more reputable Mini PC brands which gave me more confidence in its build quality (and my ability to return it if something went wrong). Other reputable vendors beyond Beelink include Geekom, Minisforum, Chuwi, etc.
It had a USB-C port which helps with futureproofing, and the option to convert this into something else useful if this server experiment doesn’t work out.
It had an Intel CPU. While AMD makes excellent CPUs, the benefit of going with Intel is support for Intel Quick Sync, which allows for hardware accelerated video transcode (converting video and audio streams to different formats and resolutions – so that other devices can play them – without overwhelming the system or needing a beefy graphics card). Many popular media servers support Intel Quick Sync-powered transcode.
It was not a i3/5/7/9 chip. Intel’s higher end chips have names that include “i3” or “i5” or “i7”. Those are generally overkill on performance, power consumption, and price for a simple file and media server. All I needed for my purposes was a lower-end Celeron-type device.
It was the most advanced Intel architecture I could find for ≤$200. While I didn’t need the best performance, there was no reason to avoid more advanced technology. Thankfully, the N100 chip in the EQ12 Mini uses Intel’s 12th Generation Core architecture (Alder Lake). Many of the other mini-PCs at this price range had older (10th and 11th generation) CPUs.
I went with the smallest RAM and onboard storage option. I wasn’t planning on putting much on the included storage (because you want to isolate the operating system for the server away from the data) nor did I expect to tax the computer memory for my use case.
I also considered purchasing a Raspberry Pi, a <$100 low-power device popular with hobbyists, but the lack of transcode and the non-x86 architecture (Raspberry Pi’s use ARM CPUs and won’t be compatible with all server software) pushed me towards an Intel-based mini PC.
In addition to the mini-PC, I also needed:
Storage: a media server / NAS without storage is not very useful. I had a 4 TB USB hard drive (previously connected to my SHIELD TV) which I used here, and I also bought a 4 TB SATA SSD (for ~$150) to mount inside the mini-PC.
Note 1: if you decide to go with OpenMediaVault as I have, install the Linux distribution before you install the SATA drive. The installer (foolishly) tries to install itself to the first drive it finds, so don’t give it any bad options.
Note 2: most Mini PC manufacturers say their systems only support additional drives up to 2 TB. This appears to be mainly the manufacturers being overly conservative. My 4 TB SATA SSD works like a charm.
A USB stick: Most Linux distributions (especially those that power open source NAS solutions) are installed from a bootable USB stick. I used one that was lying around that had 2 GB on it.
Ethernet cables and a “dumb” switch: I use Google Wifi in my home and I wanted to connect both my TV and my new media server to the router in my living room. To do that, I bought a simple Ethernet switch (you don’t need anything fancy because it’s just bridging several devices) and 3 Ethernet cables to tie it all together (one to connect the router to the switch, one to connect the TV to the switch, and one to connect the server to the switch). Depending on your home configuration, you may want something different.
A Monitor & Keyboard: if you decide to go with OpenMediaVault as I have, you’ll only need this during the installation phase as the server itself is controllable through a web interface. So, I used an old keyboard and monitor (that I’ve since given away).
OpenMediaVault
There are a number of open source home server / NAS solutions you can use. But I chose to go with OpenMediaVault because it’s:
built on Debian (a well-supported, widely used flavor of Linux)
Plug the USB stick into the mini PC (and make sure to connect the monitor and keyboard) and then turn the machine on. If it goes to Windows (i.e. it doesn’t boot from your USB stick), you’ll need to restart and go into BIOS (you can usually do this by pressing Delete or F2 or F7 after turning on the machine) to configure the machine to boot from a USB drive.
You should pick a good root password and write it down (it gates administrative access to the machine, and you’ll need it to make some of the changes below).
You can pick pretty much any name you want for the hostname and domain name (it shouldn’t affect anything but it will be what your machine calls itself).
Make sure to select the right drive for installation
And that should be it! After you complete the installation, you will be prompted to enter the root password you created to login.
Unfortunately for me, OpenMediaVault did not recognize my mini PC’s ethernet ports or wireless card. If it detects your network adapter just fine, you can skip this next block of steps. But, if you run into this, select the “does not have network card” option and “minimal setup” options during install. You should still be able to get the end of the process. Then, once the OpenMediaVault operating system installs and reboots:
Login by entering the root password you picked during the installation and make sure your system is plugged in to your router via ethernet. Note: Linux is known to have issues recognizing some wireless cards and it’s considered best practice to run a media server off of Ethernet rather than WiFi.
In the command line, enter omv-firstaid. This is a gateway to a series of commonly used tools to fix an OpenMediaVault install. In this case, select the Configure Network Interface option and say yes to all the IPv4 DHCP options (you can decide if you want to set up IPv6).
Step 2 should fix the issue where OpenMediaVault could not see your internet connection. To prove this, you should try two things:
Enter ping google.com -c 3 in the command line. You should see 3 lines with something like 64 bytes from random-url.blahurl.net showing that your system could reach Google (and thus the internet). If it doesn’t work, try again in a few minutes (sometimes it takes some time for your router to register a new system).
Enter ip addr in the command line. Somewhere on the screen, you should see something that probably looks like inet 192.168.xx.xx/xx. That is your local IP address and it’s a sign that the mini PC has connected to your router.
Now you need to update the Linux operating system so that it knows where to look for updates to Debian. As of this writing, the latest version of OpenMediaVault (6) is based on Debian 11 (codenamed Bullseye), so you may need to replace bullseye with <name of Debian codename that your OpenMediaVault is based on> in the text below if your version is based on a different version of Debian (i.e. Bookworm, Trixie, etc.).
In the command line, enter nano /etc/apt/sources.list. This will let you edit the file that contains all the information on where your Linux operating system will find valid software updates. Enter the text below underneath all the lines that start with # (replacing bullseye with the name of the Debian version that underlies your version of OpenMediaVault if needed).
deb http://deb.debian.org/debian bullseye main deb-src http://deb.debian.org/debian bullseye main deb http://deb.debian.org/debian-security/ bullseye-security main deb-src http://deb.debian.org/debian-security/ bullseye-security main deb http://deb.debian.org/debian bullseye-updates main deb-src http://deb.debian.org/debian bullseye-updates main
Then press Ctrl+X to exit, press Y when asked if you want to save your changes, and finally Enter to confirm that you want to overwrite the existing file.
To prove that this worked, in the command line enter apt-get update and you should see some text fly by that includes some of the URLs you entered into sources.list. Next enter apt-get upgrade -y, and this should install all the updates the system found.
Congratulations, you’ve installed OpenMediaVault!
Setting up the File Server
You should now connect any storage (internal or USB) that you want to use for your server. You can turn off the machine if you need to by pulling the plug, or holding the physical power button down for a few seconds, or by entering shutdown now in the command line. After connecting the storage, turn the system back on.
Once setup is complete, OpenMediaVault can generally be completely controlled and managed from the web. But to do this, you need your server’s local IP address. Log in (if you haven’t already) using the root password you set up during the installation process. Enter ip addr in the command line. Somewhere on the screen, you should see something that looks like inet 192.168.xx.xx/xx. That set of numbers connected by decimal points but before the slash (for example: 192.168.444.23) is your local IP address. Write that down.
Now, go into any other computer connected to the same network (i.e. on WiFi or plugged into the router) as the media server and enter the local IP address you wrote down into the address bar of a browser. If you configured everything correctly, you should see something like this (you may have to change the language to English by clicking on the globe icon in the upper right):
The OpenMediaVault administrative panel login
Congratulations, you no longer need to connect a keyboard or mouse to your server, because you can manage it from any other computer on the network!
Login using the default username admin and default password openmediavault. Below are the key things to do first. (Note: after hitting Save on a major change, as an annoying extra precaution, OpenMediaVault will ask you to confirm the change again with a bright yellow confirmation banner at the top. You can wait until you have several changes, but you need to make sure you hit the check mark at least once or your changes won’t be reflected):
Change your password: This panel controls the configuration for your system, so it’s best not to let it be the default. You can do this by clicking on the (user settings) icon in the upper-right and selecting Change Password
Some useful odds & ends:
Make auto logout (time before the panel logs you out automatically) longer. You can do this by going to [System > Workbench] in the menu and changing Auto logout to something like 60 minutes
Set the system timezone. You can do this by going to [System > Date & Time] and changing the Time zone field.
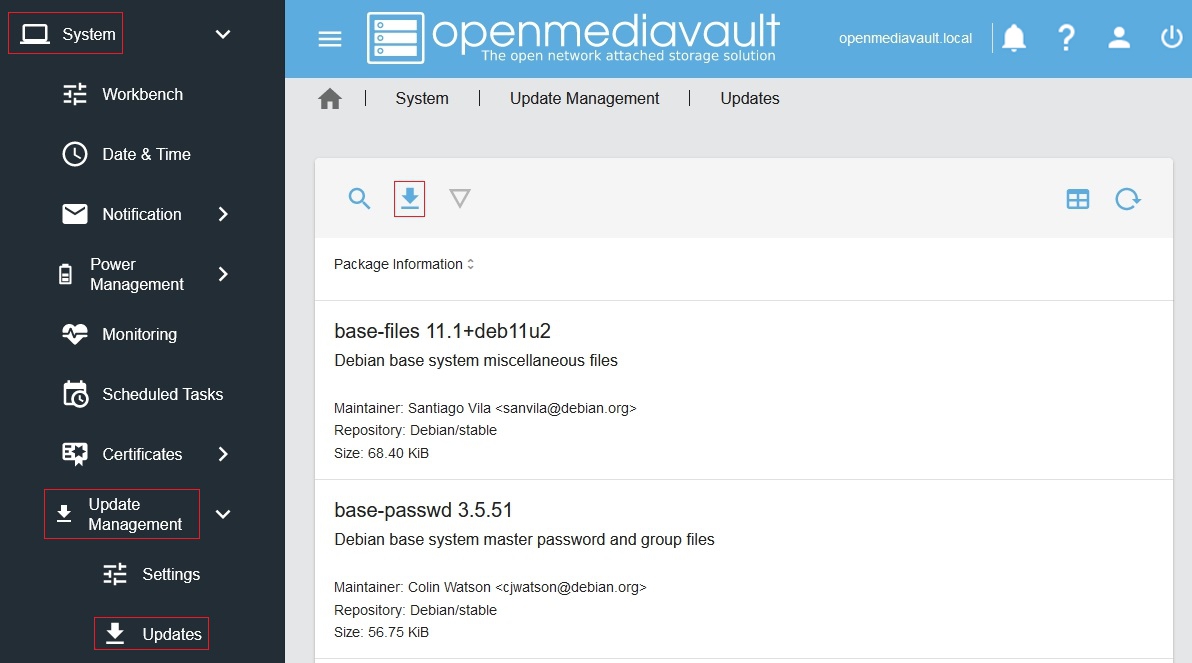
Update the software: On the left-hand side, select [System > Update Management > Updates]. Press the button to search for new updates. If any show up press the button to install everything on the list that it can. (see below, Image credit: OMV-extras Wiki)
Mount your storage:
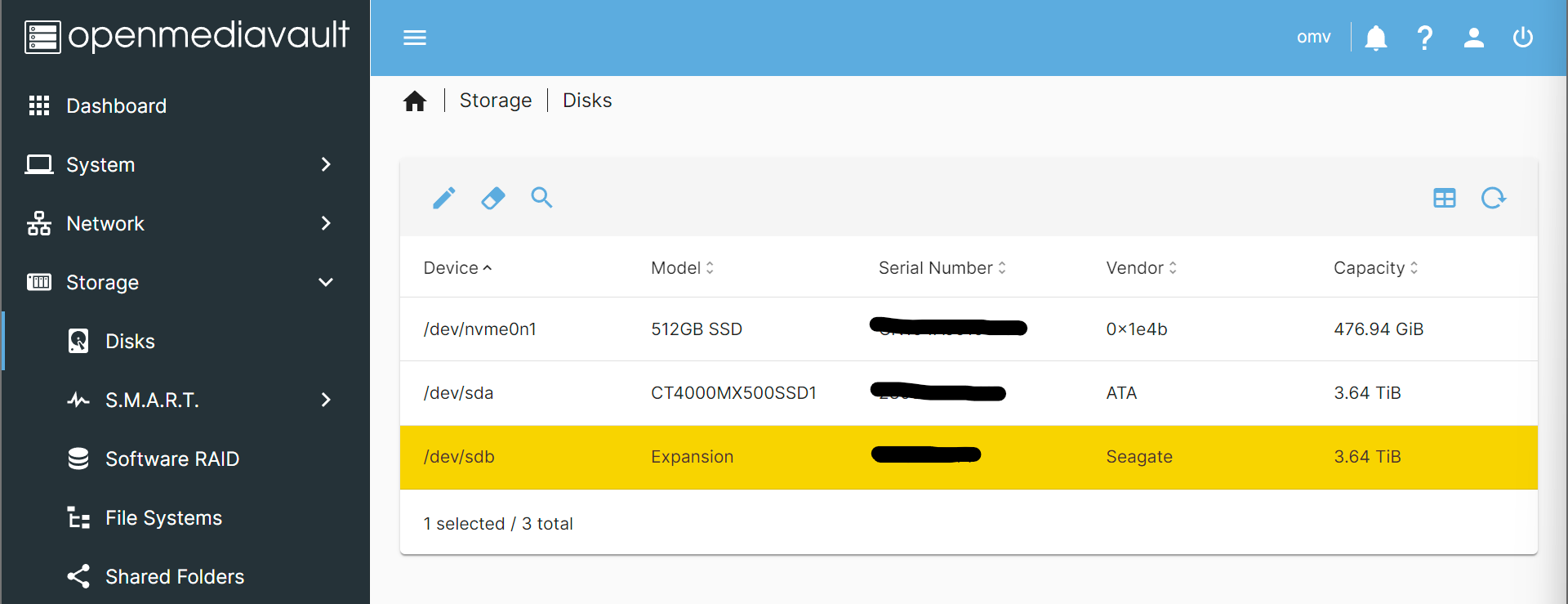
From the menu, select [Storage > Disks]. The table that results (see below) shows everything OpenMediaVault sees connected to your server. If you’re missing anything, time to troubleshoot (check the connection and then make sure the storage works on another computer).
It’s a good idea (although not strictly necessary) to reformat any un-empty disks before using them with OpenMediaVault for performance. You can do this by selecting the disk entry (marking it yellow) and then pressing the (Wipe) button
Go to [Storage > File Systems]. This shows what drives (and what file systems) are accessible to OpenMediaVault. To properly mount your storage:
Press the button for every unformatted drive added you may want to mount to OpenMediaVault. This will add a disk with an existing file system to the purview of your file server.
Press the button in the upper-left (just to the right of the triangular button) to add a drive that’s just been formatted. Of the file system options that come up, I would choose EXT4 (it’s what modern Linux operating systems tend to use). This will result in your chosen file system being added to the drive before it’s ultimately mounted.
Set up your File Server: Ok, you’ve got storage! Now you want to make it available for the computers on your network. To do this, you need to do three things:
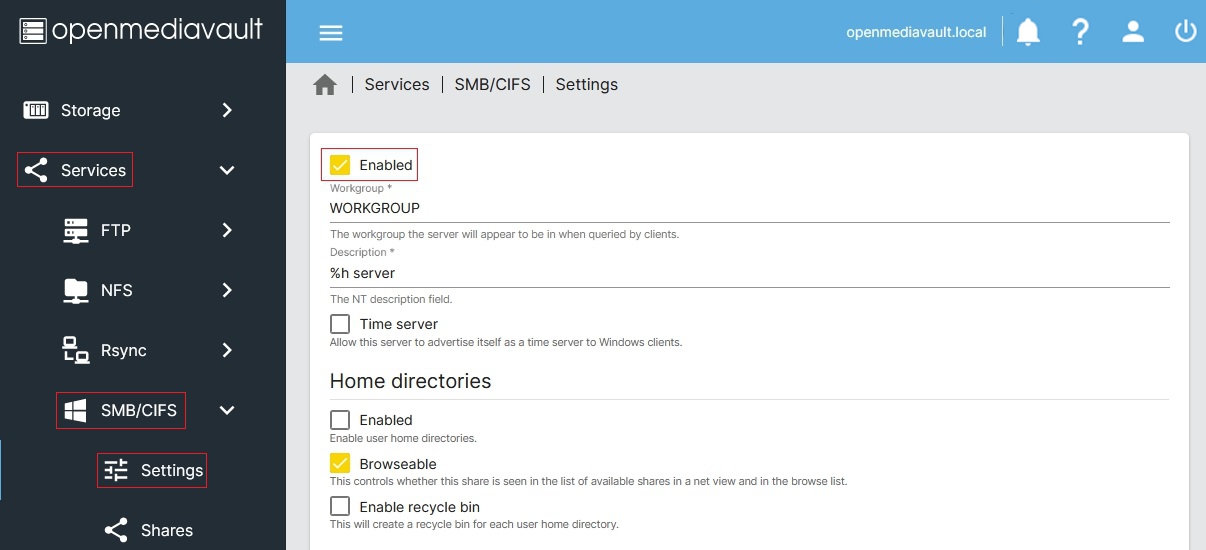
Enabling SMB/CIFS: Windows, Mac OS, and Linux systems tend to work pretty well with SMB/CIFS for network file shares. From the menu, select [Services > SMB/CIFS > Settings].
Check the Enabled box. If your LAN workgroup is something other than the default WORKGROUP you should enter it. Now any device on your network that supports SMB/CIFS will be able to see the folders that OpenMediaVault shares. (see below, Image credit: OMV-extras Wiki)
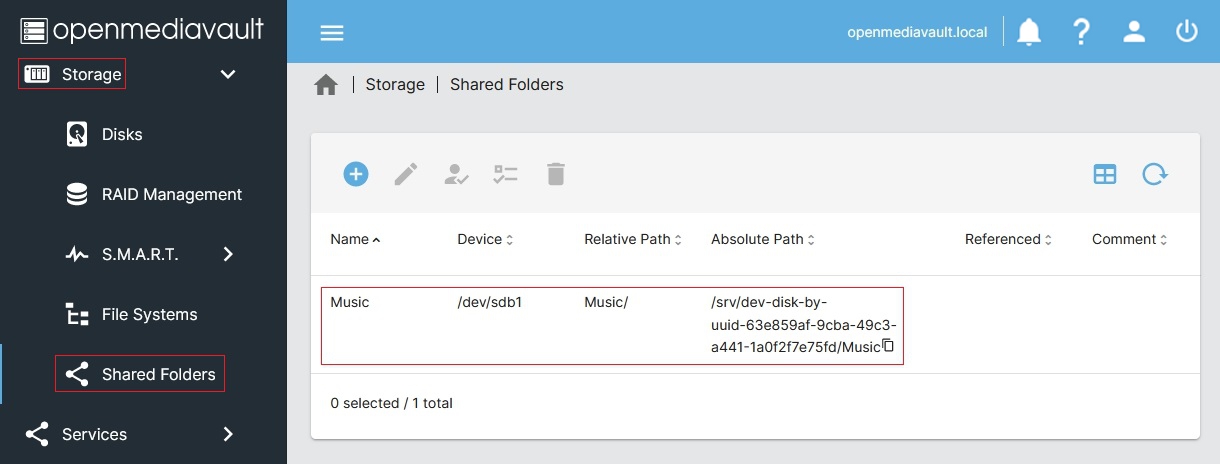
Selecting folders to share: On the left-hand-side of the administrative panel, select [Storage > Shared Folders]. This will list all the folders that can be shared.
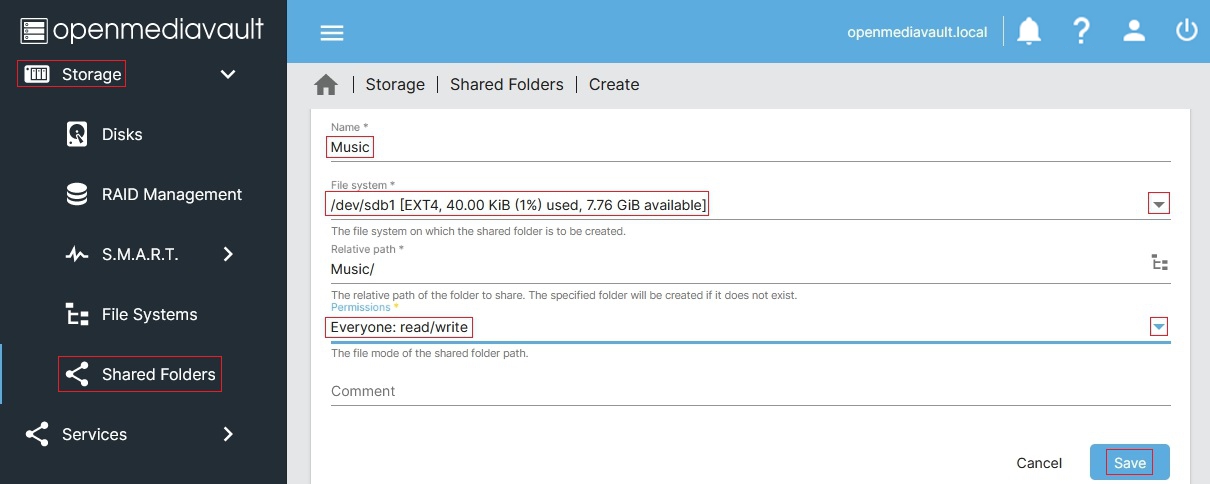
To make a folder available to your network, select the button in the upper-left, and fill out the Name (what you want the folder to be called when other’s access it) and select the File System you’ve previously mounted that the folder will connect to. You can write out the name of the directory you want to share and/or use the directory folder icon to the right of the Relative Path field to help select the right folder. Under Permissions, for simplicity I would assign Everyone: read/write. (see below, Image credit: OMV-extras Wiki)
Hit Save to return to the list of folder shares (see below for what a completed entry looks like, Image credit: OMV-extras Wiki). Repeat the process to add as many Shared Folders as you’d like.
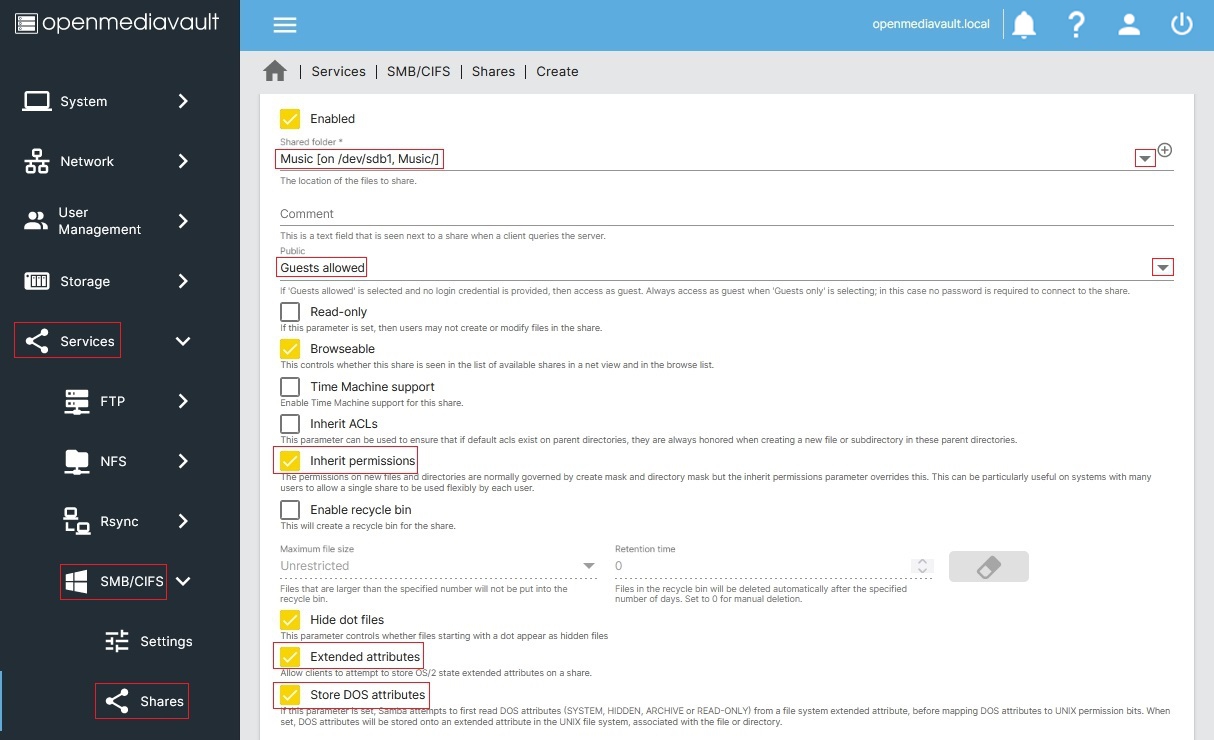
Make the shared folders available to SMB/CIFS: To do this go to [Services > SMB/CIFS > Shares]. Hit the button and, in, Shared Folder, select the Shared Folder you configured from the dropdown. Under Public, select Guests allowed – this will allow users on the network to access the folder without supplying a username or password. Check the Inherit Permissions, Extended attributes, and Store DOS attributes boxes as well and then hit Save. Repeat this for all the shared folders you want to make available. (Image credit: OMV-extras Wiki)
Set a static local IP: Home networks typically dynamically assign IP addresses to the devices on the network (something called DHCP). As a result, the IP address for your server may suddenly change. To give your server a consistent address to connect to, you should configure your router to assign a static IP to your server. The exact instructions will vary by router so you’ll need to consult your router’s documentation. In my household, we use Google Wifi and, if you do too, here are the instructions for doing so. (Make sure to write down the static IP you assign to the server as you will need it later. If you change the IP from what it already was, make sure to log into the OpenMediaVault panel from that new address before proceeding.)
Check that the shared folders show up on your network: Linux, Mac OS, and Windows all have separate ways of mounting a SMB/CIFS file share. The steps above hopefully simplify this by:
letting users connect as a Guest (no extra authentication needed)
Enter containers. Containers are “portable environments” for software, first popularized by the company Docker, that gives software a predictable background to run on. This makes it easier to run applications reliably, regardless of machine (because the application only sees what the container shows it). It also means a greatly reduced risk of a misconfigured app affecting another since the application “lives” in its own container.
While this has tremendous implications for software in general, for our purposes, this just makes it a lot easier to install software … provided you have Docker installed. For OpenMediaVault, the best way to get Docker is to install OMV-extras.
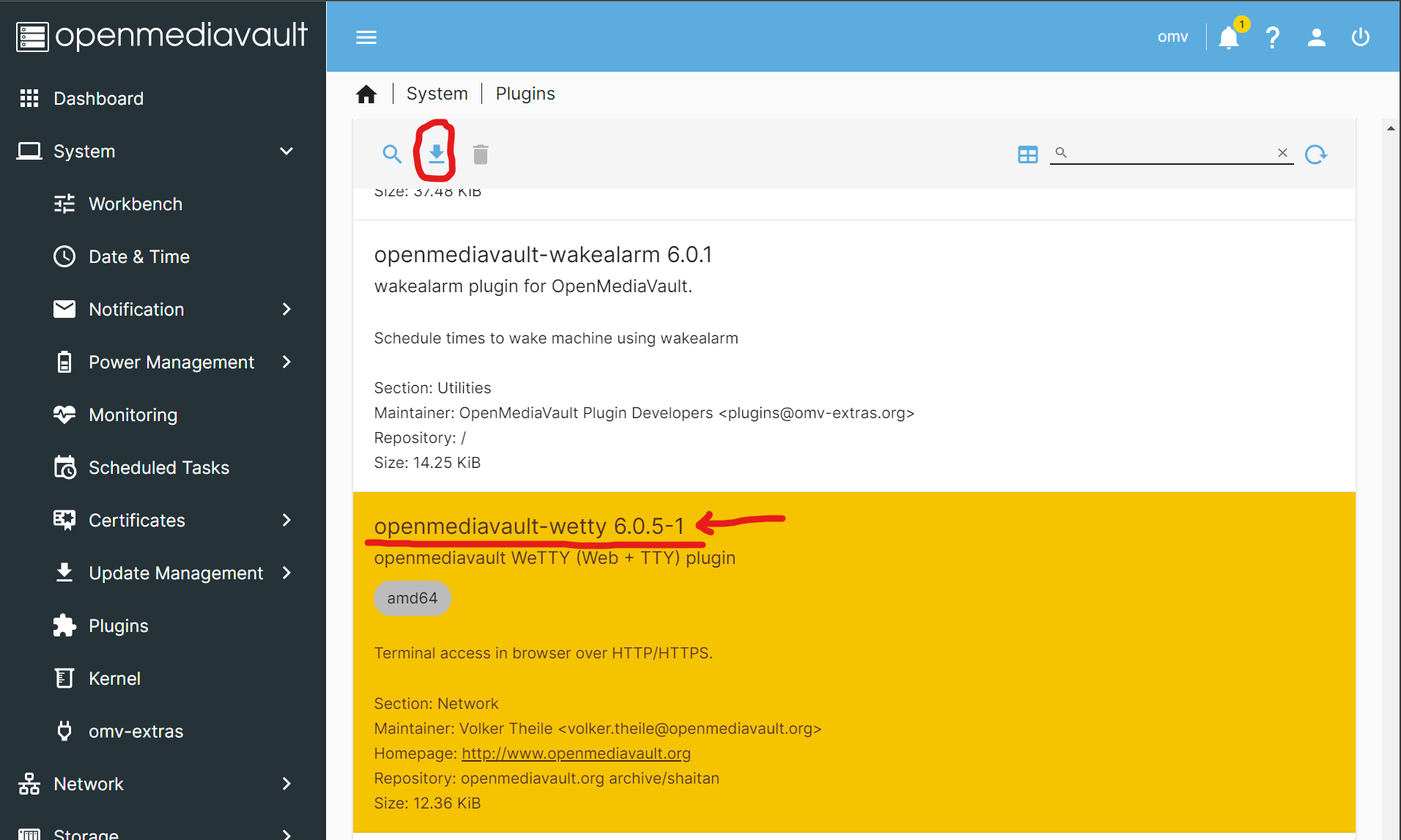
If you know how to use ssh, go ahead and use it to access your server’s IP address, login as the root user, and skip to Step 4. But, if you don’t, the easiest way to proceed is to set up WeTTY (Steps 1-3):
Install WeTTY: Go to [System > Plugins] and search or scroll until you find the row for openmediavault-wetty. Click on it to mark it yellow and then press the button to install it. WeTTY is a web-based terminal which will let you access the server command line from a browser.
Enable WeTTY: Once the install is complete, go to [Services > WeTTY], check the Enabled box, and hit Save. You’ll be prompted by OpenMediaVault to confirm the pending change.
Press Open UIbutton on the page to access WeTTY: It should open up a new tab that takes you to your-ip-address:2222 which should open up a black screen which is basically the command line for your server! Enter root when prompted for your username and then your root password that you configured during installation.
Installation will take a while but once it’s complete, you can verify it by going back to your administrative panel, refreshing the page, and seeing if there is a new menu item [System > omv-extras].
Enable the Docker repo: From the administrative panel, go to [System > omv-extras] and check the Docker repo box. Press the apt clean button once you have.
Install the Docker-compose plugin: Go to [System > Plugins] and search or scroll down until you find the entry for openmediavault-compose. Click on it to mark it yellow and then press the button on the upper-left to install it. To confirm that it’s been installed, you should see a new menu item [Services > Compose]
Update the System: As before, select [System > Update Management > Updates]. Press the button to search for new updates. Press the button which will automatically install everything.
Create three shared folders: compose, containers, and config: Just as with setting up the network folder shares, you can do this by going to [Storage > Shared Folders] and pressing the button in the upper left. You can generally pick any location you’d like, but make sure it’s on a file system with a decent amount of storage as media server applications can store quite a bit of configuration and temporary data (e.g. preview thumbnails).
compose and containers will be used by Docker to store the information it needs to set up and operate the containers you’ll want.
I would also recommend sharing config on the local network to make it easier to see and change the application configuration files (go to [Services > SMB/CIFS > Shares] and add it in the same way you did for the File Server step). Later below, I use this to add a custom theme to Ubooquity.
Configure Docker Compose: Go to [Services > Compose > Settings]. Where it says Shared folder under Compose Files, select the compose folder you created in Step 8. Where it says Docker storage under Docker, copy the absolute path (not the relative path) for the containers folder (which you can get from [Storage > Shared Folders]). Once that’s all set. Press Reinstall Docker.
Set up a User for Docker: You’ll need to create a separate user for Docker as it is dangerous to give any application full access to your root user. Go to [Users > Users] (yes, that is Users twice). Press the button to create a new user. You can give it whatever name (i.e. dockeruser) and password you want, but under Groups make sure to select both docker and users. Hit Save and once you’re set you should see your new user on the table. Make a note of the UID and GID (they’ll probably be 1000 and 100, respectively, if this is your first user other than the root) as you’ll need it when you install applications.
That was a lot! But, now you’ve set up Docker Compose. Now let’s use it to install some applications!
Setting up Media Server(s)
Before you set up the applications that access your data, you should make sure all of that data (i.e. photos you’ve taken, music you’ve downloaded, movies you’ve ripped / bought, PDFs you’d like to make available, etc.) are on your server and organized.
My suggestion is to set up a shared folder accessible to the network (mine is called Media) and have subdirectories in that folder corresponding for the different types of files that you may want your media server(s) to handle (for example: Videos, Photos, Files, etc). Then, use the network to move the files over (you should get comparable, if not faster, speeds as a USB transfer on a local area network).
The two media servers I’ve set up on my system are Plex (to serve videos, photos, and music) and Ubooquity (to serve files and especially ePUB/PDFs). There are other options out there, many of which can be similarly deployed using Docker compose, but I’m just going to cover my setup with Plex and Ubooquity below.
Plex
Why I chose it:
I’ve been using Plex for many years now, having set up clients on virtually all of my devices (phones, tablets, computers, and smart TVs).
I bought a lifetime Plex Pass a few years back which gives me access to even more functionality (including Intel Quick Sync transcode).
It has a wealth of automatic features (i.e. automatic video detection and tagging, authenticated access through the web without needing to configure a VPN, etc.) that have worked reliably over the years.
How to set up Docker Compose: Go to [Services > Compose > Files] and press the button. Under Name put down Plex and under File, paste the following (making sure the number of spaces are consistent)
version: "2.1" services: plex: image: lscr.io/linuxserver/plex:latest container_name: plex network_mode: host environment: - PUID=<UID of Docker User> - PGID=<GID of Docker User> - TZ=America/Los_Angeles - VERSION=docker devices: - /dev/dri/:/dev/dri/ volumes: - <absolute path to shared config folder>/plex:/config - <absolute path to Media folder>:/media restart: unless-stopped
You need to replace <UID of Docker User> and <GID of Docker User> with the UID and GID of the Docker user you created when you set up Docker Compose (Step 10 above), which will likely be 1000 and 100 if you followed the steps I laid out.
You can get the the absolute paths to your config folder and the location of your media files by going to [Storage > Shared Folders] in the administrative panel. I added a /plex to the config folder path under volumes:. This way you can install as many apps through Docker as you want and consolidate all of their configuration files in one place, while still keeping them separate.
If you have an Intel QuickSync CPU, the two lines that start with devices: and /dev/dri/ will allow Plex to use it (provided you also paid for a Plex Pass). If you don’t have a chip with Intel QuickSync, haven’t paid for Plex Pass, or don’t want it, leave out those two lines.
I live in the Bay Area so I set timezone TZ to America/Los_Angeles. You can find yours here.
Once you’re done, hit Save and you should be returned to your list of Docker compose files for the next step. Notice that the new Plex entry you created has a Down status, showing the container has yet to be initiated.
How to start / update / stop / remove your Plex container: You can manage all of your Docker Compose files by going to [Services > Compose > Files]. Click on the Plex entry (which should turn it yellow) and press the (up) button. This will create the container, download any files needed, and run it.
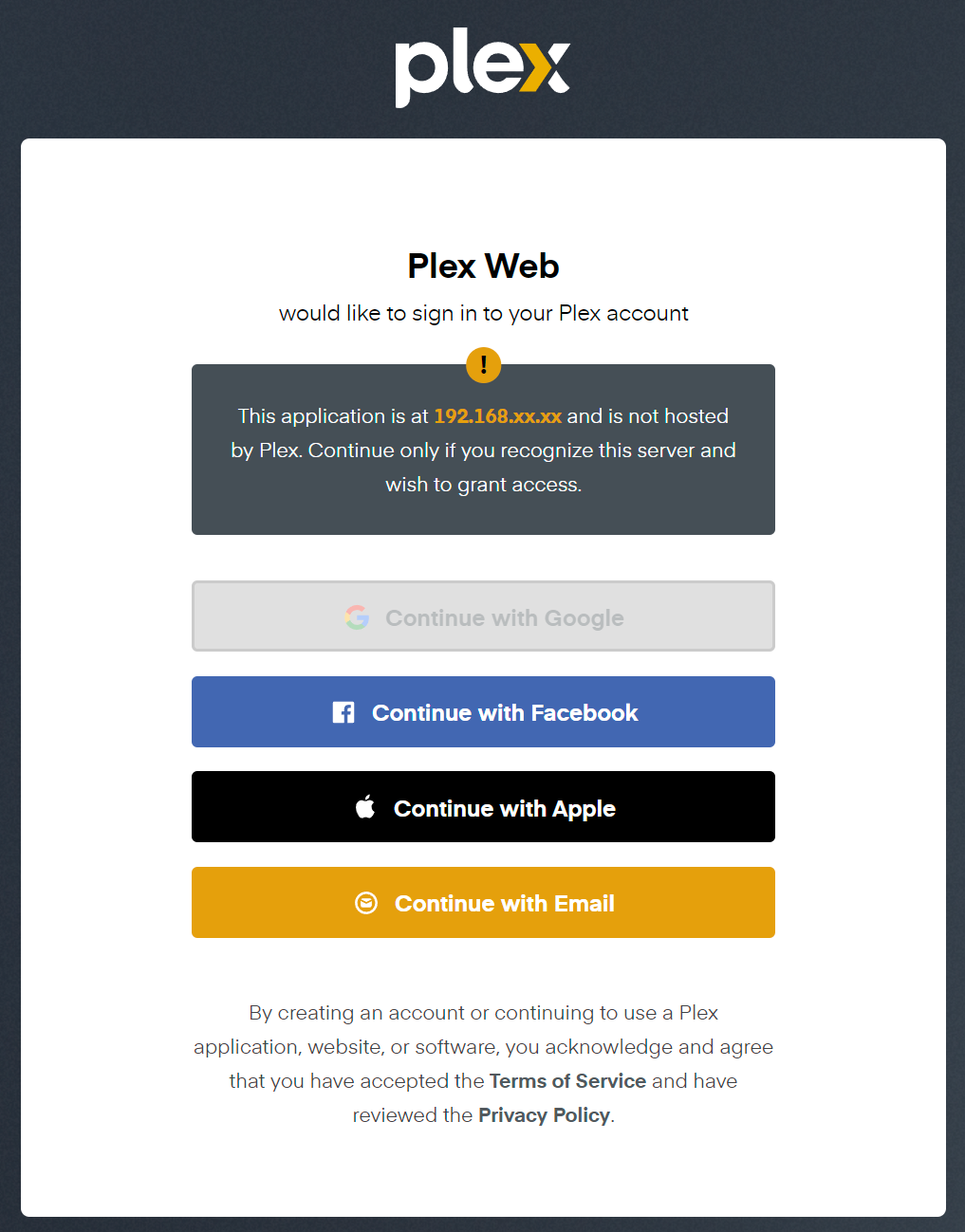
And that’s it! To prove it worked, go to http://your-ip-address:32400/web in a browser and you should see a login screen (see image below)
From time to time, you’ll want to update your software. Docker makes this very easy. Because of the image: lscr.io/linuxserver/plex:latest line, every time you press the (pull) button, Docker will pull the latest version from linuxserver.io (a group that maintains commonly used Linux containers) and, usually, you can get away with an update without needing to stop or restart your container.
Similarly, to stop the Plex container, simply tap the (stop) button. And to delete the container, tap the (down) button.
Do the setup wizard. It has good default settings (automatic library scans, remote access, etc.) — and I haven’t had to make many tweaks.
Take advantage of remote access — You can access your Plex server even when you’re not at home just by going to plex.tv and logging in.
Install Plex clients everywhere — It’s available on pretty much everything (Web, iOS, Android) and, with remote access, becomes a pretty easy way to get access to all of your content
I hide most of Plex’s default content in the Plex clients I’ve setup. While their ad-sponsored offerings are actually pretty good, I’m rarely consuming those. You can do this by configuring which things are pinned, and I pretty much only leave the things on my media server up.
Ubooquity
Why I chose it: Ubooquity has, sadly, not been updated in almost 5 years as of this writing. But, I still chose it for two reasons. First, unlike many alternatives, it does not require me to create a new file organization structure or manually tag my old files to work. It simply shows me my folder structure, lets me open the files one page at a time, maintains read location across devices, and lets me have multiple users.
Second, it’s available as a container on linuxserver.io (like Plex) which makes it easy to install and means that the infrastructure (if not the application) will continue to be updated as new container software comes out.
I may choose to switch (and the beauty of Docker is that it’s very easy to just install another content server to try it out) but for now Ubooquity made the most sense.
How to set up the Docker Compose configuration: Like with Plex, go to [Services > Compose > Files] and press the button. Under Name put down Ubooquity and under File, paste the following
--- version: "2.1" services: ubooquity: image: lscr.io/linuxserver/ubooquity:latest container_name: ubooquity environment: - PUID=<UID of Docker User> - PGID=<GID of Docker User> - TZ=America/Los_Angeles - MAXMEM=512 volumes: - <absolute path to shared config folder>/ubooquity:/config - <absolute path to shared Media folder>/Books:/books - <absolute path to shared Media folder>/Comics:/comics - <absolute path to shared Media folder>/Files:/files ports: - 2202:2202 - 2203:2203 restart: unless-stopped
You need to replace <UID of Docker User> and <GID of Docker User> with the UID and GID of the Docker user you created when you set up Docker Compose (Step 10 above), which will likely be 1000 and 100 if you followed the steps I laid out.
You can get the the absolute paths to your config folder and the location of your media files by going to [Storage > Shared Folders] in the administrative panel. I added a /ubooquity to the config folder path under volumes:. This way you can install as many apps through Docker as you want and consolidate all of their configuration files in one place, while still keeping them separate.
I live in the Bay Area so I set timezone TZ to America/Los_Angeles. You can find yours here.
Once you’re done, hit Save and you should be returned to your list of Docker compose files for the next step. Notice that the Ubooquity entry you created has a Down status, showing it has yet to be initiated.
How to start / update / stop / remove your Ubooquity container: You can manage all of your Docker Compose files by going to [Services > Compose > Files]. Click on the Ubooquity entry (which should turn it yellow) and press the (up) button. This will create the container, download any files needed, and run the system.
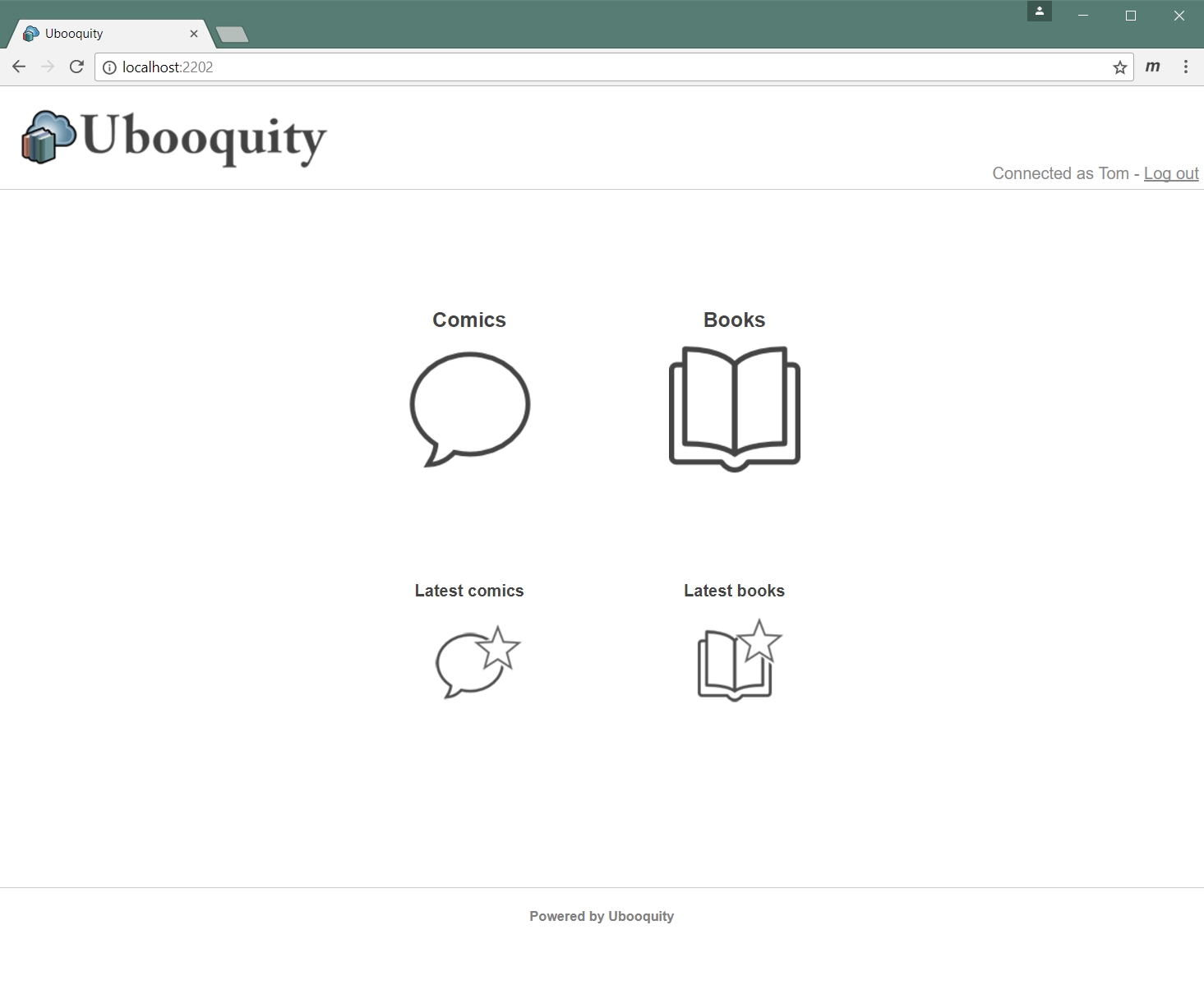
And that’s it! To prove it worked, go to your-ip-address:2202/ubooquity in a browser and you should see the user interface (image credit: Ubooquity)
From time to time, you’ll want to update your software. Docker makes this very easy. Because of the image: lscr.io/linuxserver/ubooquity:latest line, every time you press the (pull) button, Docker will pull the latest version from linuxserver.io (a group that maintains commonly used Linux containers) and, usually, you can get away with an update without needing to stop or restart your container.
Similarly, to stop the Ubooquity container, simply tap the (stop) button. And to remove the container, tap the (down) button.
Getting started with Ubooquity: While Ubooquity will more or less work out of the box, if you want to really configure your setup you’ll need to go to the admin panel atyour-ip-address:2203/ubooquity/admin (you will be prompted to create a password the first time)
In the General tab, you can see how many files are tracked in the table at the top, configure how frequently Ubooquity scans your folders for new files under Automatic scan period, manually launch a scan if you just added files with Launch New Scan, and select a theme for the interface.
If you want to create User accounts to have separate read state management or to segment which users can access specific content, you can create these users in the Security tab of the administrative panel. By doing so, you’ll need to manually go into the content type tabs (i.e. Comics, Books, Raw Files) and manually configure which users have access to which shared folders.
The easiest way to do this is to download the ZIP file at the link I gave. Unzip it on your computer (in this case it will result in the creation of a directory called plextheme-reading). Then, assuming the config shared folder you set up previously is shared across the network, take the unzipped directory and put it into the /ubooquity/themes subdirectory of the config folder.
Lastly, go back to the General tab in Ubooquity admin and, next to Current theme select plextheme-reading
Edit (10-Aug-2023): I’ve since switched to using a Local DNS service powered by Pihole to access Ubooquity using a human readable web address ubooquity.home that every device on my network can access. For information on how to do this, refer to my post on Setting Up Pihole, Nginx Proxy, and Twingate with OpenMediaVault Because entering in a local ip address and remembering 2202 or 2203 and the folders afterwards is a pain, I created keyword shortcuts for these in Chrome. The instructions for doing this will vary by browser, but to do this in Chrome, go to chrome://settings/searchEngines. There is a section of the page called Site search. Press the Add button next to it. Even though the dialog box says Add Search Engine, in practice you can use this to add keywords to any URL, just put a name for the shortcut in the Search Engine field, the shortcut you want to use in Shortcut (I used ubooquity for the core application and ubooquityadmin for the administrative console) and the URLs in URL with %s in place of query (i.e. http://your-ip-address:2202/ubooquity and http://your-ip-address:2203/ubooquity/admin).
Now to get to Ubooquity, I simply type in ubooquity in the Chrome address bar rather than a hodge podge of numbers and slashes that I’ll probably forget
External Access
One of Plex’s best features is making it very easy to access your media server even when you’re not on your home network. Having experienced that, I wanted the same level of access when I was out of the house to my network file share and applications like Ubooquity.
Edit (10-Aug-2023): I’ve since switched my method of granting external access to Twingate. This provides secure access to network resources without needing to configure Dynamic DNS, a VPN, or open up a port. For more information on how to do this, refer to my post on Setting Up Pihole, Nginx Proxy, and Twingate with OpenMediaVault
There are a few ways to do this, but the most secure path is through a VPN (virtual private network). VPNs are secure connections between computers that mimic actually being directly networked together. In our case, it lets a device securely access local network resources (like your server) even when it’s not on the home network.
OpenMediaVault makes it relatively easy to use Wireguard, a fast and popular VPN technology with support for many different types of devices. To set up Wireguard for your server for remote access, you’ll need to do six things:
Get a domain name and enable Dynamic DNS on it Most residential internet customers do not have a static IP. This means that the IP address for your home, as the rest of the world sees it, can change without warning. This makes it difficult to access externally (in much the same way that DHCP makes it hard to access your home server internally).
To address this, many domain providers offer Dynamic DNS, where a domain name (for example: myurl.com) can point to a different IP address depending on when you access it, so long as the domain provider is told what the IP address should be whenever it changes.
The exact instructions for how to do this will vary based on who your domain provider is. I use Namecheap and took an existing domain I owned and followed their instructions for enabling Dynamic DNS on it. I personally configured mine to use my vpn. subdomain, but you should use the setup you’d like, so long as you make a note of it for step 3 below.
If you don’t want to buy your own domain and are comfortable using someone else’s, you can also sign up for Duck DNS which is a free Dynamic DNS service tied to a Duck DNS subdomain.
Set up DDClient. To update the IP address your domain provider maps the domain to, you’ll need to run a background service on your server that will regularly check its IP address. One common way to do this is a software package called DDClient.
Thankfully, setting up DDClient is fairly easy thanks (again!) to a linuxserver.io container. Like with Plex & Ubooquity, go to [Services > Compose > Files] and press the button. Under Name put down DDClient and under File, paste the following
You need to replace <UID of Docker User> and <GID of Docker User> with the UID and GID of the Docker user you created when you set up Docker Compose (Step 10 above), which will likely be 1000 and 100 if you followed the steps I laid out.
You can get the the absolute path to your config folder by going to [Storage > Shared Folders] in the administrative panel. I added a /ddclient to the config folder path. This way you can install as many apps through Docker as you want and consolidate all of their configuration files in one place, while still keeping them separate.
I live in the Bay Area so I set timezone TZ to America/Los_Angeles. You can find yours here.
Once you’re done, hit Save and you should be returned to your list of Docker compose files. Click on the DDClient entry (which should turn it yellow) and press the (up) button. This will create the container, download any files needed, and run DDClient. Now, it is ready for configuration.
Configure DDClient to work with your domain provider. While the precise configuration of DDClient will vary by domain provider, the process will always involve editing a text file. To do this, login to your server using SSH or WeTTy (see the section above on Installing OMV-Extras) and enter into the command line:
nano <absolute path to shared config folder>/ddclient/ddclient.conf
Remember to substitute <absolute path to shared config folder> with the absolute path to the config folder you set up for your applications (which you can access by going to [Storage > Shared Folders] in the administrative panel).
This will open up Linux’s native text editor. Scroll to the very bottom and enter the configuration information that your domain provider requires for DynamicDNS to work. As I use Namecheap, I followed these instructions. In general, you’ll need to supply some type of information about the protocol, the server, your login / password for the domain provider, and the subdomain you intend to map to your IP address.
Then press Ctrl+X to exit, press Y when asked if you want to save, and finally Enter to confirm that you want to overwrite the old file.
Set up Port Forwarding on your router. Dynamic DNS gives devices outside of your network a consistent “address” to get to your server but it won’t do any good if your router doesn’t pass those external requests through. In this case, you’ll need to tell your router to let incoming UDP requests from port 51820 through to your server to line up with Wireguard’s defaults.
The exact instructions will vary by router so you’ll need to consult your router’s documentation. In my household, we use Google Wifi and, if you do too, here are the instructions for doing so.
Enable Wireguard. If you installed OMV-Extras above as I suggested, you’ll have access to a Plugin that turns on Wireguard. Go to [System > Plugins] on the administrative panel and then search or scroll down until you find the entry for openmediavault-wireguard. Click on it to mark it yellow and then press the button to install it.
Now go to [Services > Wireguard > Tunnels] and press the (create) button to set up a VPN tunnel. You can give it any Name you want (i.e. omv-vpn). Select your server’s main network connection for Network adapter. But, most importantly, under Endpoint, add the domain you just configured for DynamicDNS/DDClient (for example, vpn.myurl.com). Press Save
Set up Wireguard on your devices. With a Wireguard tunnel configured, your next step is to set up the devices (called clients or peers) to connect. This has two parts.
First, install the Wireguard applications on the devices themselves. Go to wireguard.com/install and download or set up the Wireguard apps. There are apps for Windows, MacOS, Android, iOS, and many flavors of Linux
Then, go back into your administrative panel and go to [Services > Wireguard > Clients] and press the (create) button to create a valid client for the VPN. Check the box next to Enable, select the tunnel you just created under Tunnel number, put a name for the device you’re going to connect under Name, and assign a unique (or it will not work) client number in Client Number . Press Save and you’ll be brought back to the Client list. Make sure to approve the change and then press the (client config) button. What you should do next depends on what kind of client device you’re configuring.
If the device you’re configuring is not a smartphone (i.e. a computer), copy the text that shows up in the Client Config popup that comes up and save that as a .conf file (for example: work_laptop_wireguard.conf). Send that file to the device in question as that file will be used by the Wireguard app on that device to configure and access the VPN. Hit Close when you’re done
If the device you’re configuring is a smartphone, hit Close button on the Client Config popup that comes up as you will be presented with a QR code that your smartphone Wireguard app can capture to configure the VPN connection.
Now go into your Wireguard app on the client device and use it to either take a picture of the QR code when prompted or load the .conf file. Your device is now configured to connect to your server securely no matter where you are. A good test of this is to disconnect a set up smartphone from your home WiFi and enable the VPN. Since you’re no longer on WiFi you should not be on the same network as your server. If you can enter http://your-ip-address in this mode into a browser and still reach the administrative panel for OpenMediaVault, you’re home free!
One additional note: by default, Wireguard also acts as a proxy, meaning all internet traffic you send from the device will be routed through the server. This can be valuable if you’re trying to access a blocked website or pretend to be from a different location, but it can also be unnecessarily slow (and bandwidth consuming). I have my Wireguard configured to only route traffic that is going to my server’s local IP address through Wireguard. You can do this by configuring your client device’s Allowed IPs to your-ip-address (for example: 192.168.99.99) from the Wireguard app.
Congratulations, you have now configured a file server and media server that you can securely access from anywhere!
Concluding Thoughts
A few concluding thoughts:
This was probably way too complicated for most people. Believe it or not, what was written above is a shortened version of what I went through. Even holding aside that use of the command line and Docker automatically makes this hard for many consumers, I still had to deal with missing drivers, Linux not recognizing my USB drive through the USB C port (but through the USB A one?), puzzling over different external access configurations (VPN vs Let’s Encrypt SSL on my server vs self-sign certificate), and minimal feedback when my initial attempts to use Wireguard failed. While I learned a great deal, for most people, it makes more sense to go completely third party (i.e. use Google / Amazon / Apple for everything) or, if you have some pain tolerance, with a high-end NAS.
Docker/containerization is extremely powerful. Prior to this, I had thought of Docker as just a “flavor” of virtual machine, a software technology underlying cloud computing which abstracts server software from server hardware. And, while there is some overlap, I completely misunderstood why containers were so powerful for software deployment. By using 3 fairly simple blocks of text, I was able to deploy 3 complicated applications which needed different levels of hardware and network access (Ubooquity, DDClient, Plex) in minutes without issue.
I was pleasantly surprised by how helpful the blogs and forums were. While the amount of work needed to find the right advice can be daunting, every time I ran into an issue, I was able to find some guidance online (often in a forum or subreddit). While there were certainly … abrasive personalities, by in large many of the questions being asked were by non-experts and they were answered by experts showing patience and generosity of spirit. Part of the reason I wrote this is to pay this forward for the next set of people who want to experiment with setting up their own server.
I am excited to try still more applications. Lists about what hobbyists are running on their home servers like this and this and this make me very intrigued by the possibilities. I’m currently considering a network-wide adblocker like Pi-Hole and backup tools like BorgBackup. There is a tremendous amount of creativity out there!
For more help on setting any of this stuff up, here are a few additional resources that proved helpful to me:
OMV Extras Wiki — probably the single best source of help I turned to in setting up OpenMediaVault, Docker Compose, and Wireguard
Having been lucky enough to invest in both tech (cloud, mobile, software) and “deeptech” (materials, cleantech, energy, life science) startups (and having also ran product at a mobile app startup), it has been striking to see how fundamentally different the paradigms that drive success in each are.
Whether knowingly or not, most successful tech startups over the last decade have followed a basic playbook:
Take advantage of rising smartphone penetration and improvements in cloud technology to build digital products that solve challenges in big markets pertaining to access (e.g., to suppliers, to customers, to friends, to content, to information, etc.)
Build a solid team of engineers, designers, growth, sales, marketing, and product people to execute on lean software development and growth methodologies
Hire the right executives to carry out the right mix of tried-and-true as well as “out of the box” channel and business developmentstrategies to scale bigger and faster
This playbook appears deceptively simple but is very difficult to execute well. It works because for markets where “software is eating the world”:
There is relatively little technology risk: With the exception of some of the most challenging AI, infrastructure, and security challenges, most tech startups are primarily dealing with engineering and product execution challenges — what is the right thing to build and how do I build it on time, under budget? — rather than fundamental technology discovery and feasibility challenges
Skills & knowledge are broadly transferable: Modern software development and growth methodologies work across a wide range of tech products and markets. This means that effective engineers, salespeople, marketers, product people, designers, etc. at one company will generally be effective at another. As a result, its a lot easier for investors/executives to both gauge the caliber of a team (by looking at their experience) and augment a team when problems arise (by recruiting the right people with the right backgrounds).
Distribution is cheap and fast: Cloud/mobile technology means that a new product/update is a server upgrade/browser refresh/app store download away. This has three important effects:
The first is that startups can launch with incomplete or buggy solutions because they can readily provide hotfixes and upgrades.
The second is that startups can quickly release new product features and designs to respond to new information and changing market conditions.
The third is that adoption is relatively straightforward. While there may be some integration and qualification challenges, in general, the product is accessible via a quick download/browser refresh, and the core challenge is in getting enough people to use a product in the right way.
In contrast, if you look at deeptech companies, a very different set of rules apply:
Technology risk/uncertainty is inherent: One of the defining hallmarks of a deeptech company is dealing with uncertainty from constraints imposed by reality (i.e. the laws of physics, the underlying biology, the limits of current technology, etc.). As a result, deeptech startups regularly face feasibility challenges — what is even possible to build? — and uncertainty around the R&D cycles to get to a good outcome — how long will it take / how much will it cost to figure this all out?
Skills & knowledge are not easily transferable: Because the technical and business talent needed in deeptech is usually specific to the field, talent and skills are not necessarily transferable from sector to sector or even company to company. The result is that it is much harder for investors/executives to evaluate team caliber (whether on technical merits or judging past experience) or to simply put the right people into place if there are problems that come up.
Product iteration is slow and costly: The tech startup ethos of “move fast and break things” is just harder to do with deeptech.
At the most basic level, it just costs a lot more and takes a lot more time to iterate on a physical product than a software one. It’s not just that physical products require physical materials and processing, but the availability of low cost technology platforms like Amazon Web Services and open source software dramatically lower the amount of time / cash needed to make something testable in tech than in deeptech.
Furthermore, because deeptech innovations tend to have real-world physical impacts (to health, to safety, to a supply chain/manufacturing line, etc.), deeptech companies generally face far more regulatory and commercial scrutiny. These groups are generally less forgiving of incomplete/buggy offerings and their assessments can lengthen development cycles. Deeptech companies generally can’t take the “ask for forgiveness later” approaches that some tech companies (i.e. Uber and AirBnb) have been able to get away with (exhibit 1: Theranos).
As a result, while there is no single playbook that works across all deeptech categories, the most successful deeptech startups tend to embody a few basic principles:
Go after markets where there is a very clear, unmet need: The best deeptech entrepreneurs tend to take very few chances with market risk and only pursue challenges where a very well-defined unmet need (i.e., there are no treatments for Alzheimer’s, this industry needs a battery that can last at least 1000 cycles, etc) blocks a significant market opportunity. This reduces the risk that a (likely long and costly) development effort achieves technical/scientific success without also achieving business success. This is in contrast with tech where creating or iterating on poorly defined markets (i.e., Uber and Airbnb) is oftentimes at the heart of what makes a company successful.
Focus on “one miracle” problems: Its tempting to fantasize about what could happen if you could completely re-write every aspect of an industry or problem but the best deeptech startups focus on innovating where they won’t need the rest of the world to change dramatically in order to have an impact (e.g., compatible with existing channels, business models, standard interfaces, manufacturing equipment, etc). Its challenging enough to advance the state of the art of technology — why make it even harder?
Pursue technologies that can significantly over-deliver on what the market needs: Because of the risks involved with developing advanced technologies, the best deeptech entrepreneurs work in technologies where even a partial success can clear the bar for what is needed to go to market. At the minimum, this reduces the risk of failure. But, hopefully, it gives the company the chance to fundamentally transform the market it plays in by being 10x better than the alternatives. This is in contrast to many tech markets where market success often comes less from technical performance and more from identifying the right growth channels and product features to serve market needs (i.e., Facebook, Twitter, and Snapchat vs. MySpace, Orkut, and Friendster; Amazon vs. brick & mortar bookstores and electronics stores)
All of this isn’t to say that there aren’t similarities between successful startups in both categories — strong vision, thoughtful leadership, and success-oriented cultures are just some examples of common traits in both. Nor is it to denigrate one versus the other. But, practically speaking, investing or operating successfully in both requires very different guiding principles and speaks to the heart of why its relatively rare to see individuals and organizations who can cross over to do both.
Special thanks to Sophia Wang, Ryan Gilliam, and Kevin Lin Lee for reading an earlier draft and making this better!
In recent years, it’s been the opposite of controversial to say that the tech industry is in a bubble. The terrible recent stock market performance of once high-flying startups across virtually every industry (see table below) and the turmoil in the stock market stemming from low oil prices and concerns about the economies of countries like China and Brazil have raised fears that the bubble is beginning to pop.
While history will judge when this bubble “officially” bursts, the purpose of this post is to try to make some predictions about what will happen during/after this “correction” and pull together some advice for people in / wanting to get into the tech industry. Starting with the immediate consequences, one can reasonably expect that:
Exit pipeline will dry up: When startup valuations are higher than what the company could reasonably get in the stock market, management teams (who need to keep their investors and employees happy) become less willing to go public. And, if public markets are less excited about startups, the price acquirers need to pay to convince a management team to sell goes down. The result is fewer exits and less cash back to investors and employees for the exits that do happen.
VCs become less willing to invest: VCs invest in startups on the promise that future IPOs and acquisitions will make them even more money. When the exit pipeline dries up, VCs get cold feet because the ability to get a nice exit seems to fade away. The result is that VCs become a lot more price-sensitive when it comes to investing in later stage companies (where the dried up exit pipeline hurts the most).
Later stage companies start cutting costs: Companies in an environment where they can’t sell themselves or easily raise money have no choice but to cut costs. Since the vast majority of later-stage startups run at a loss to increase growth, they will find themselves in the uncomfortable position of slowing down hiring and potentially laying employees off, cutting back on perks, and focusing a lot more on getting their financials in order.
The result of all of this will be interesting for folks used to a tech industry (and a Bay Area) flush with cash and boundlessly optimistic:
Job hopping should slow: “Easy money” to help companies figure out what works or to get an “acquihire” as a soft landing will be harder to get in a challenged financing and exit environment. The result is that the rapid job hopping endemic in the tech industry should slow as potential founders find it harder to raise money for their ideas and as it becomes harder for new startups to get the capital they need to pay top dollar.
Strong companies are here to stay: While there is broad agreement that there are too many startups with higher valuations than reasonable, what’s also become clear is there are a number of mature tech companies that are doing exceptionally well (i.e. Facebook, Amazon, Netflix, and Google) and a number of “hotshots” which have demonstrated enough growth and strong enough unit economics and market position to survive a challenged environment (i.e. Uber, Airbnb). This will let them continue to hire and invest in ways that weaker peers will be unable to match.
Tech “luxury money” will slow but not disappear: Anyone who lives in the Bay Area has a story of the ridiculousness of “tech money” (sky-high rents, gourmet toast,“its like Uber but for X”, etc). This has been fueled by cash from the startup world as well as free flowing VC money subsidizing many of these new services . However, in a world where companies need to cut costs, where exits are harder to come by, and where VCs are less willing to subsidize random on-demand services, a lot of this will diminish. That some of these services are fundamentally better than what came before (i.e. Uber) and that stronger companies will continue to pay top dollar for top talent will prevent all of this from collapsing (and lets not forget San Francisco’s irrational housing supply policies). As a result, people expecting a reversal of gentrification and the excesses of tech wealth will likely be disappointed, but its reasonable to expect a dramatic rationalization of the price and quantity of many “luxuries” that Bay Area inhabitants have become accustomed to soon.
So, what to do if you’re in / trying to get in to / wanting to invest in the tech industry?
Understand the business before you get in: Its a shame that market sentiment drives fundraising and exits, because good financial performance is generally a pretty good indicator of the long-term prospects of a business. In an environment where its harder to exit and raise cash, its absolutely critical to make sure there is a solid business footing so the company can keep going or raise money / exit on good terms.
Be concerned about companies which have a lot of startup exposure: Even if a company has solid financial performance, if much of that comes from selling to startups (especially services around accounting, recruiting, or sales), then they’re dependent on VCs opening up their own wallets to make money.
Have a much higher bar for large, later-stage companies: The companies that will feel the most “pain” the earliest will be those with with high valuations and high costs. Raising money at unicorn valuations can make a sexy press release but it doesn’t amount to anything if you can’t exit or raise money at an even higher valuation.
Rationalize exposure to “luxury”: Don’t expect that “Uber but for X” service that you love to stick around (at least not at current prices)…
Early stage companies can still be attractive: Companies that are several years from an exit & raising large amounts of cash will be insulated in the near-term from the pain in the later stage, especially if they are committed to staying frugal and building a disruptive business. Since they are already relatively low in valuation and since investors know they are discounting off a valuation in the future (potentially after any current market softness), the downward pressures on valuation are potentially lighter as well.
When Steve Jobs first launched the iPhone in 2007, Apple’s perception of where the smartphone application market would move was in the direction of web applications. The reasons for this are obvious: people are familiar with how to build web pages and applications, and it simplifies application delivery.
Yet in under a year, Apple changed course, shifting the focus of iPhone development from web applications to building native applications custom-built (by definition) for the iPhone’s operating system and hardware. While I suspect part of the reason this was done was to lock-in developers, the main reason was certainly the inadequacy of available browser/web technology. While we can debate the former, the latter is just plain obvious. In 2007, the state of web development was relatively primitive relative to today. There was no credible HTML5 support. Javascript performance was paltry. There was no real way for web applications to access local resources/hardware capabilities. Simply put, it was probably too difficult for Apple to kludge together an application development platform based solely on open web technologies which would get the sort of performance and functionality Apple wanted.
But, that was four years ago, and web technology has come a long way. Combine that with the tech commentator-sphere’s obsession with hyping up a rivalry between “native vs HTML5 app development”, and it begs the question: will the future of application development be HTML5 applications or native?
There are a lot of “moving parts” in a question like this, but I believe the question itself is a red herring. Enhancements to browser performance and the new capabilities that HTML5 will bring like offline storage, a canvas for direct graphic manipulation, and tools to access the file system, mean, at least to this tech blogger, that “HTML5 applications” are not distinct from native applications at all, they are simply native applications that you access through the internet. Its not a different technology vector – it’s just a different form of delivery.
Critics of this idea may cite that the performance and interface capabilities of browser-based applications lag far behind those of “traditional” native applications, and thus they will always be distinct. And, as of today, they are correct. However, this discounts a few things:
Browser performance and browser-based application design are improving at a rapid rate, in no small part because of the combination of competition between different browsers and the fact that much of the code for these browsers is open source. There will probably always be a gap between browser-based apps and native, but I believe this gap will continue to narrow to the point where, for many applications, it simply won’t be a deal-breaker anymore.
History shows that cross-platform portability and ease of development can trump performance gaps. Once upon a time, all developers worth their salt coded in low level machine language. But this was a nightmare – it was difficult to do simple things like showing text on a screen, and the code written only worked on specific chips and operating systems and hardware configurations. I learned C which helped to abstract a lot of that away, and, keeping with the trend of moving towards more portability and abstraction, the mobile/web developers of today develop with tools (Python, Objective C, Ruby, Java, Javascript, etc) which make C look pretty low-level and hard to work with. Each level of abstraction adds a performance penalty, but that has hardly stopped developers from embracing them, and I feel the same will be true of “HTML5”.
Huge platform economic advantages. There are three huge advantages today to HTML5 development over “traditional native app development”. The first is the ability to have essentially the same application run across any device which supports a browser. Granted, there are performance and user experience issues with this approach, but when you’re a startup or even a corporate project with limited resources, being able to get wide distribution for earlier products is a huge advantage. The second is that HTML5 as a platform lacks the control/economic baggage that iOS and even Android have where distribution is controlled and “taxed” (30% to Apple/Google for an app download, 30% cut of digital goods purchases). I mean, what other reason does Amazon have to move its Kindle application off of the iOS native path and into HTML5 territory? The third is that web applications do not require the latest and greatest hardware to perform amazing feats. Because these apps are fundamentally browser-based, using the internet to connect to a server-based/cloud-based application allows even “dumb devices” to do amazing things by outsourcing some of that work to another system. The combination of these three makes it easier to build new applications and services and make money off of them – which will ultimately lead to more and better applications and services for the “HTML5 ecosystem.”
Given Google’s strategic interest in the web as an open development platform, its no small wonder that they have pushed this concept the furthest. Not only are they working on a project called Native Client to let users achieve “native performance” with the browser, they’ve built an entire operating system centered entirely around the browser, Chrome OS, and were the first to build a major web application store, the Chrome Web Store to help with application discovery.
While it remains to be seen if any of these initiatives will end up successful, this is definitely a compelling view of how the technology ecosystem evolves, and, putting on my forward-thinking cap on, I would not be surprised if:
The major operating systems became more ChromeOS-like over time. Mac OS’s dashboard widgets and Windows 7’s gadgets are already basically HTML5 mini-apps, and Microsoft has publicly stated that Windows 8 will support HTML5-based application development. I think this is a sign of things to come as the web platform evolves and matures.
Continued focus on browser performance may lead to new devices/browsers focused on HTML5 applications. In the 1990s/2000s, there was a ton of attention focused on building Java accelerators in hardware/chips and software platforms who’s main function was to run Java. While Java did not take over the world the way its supporters had thought, I wouldn’t be surprised to see a similar explosion just over the horizon focused on HTML5/Javascript performance – maybe even HTML5 optimized chips/accelerators, additional ChromeOS-like platforms, and potentially browsers optimized to run just HTML5 games or enterprise applications?
Web application discovery will become far more important. The one big weakness as it stands today for HTML5 is application discovery. Its still far easier to discover a native mobile app using the iTunes App Store or the Android Market than it is to find a good HTML5 app. But, as platform matures and the platform economics shift, new application stores/recommendation engines/syndication platforms will become increasingly critical.

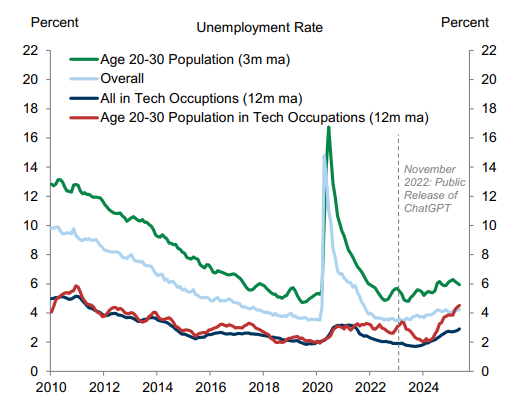

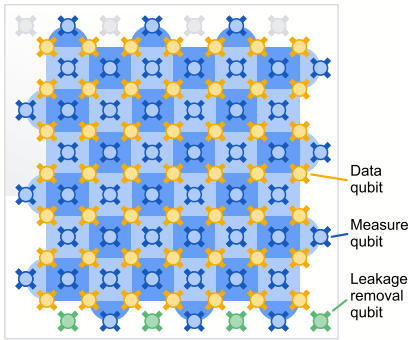










:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24830088/Thred_top.jpg)