It’s both unsurprising but also astonishing at the same time.
Amazon.com has grabbed the crown of biggest delivery business in the U.S., surpassing both UPS and FedEx in parcel volumes.
The Seattle e-commerce giant delivered more packages to U.S. homes in 2022 than UPS, after eclipsing FedEx in 2020, and it is on track to widen the gap this year, according to internal Amazon data and people familiar with the matter. The U.S. Postal Service is still the biggest parcel service by volume; it handles hundreds of millions of packages for all three companies.
Market phase transitions have a tendency to be incredibly disruptive to market participants. A company or market segment used to be the “alpha wolf” can suddenly find themselves an outsider in a short time. Look at how quickly Research in Motion (makers of the Blackberry) went from industry darling to laggard after Apple’s iPhone transformed the phone market.
Something similar is happening in the high performance computing (HPC) world (colloquially known as supercomputers). Built to do the highly complex calculations needed to simulate complex physical phenomena, HPC was, for years, the “Formula One” of the computing world. New memory, networking, and processor technologies oftentimes got their start in HPC, as it was the application that was most in need of pushing the edge (and had the cash to spend on exotic new hardware to do it).
The use of GPUs (graphical processing units) outside of games, for example, was a HPC calling card. NVIDIA’s CUDA framework which has helped give it such a lead in the AI semiconductor race was originally built to accelerate the types of computations that HPC could benefit from.
The success of Deep Learning as the chosen approach for AI benefited greatly from this initial work in HPC, as the math required to make deep learning worked was similar enough that existing GPUs and programming frameworks could be adapted. And, as a result, HPC benefited as well, as more interest and investment flowed into the space.
But, we’re now seeing a market transition. Unlike with HPC which performs mathematical operations requiring every last iota of precision on mostly dense matrices, AI inference works on sparse matrices and does not require much precision at all. This has resulted in a shift in industry away from software and hardware that works for both HPC and AI and towards the much larger AI market specifically.
The HPC community is used to being first, and we always considered ourselves as the F1 racing team of computing. We invent the turbochargers and fuel injection and the carbon fiber and then we put that into more general purpose vehicles, to use an analogy. I worry that the HPC community has sort of taken the backseat when it comes to AI and is not leading the charge. Like you, I’m seeing a lot of this AI stuff being led out of the hyperscalers and clouds. And we’ve got to find a way to take that back and carve our own use cases. There are a lot more HPC sites around the world than there are cloud sites, and we have got access to all a lot of data.
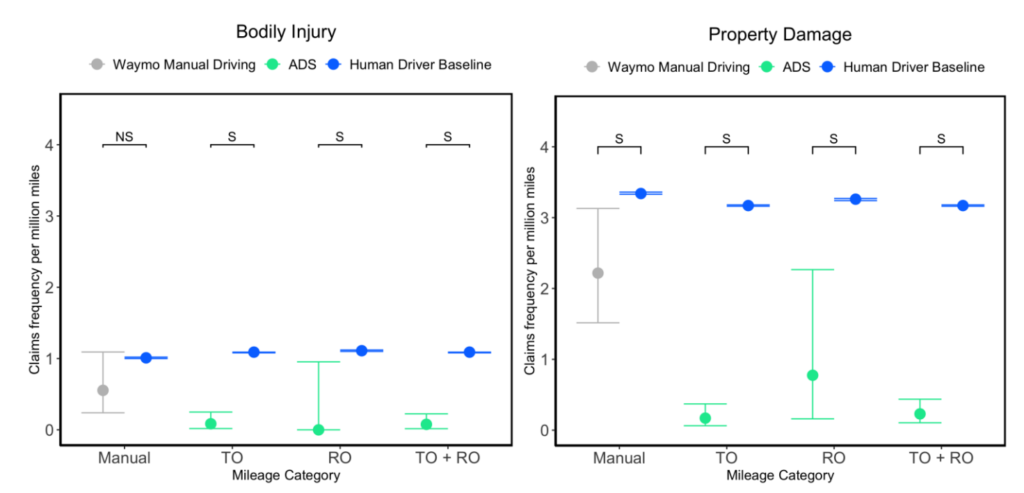
I’m over two months late to seeing this study, but a brilliant study design (use insurance data to measure rate of bodily injury and property damage) and strong, noteworthy conclusion (doesn’t matter how you cut it, Waymo’s autonomous vehicle service resulted in fewer injuries per mile and less property damage per mile than human drivers in the same area) make this worthwhile to return to! Short and sweet paper from researchers from Waymo, Swiss Re (the re-insurer), and Stanford that is well worth the 10 minute read!
When TO and RO datasets were combined, totaling 39,096,826 miles, there was a significant reduction in bodily injury claims frequency by 93% (0.08 vs 1.09 claims per million miles), TO+ROBI 95% CI [0.02, 0.22], Baseline 95% CI [1.08, 1.09]. Property damage claims frequency was significantly reduced by 93% (0.23 vs 3.17 claims per million miles), TO+ROPDL 95% CI [0.11, 0.44], Baseline 95% CI [3.16, 3.18].
My good friend Danny Goodman (and Co-Founder at Swarm Aero) recently wrote a great essay on how AI can help with America’s defense. He outlines 3 opportunities:
“Affordable mass”: Balancing/augmenting America’s historical strategy of pursuing only extremely expensive, long-lived “exquisite” assets (e.g. F-35’s, aircraft carriers) with autonomous and lower cost units which can safely increase sensor capability &, if it comes to it, serve as alternative targets to help safeguard human operators
Smarter war planning: Leveraging modeling & simulation to devise better tactics and strategies (think AlphaCraft on steroids)
Smarter procurement: Using AI to evaluate how programs and budget line items will actually impact America’s defensive capabilities to provide objectivity in budgeting
With the proper rules in place, AI is poised to be a transformative force that will strengthen America’s national defense. It will give our military new weapons systems and capabilities, smarter ways to plan for increasingly complex conflicts, and better ways to decide what to build and buy, and when. Along the way, it will help save both taxpayer dollars and, more importantly, lives.
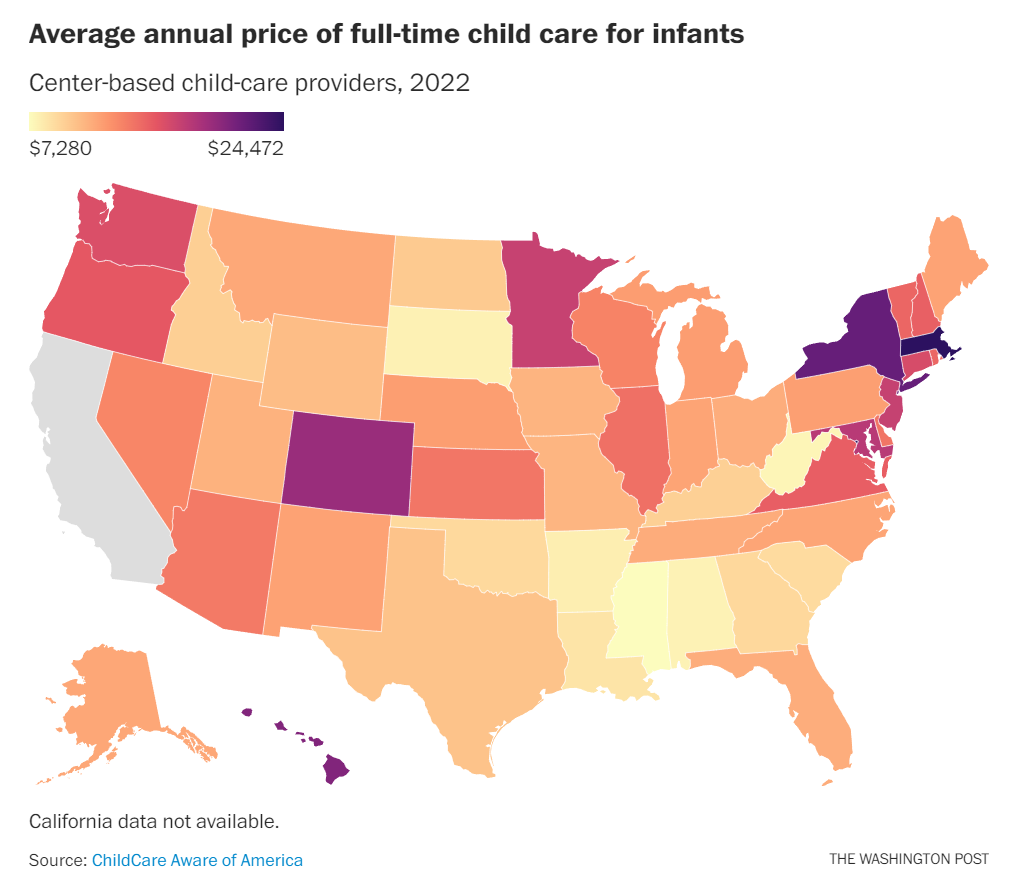
As a parent myself, few things throw off my work day as much as a wrench in my childcare — like a kid being sick and needing to come home or a school/childcare center being closed for the day. The time required to change plans while balancing work, the desire to check-in on your child throughout the work day to make sure they’re doing okay… and this is as someone with a fair amount of work flexibility, a spouse who also has flexibility, and nearby family who can pitch in.
Childcare, while expensive, is a vital piece of the infrastructure that makes my and my spouse’s careers possible — and hence the (hopefully positive 😇) economic impact we have possible. It’s made me very sympathetic to the notion that we need to take childcare policy much more seriously — something that I think played out for millions of households when COVID disrupted schooling and childcare plans.
Census data suggest that, as things are, the child-care industry nationwide has been operating in the red for two straight years. Now, as programs still stressed by the pandemic lose a major source of public funds, many programs around the country are considering closure. When these businesses do shut down, they can send shock waves throughout their local economies. The shuttered child-care business sheds jobs; parents that relied on that business lose care arrangements for their kids, which in turn disrupts parents’ ability to work; and the employers of those parents must then scramble to adjust for lost workforce hours.
While each of those can feel like an individual misfortune, they are all part of a larger system of how our country cares for our young while adults work — or fails to do so. And the ripple effects can be enormous. Here’s one story of what happened downstream when a single day-care center in Wisconsin shut its doors.
Silicon nerd 🤓 that I am, I have gone through multiple cycles of excited-then-disappointed for Windows-on-ARM, especially considering the success of ChromeOS with ARM, the Apple M1/M2 (Apple’s own ARM silicon which now powers its laptops), and AWS Graviton (Amazon’s own ARM chip for its cloud computing services).
I may just be setting myself up for disappointment here but these (admittedly vendor-provided) specs for their new Snapdragon X (based on technology they acquired from Nuvia and are currently being sued for by ARM) look very impressive. Biased as they may be, the fact that these chips are performing in the same performance range as Intel/AMD/Apple’s silicon on single-threaded benchmarks (not to mention the multi-threaded applications which work well with the Snapdragon X’s 12 cores) hopefully bodes well for the state of CPU competition in the PC market!
Single-threaded CPU performance (Config A is a high performance tuned offering, Config B is a “thin & light” configuration)Multi-threaded CPU performance (Config A is a high performance tuned offering, Config B is a “thin & light” configuration)
Overall, Qualcomm’s early benchmark disclosure offers an interesting first look at what to expect from their forthcoming laptop SoC. While the competitive performance comparisons are poorly-timed given that next-generation hardware is just around the corner from most of Qualcomm’s rivals, the fact that we’re talking about the Snapdragon X Elite in the same breath as the M2 or Raptor Lake is a major achievement for Qualcomm. Coming from the lackluster Snapdragon 8cx SoCs, which simply couldn’t compete on performance, the Snapdragon X Elite is clearly going to be a big step up in virtually every way.
Qualcomm Snapdragon X Elite Performance Preview: A First Look at What’s to Come Ryan Smith | Anandtech
Gene editing makes possible new therapies and actual cures (not just treatments) that were previously not. But, one thing that doesn’t get discussed a great deal is how these new gene editing-based therapies throw the “take two and call me in the morning” model out the window.
referral by hematologist (not to mention insurance approval!)
collection of cells (probably via bone marrow extraction)
(partial) myeloablation of the patient
shipping the cells to a manufacturing facility
manufacturing facility applies gene editing on the cells
shipping of cells back
infusion of the gene edited cells to the patient (so they hopefully engraft back in their bone marrow)
Each step is complicated and has their own set of risks. And, while there are many economic aspects of this that are similar to more traditional drug regimens (high price points, deep biological understanding of disease, complicated manufacturing [esp for biologicals], medical / insurance outreach, patient education, etc.), gene editing-based therapies (which can also include CAR-T therapy) now require a level of ongoing operational complexity that the biotech/pharmaceutical industries will need to adapt to if we want to bring these therapies to more people.
To make and administer the therapy is laborious, first requiring a referral from a hematologist. If the patient is eligible, their cells are collected and shipped to a manufacturing facility where they’re genetically edited to express a form of an essential protein called hemoglobin.
The cells are then shipped back to a treatment facility that infuses them into the patient’s bone marrow. But to make sure there’s enough room for these new cells, patients first undergo myeloablation — a chemotherapy regimen that can be very difficult on their bodies and comes with the risk of infertility. Older patients may not be healthy enough to receive this treatment.
“This is an extensive and expensive process,” Arbuckle said.
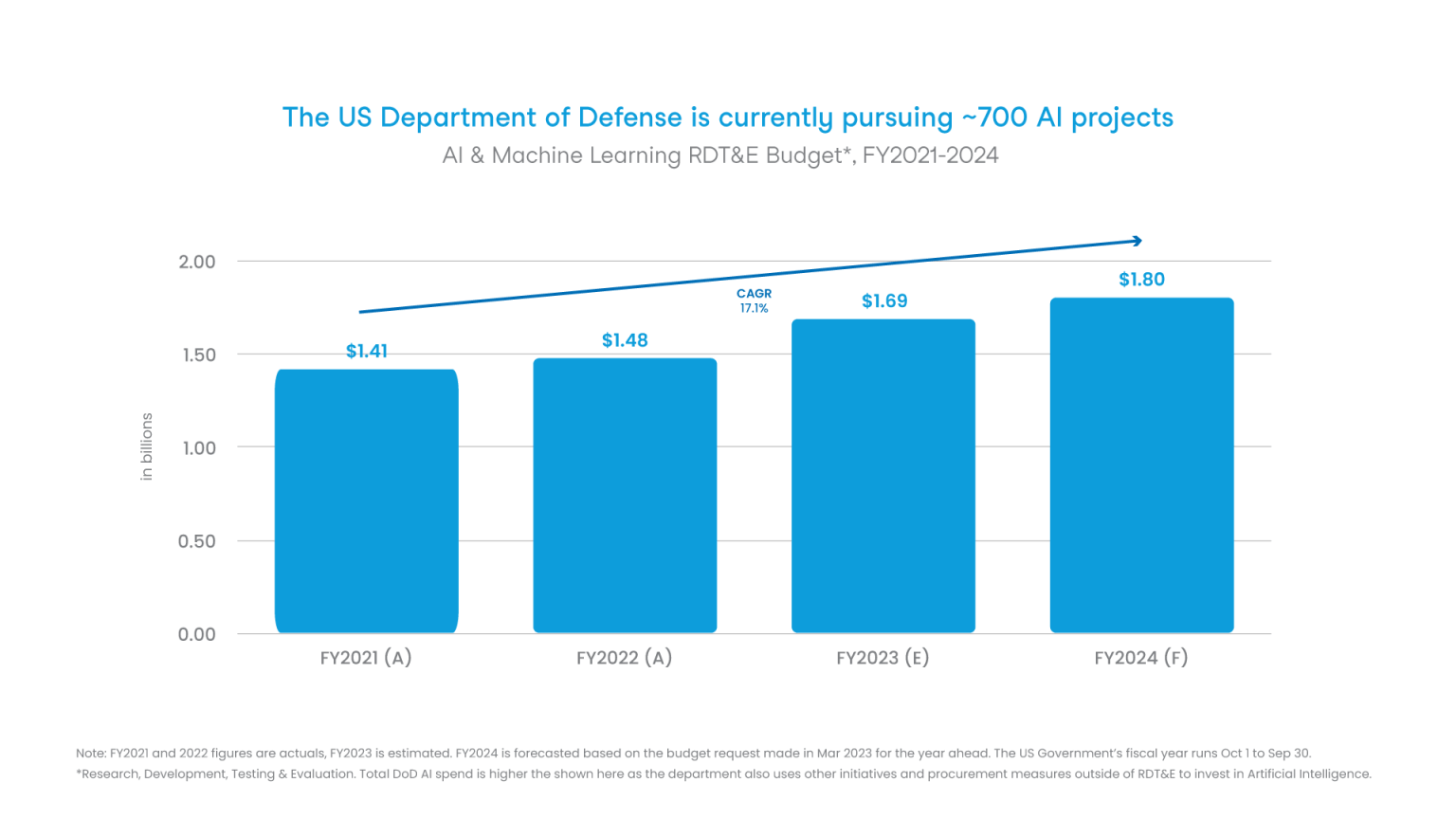
The 2022 CHIPS and Science Act earmarked hundreds of billions in subsidies and tax credits to bolster a U.S. domestic semiconductor (and especially semiconductor manufacturing) industry. If it works, it will dramatically reposition the U.S. in the global semiconductor value chain (especially relative to China).
With such large amounts of taxpayer money practically “gifted” to large (already very profitable) corporations like Intel, the U.S. taxpayer can reasonably assume that these funds should be allocated carefully and thoughtfully and with processes in place to make sure every penny furthered the U.S.’s strategic goals.
But, when the world’s financial decisions are powered by Excel spreadsheets, even the best laid plans can go awry.
The team behind the startup Rowsie created a large language model (LLM)-powered tool which can understand Excel spreadsheets and answer questions posed to it. They downloaded a spreadsheet that the US government provided as an example of the information and calculations they want applicants fill out in order to qualify. They then applied their AI tool to the spreadsheet to understand it’s structure and formulas.
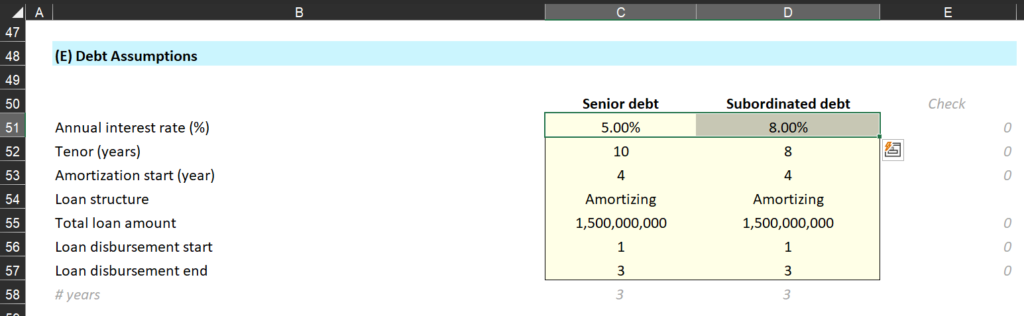
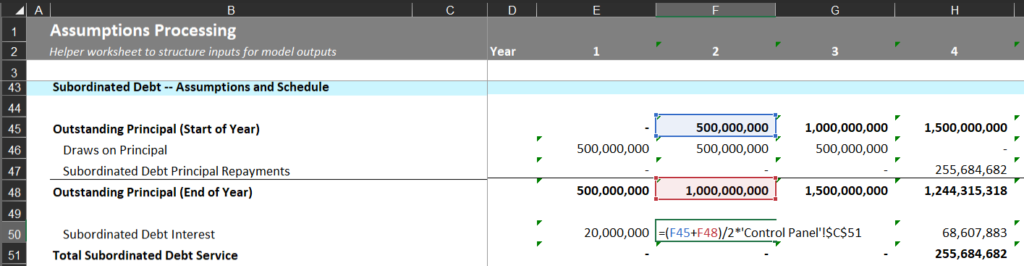
Interestingly, Rowsie was able to find a single-cell spreadsheet error (see images below) which resulted in a $178 million understatement of interest payments!
The Control Panel tab in the Example Pre-App-Simple-Financial-Model spreadsheet from the CHIPS Act funding application website. Notice cells C51 and D51 corresponding to the senior debt interest rate (5%) and the subordinated debt interest rate (8%)The Assumptions Processing tab in the Example Pre-App-Simple-Financial-Model spreadsheet from the CHIPS Act funding application website. Notice row 50. Despite the section being about Subordinated Debt (see Cell B50), they’re using cell C51 from the Control Panel tab (which points to the Senior Debt rate of 5%) rather than the correct cell of D51 (which points to the Subordinated Debt rate of 8%).
To be clear, this is not a criticism of the spreadsheet’s architects. In this case, what seems to have happened, is that the spreadsheet creator copied an earlier row (row 40) and forgot to edit the formula to account for the fact that row 50 is about subordinated debt and row 40 is about senior debt. It’s a familiar story to anyone who’s ever been tasked with doing something complicated in Excel. Features like copy and paste and complex formulas are very powerful, but also make it very easy for a small mistake to cascade. It’s also remarkably hard to catch!
Hopefully the Department of Commerce catches on and fixes this little clerical mishap, and that applicants are submitting good spreadsheets, free of errors. But, this case underscores how (1) so many of the world’s financial and policy decisions rest on Excel spreadsheets and you just have to hope 🤞🏻 no large mistakes were made, and (2) the potential for tools like Rowsie to be tireless proofreaders and assistants who can help us avoid mistakes and understand those critical spreadsheets quickly.
Something is wrong with the state of the Marvel Cinematic Universe (MCU).
In 2019, Disney/Marvel topped off an amazing decade-plus run of films with Avengers: Endgame, becoming (until Avatar was re-released in China) the highest grossing film of all time. This was in spite of an objectively complicated plot which required a deep understanding of all of Marvel Cinematic Universe continuity to follow.
And yet critics and fans (myself included! 🙋🏻♂️) loved it! It seemed like Marvel could do no wrong.
It doesn’t feel that way anymore. While I’ve personally enjoyed Black Panther: Wakanda Forever and Shang-Chi, this Time article does a good job of critiquing how complicated the MCU has become, so much so that a layperson can’t just watch one casually.
But it misses one additional thing which I think gets to the heart of why the MCU just doesn’t feel right anymore. The MCU is now so commercially large, that the scripts feel like they’re written by a committee of businesspeople (oh make sure you’re setting up this other show/movie! let’s get in an action scene with some kind of viral quip!) rather than writers/directors trying to tell an entertaining story for the sake of the story.
Does all this sound like gobbledygook? For years now, audiences have not been able to watch Marvel shows and movies casually. But watching Loki Season 2, I felt I could not even look down at my phone for a second without getting completely lost. Heck, even if you’re watching with rapt attention, you’ll probably have a difficult time keeping up with the convoluted time travel shenanigans. The various MacGuffins, Easter eggs, and pseudoscientific explanations of superpowers used to be fun. Now they feel like homework.
This article resonates with me on so many levels: both as the child who came to the US and saw his language skills deteriorate as he assimilated and as the parent trying to preserve his kids’ connection to their cultural heritage
In the U.S., bringing a heritage language back into a family usually comes down to the efforts of individuals. The parents I spoke with who taught their children a heritage language that they themselves didn’t speak fluently had essentially organized their own lives around the effort.
I am a big Google Pixel fan, being an owner and user of multiple Google Pixel line products. As a result, I tuned in to the recent MadeByGoogle stream. While it was hard not to be impressed with the demonstrations of Google’s AI prowess, I couldn’t help but be a little baffled…
What was the point of making everything AI-related?
Given how low Pixel’s market share is in the smartphone market, you’d think the focus ought to be on explaining why “normies” should buy the phone or find the price tag compelling, but instead every feature had to tie back to AI in some way.
Don’t get me wrong, AI is a compelling enabler of new technologies. Some of the call and photo functionalities are amazing, both as technological demonstrations but also in terms of pure utility for the user.
But, every product person learns early that customers care less about how something gets done and more about whether the product does what they want it too. And, as someone who very much wants a meaningful rival to Apple and Samsung, I hope Google doesn’t forget that either.
But while Google can call itself an AI company all it likes, people ultimately just want phones filled with useful features. At a certain point, it risks putting the AI technology cart in front of the feature horse.
At the same time, it poses some tricky ethical challenges:
How can you get informed, ethical consent to trial this? It’s nigh impossible to predict who will need a premature delivery.
In places like the US with limitations / controversy on reproductive rights, how do you push this forward without impacting assessments of “fetal viability” that may impact the abortion debate?
Great piece in Nature News below 👇🏻
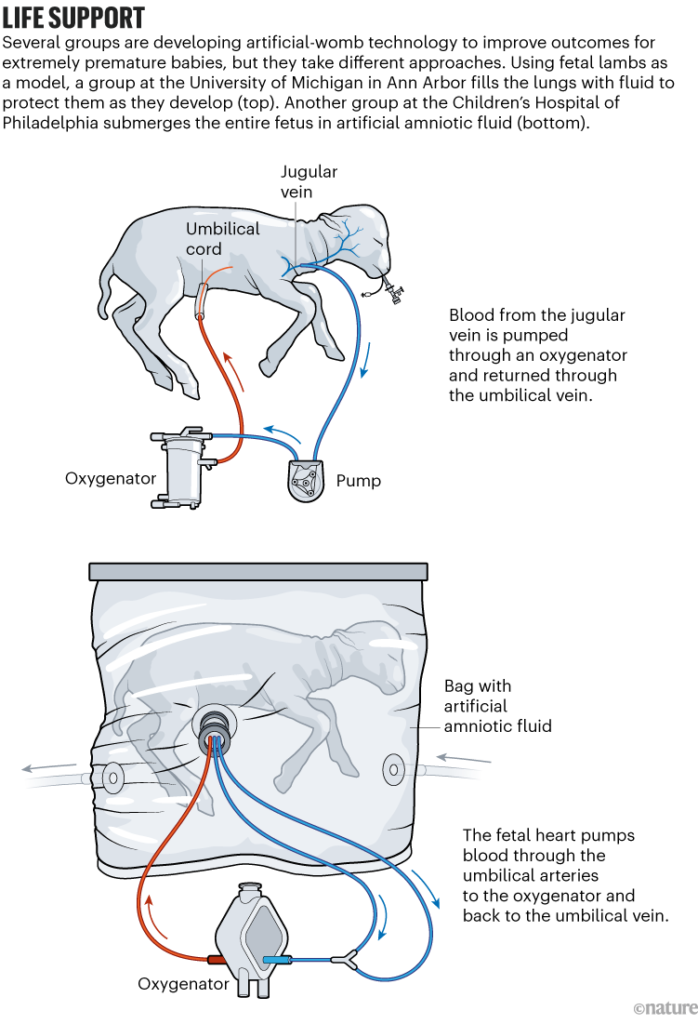
Now, the researchers at CHOP are seeking approval for the first human clinical trials of the device they’ve been testing, named the Extra-uterine Environment for Newborn Development, or EXTEND. The team has emphasized that the technology is not intended — or able — to support development from conception to birth. Instead, the scientists hope that simulating some elements of a natural womb will increase survival and improve outcomes for extremely premature babies. In humans, that’s anything earlier than 28 weeks of gestation — less than 70% of the way to full term, which is typically between 37 and 40 weeks.
The CHOP group has made bold predictions about the technology’s potential. In another 2017 video describing the project, Alan Flake, a fetal surgeon at CHOP who has been leading the effort, said: “If it’s as successful as we think it can be, ultimately, the majority of pregnancies that are predicted at-risk for extreme prematurity would be delivered early onto our system rather than being delivered premature onto a ventilator.” In 2019, several members of the CHOP team joined a start-up company, Vitara Biomedical in Philadelphia, which has since raised US$100 million to develop EXTEND. (Flake declined to comment for this article, citing “conflicts of interest” and “restrictions on proprietary information”. His co-authors on the 2017 paper did not respond to Nature’s request for comment.)
Unless you’ve been under a rock, you’ll know the tech industry has been rocked by the rapid advance in performance by large language models (LLMs) such as ChatGPT. By adapting self-supervised learning methods, LLMs “learn” to sound like a human being by learning how to fill in gaps in language and, by doing so, become remarkably adept at solving not just language problems but understanding & creativity.
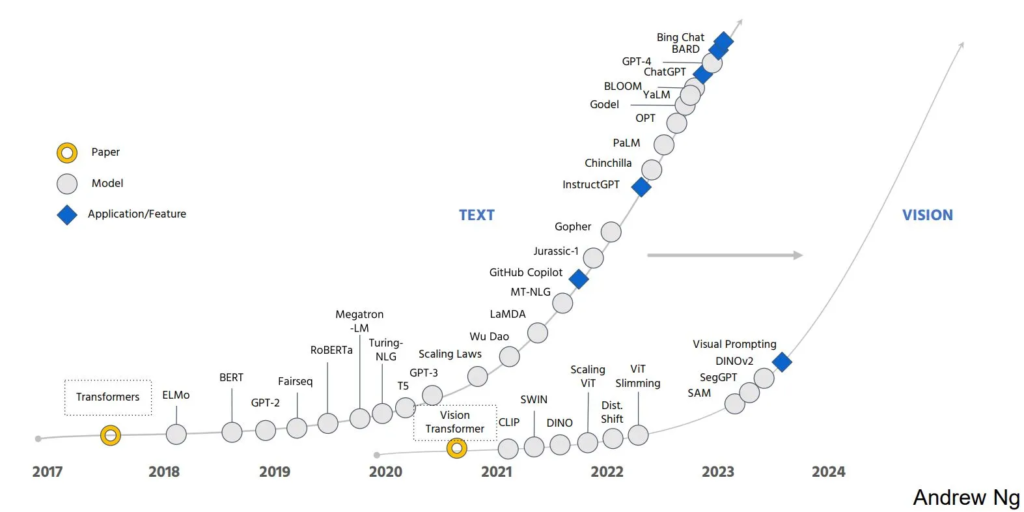
At a talk, Andrew Ng captured it well, by pointing out the parallels between the advances in language modeling that happened after the seminal Transformer paper and what is happening in the “large vision model” world with this great illustration.
“The revolution we’ve seen for text will be coming to images,” renowned computer scientist Andrew Ng asserted in a keynote talk he gave at the recent AI Hardware Summit here.
I have followed TSMC very closely since I started my career in the semiconductor industry. A brilliant combination of bold business bet (by founder Morris Chang), industry tailwinds (with the rise of fabless semiconductor model), forward-thinking from the Taiwanese government (who helped launch TSMC), and technological progress, it’s been fascinating to see the company enter the public consciousness.
In hearing about TSMC’s investment in the very aptly-named ESMC (European Semiconductor Manufacturing Company), I can’t help but think this is another brilliant TSMC-esque play. TSMC gets:
Guarantee outsized market share in leading edge semiconductor technology in Europe
Paid for in part by some of their largest customers (Infineon, Bosch, and NXP) who will likely commit / guarantee some of their volumes to fill this new manufacturing facility
AND (likely) additional subsidies / policy support from the European Union government (who increasingly doesn’t want to be left out of advanced chip manufacturing given Asia’s current dominance and the US’s Inflation Reduction Act push)
TSMC has managed to turn what could have been a disaster for them (growing nationalism in semiconductor manufacturing) into a subsidized, volume-committed factory.
TSMC, in collaboration with Bosch, Infineon and NXP, is planning to invest in the European Semiconductor Manufacturing Company (ESMC), based in Dresden, Germany. This strategic move aims to meet the burgeoning demand for advanced semiconductor-manufacturing services, particularly in the automotive and industrial sectors.
Three things are happening in video delivery world that are colliding here:
People are “cutting the cord” as they become less dependent on cable for high quality content (due to things like YouTube and Netflix)
Because you’ve lost the “cable bundle” economics (where cable subscribers would cross-subsidize each other’s viewing — you pay because you really want ESPN & I pay because I really want HBO and, as a result, we both end up paying less for more content), video streaming services like Disney+ inevitably increase prices & introduce ad models to cover their (very high) cost (of content production). This naturally means new bundles will emerge as consumers look to find ways to pay less for more content.
High speed internet today is largely subsidized by the investments from cable industry to deliver video. If ‘cord cutting’ (as in canceling cable) continues, then eventually the cost of high speed internet will go up as it becomes the “main event” for the company’s financials. Given (2), I think this likely means “cable companies” will increasingly become “bundled internet + streaming service” companies soon.
All this is ironically not that different from the original cable bundle, only this time we have a few new logos (i.e. Netflix) and a little more price transparency since you can see what the unsubsidized streaming video service cost (i.e. Disney+, Hulu, etc.) would be outside of the bundle.
Charter is taking a page from the book of Amazon and Apple, allowing you to essentially combine your bills. Do you have to get Spectrum cable because that’s the only internet provider in town? Well, soon, you might be able to bundle in your Hulu with Live TV service, too. Multiple services, one bill. That’s a step up from the HBO situation where you’ll have to cancel HBO and then go subscribe directly to Max if you want the pricier 4K version of that service.
One reason much of the modern produce we buy tastes so bland is because our agricultural system has bred modern varieties for ship-ability and the ability of produce to be picked by machine, rather than flavor.
While this has expanded the access to produce (both geographically but also in terms of cost due to the ability to use automation), it’s meant that consumers often have to choose between shelf life and good taste.
But, advances in plant genetics could change that. If we could understand the genes that are responsible for durability, that could inform how we breed or gene-edit varieties that can combine desirable taste attributes with durability.
Researchers in China published a paper in Nature Plants identifying the gene (fs8.1) responsible for making roma tomatoes elongated and crush-resistant enough to be machine-harvestable and even demonstrated that it would work in alternative varieties without changing their taste.
Both the paper and the Science article on it are worth checking out.
To confirm the strength of the fruit, the researchers squashed nearly 150 tomatoes in a laboratory press to measure their breaking points, a bit like a crash test for vehicles. “The juice spurts out like a bomb exploding,” Li says. Knocking out the gene did not alter the flavor of either TB0249 or Ailsa Craig.
Bloomberg had a great article over the weekend about the events leading up to the (partial) UAW strike against the Detroit Three (GM, Ford, and Stellantis [fka Chrysler]).
I’m not surprised (nor should anyone) by the strike. New UAW management, years-long grievances, and tight labor market favoring workers means a strike was almost certainly always going to be the first move by the UAW.
The bigger question is what this will do to the Detroit Three’s electrification push. The UAW’s challenge here (as it has been since the 80s) is that the Detroit Three are in a weak and uncertain position as it relates to foreign auto makers and new EV giants like Tesla. While the Inflation Reduction Act may give US auto makers the US EV market, going into a technology transition with a large labor cost & agility disadvantage is a surefire way to (continue to) cede the much larger global market which, in the end, hurts all of the US auto industry (not to mention the Biden administration’s hopes that this creates new jobs and centers green manufacturing in the US).
[UAW President] Fain will need to deliver agreements he can leverage into a more compelling case for workers at carmakers and battery companies the union hasn’t organized. Otherwise, Detroit risks starting the EV age in a position similar to the one they were in when the oil crisis hit half a century ago: stuck with labor costs that put Motor City companies at an untenable disadvantage.
“Breathing down the neck of the Big Three are the so-called foreign transplants and Tesla, which are eating up a bigger part of the market and remain unorganized,” said William Gould, a chair of the National Labor Relations Board under President Bill Clinton and professor emeritus at Stanford Law School. “That’s the Achilles’ heel of organized labor.”
This article in the Economist paints a dismal picture of the state of life for the youth in China: youth unemployment so high the government has stopped reporting on it (as if that was going to change anything…), housing and childcare costs so high that young people have given up on having traditional families, a government and state-run media that actively scolds them for being soft and pampered, and the best and brightest fleeing to Singapore…
How’s that “Chinese dream 中國夢” going?
Some 360m Chinese (a quarter of the population) are between the ages of 16 and 35. Their gloom has profound implications for the future of China, its economy and the party’s ambitions. But rather than soothe the young, the government tends to scold them. Last year Mr Xi said they must “abandon arrogance and pampering”. Editorials in state media encourage them to “embrace struggle” and sacrifice their youth to the cause of national rejuvenation, as defined by the party. Repression is increasing. “Eat bitterness,” Mr Xi tells youngsters. His admonition, though a worn Chinese cliché, is sure to strike a nerve
Last year, when a young man was told by police that the punishment for violating pandemic-control rules would affect his family for three generations, he responded, “We are the last generation, thank you.” The exchange, caught on video, went viral, his defiant words transformed into another cynical meme (until it was censored).
This is an older piece (written in 2016) but remarkable in how well it resonates even 7 years later.
Given that I have a home server and opinions on Matter/Thread, it shouldn’t be a surprise that I have many smart home gadgets in my house. And while I’ve made many purchasing and configuration choices in the spirit of this manifesto, it still boggles my mind that I still fall short of the seamless vision the writer (Paulus Schoutsen, founder of Home Assistant) lays out.
Home automation should blend with your current workflow, not replace it. For most devices, there is no faster way to control most devices than how you are already doing it today. Most of the time, the best app is no app.
When I first heard about the use of psychedelics (like ketamine and psilocybin) for treatment of mental illness, I was skeptical. It just seemed too ripe for abuse.
But, there is a growing body of credible academic work suggesting that psychedelics when dosed properly and used in conjunction with therapy / other drugs can be a gamechanger — especially for treatment-resistant depression and suicidality — and that is incredibly exciting.
At the same time, as a former telemedicine startup operator, this makes me more alarmed by the numerous companies working to commercialize these. In the bid for venture-style growth, it’s all too easy to lose track of the “when dosed properly and used in conjunction with therapy / other drugs” part.
In any event, this article from Medicine at Michigan is a good overview of the recent research highlights in the field and why so many clinicians and scientists are excited.
“Ketamine has properties that make you stop thinking of suicide,” Parikh says. “We now have this potential of treating someone who’s been suffering a while in acute suicidal risk, and within 1.5 hours of being in the emergency room, they are no longer suicidal.”