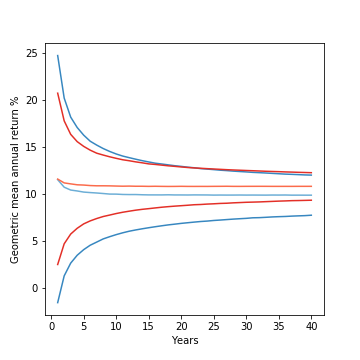
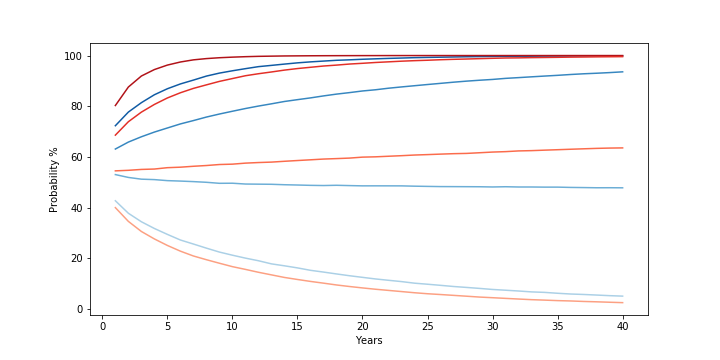
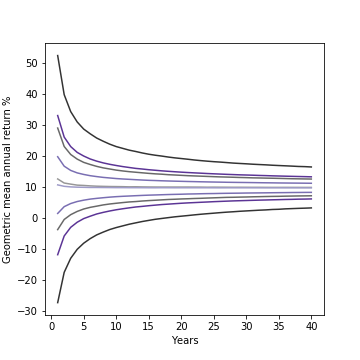
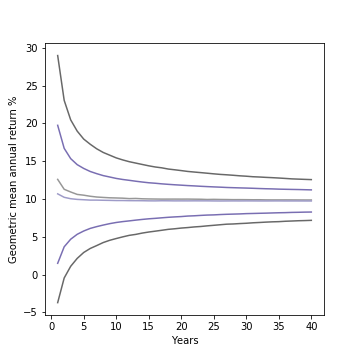
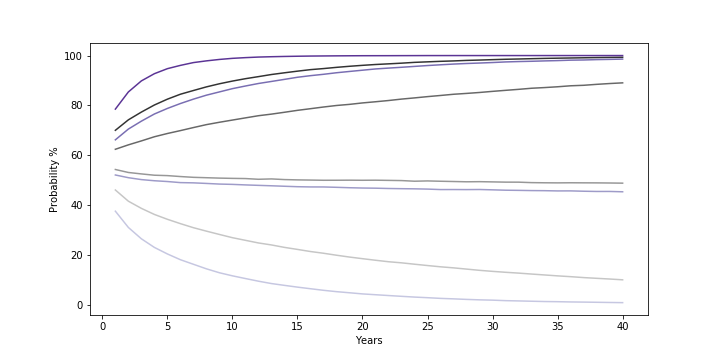
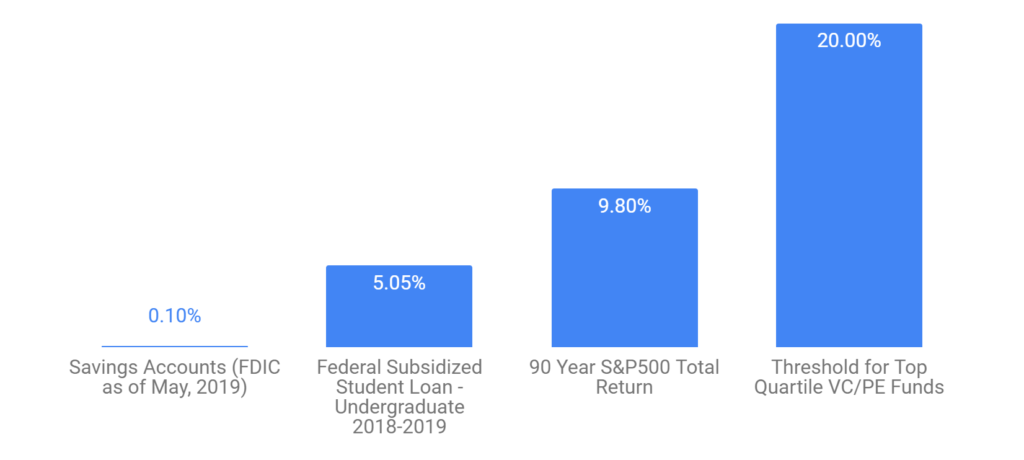
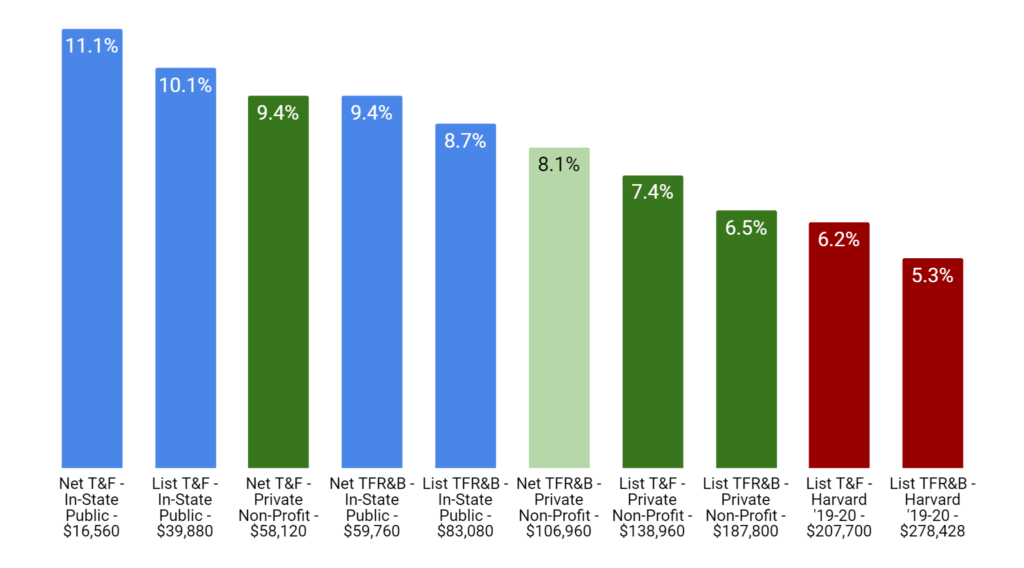
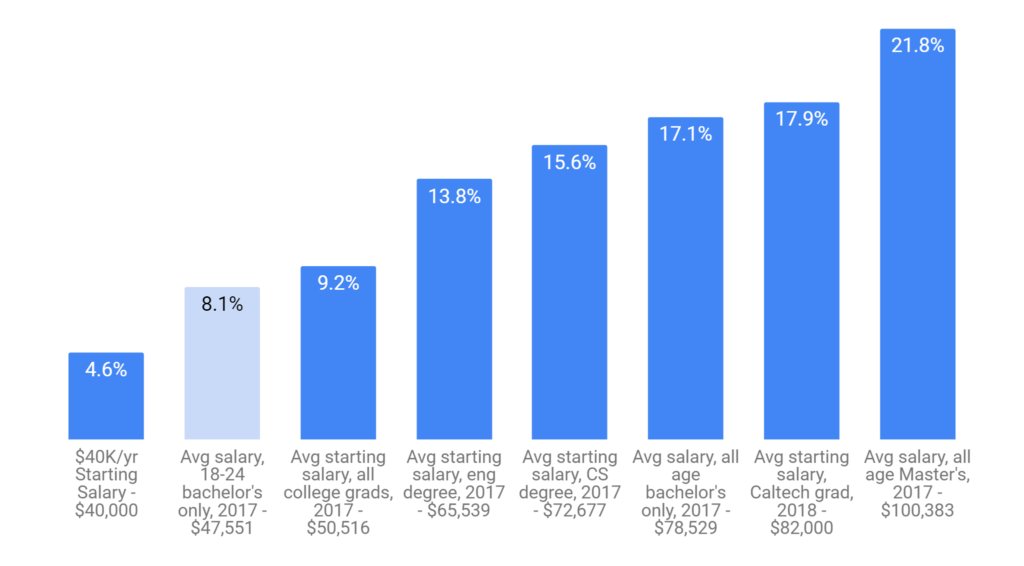
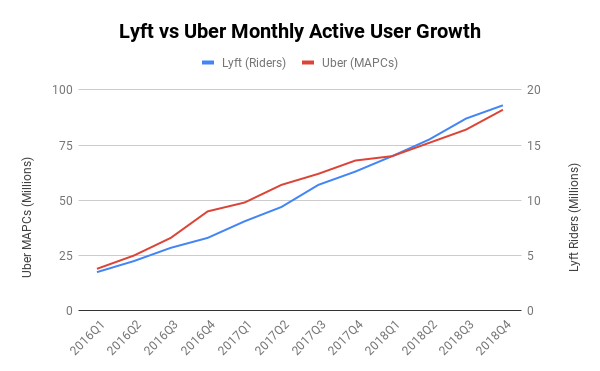
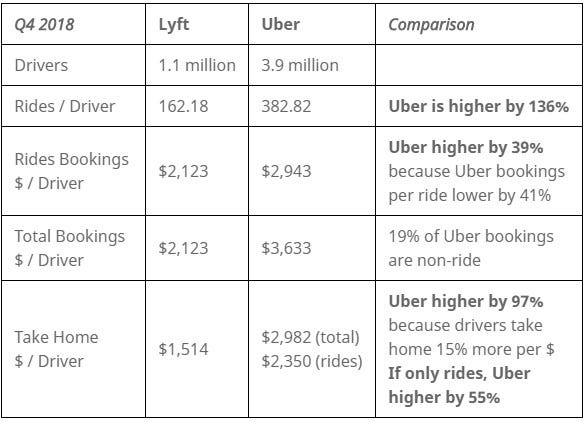
The fires in Maui have had a devastating human toll (111 dead, 1000 missing as of this writing). It is not surprising that it’s raising some questions about the role of Hawaii’s utility (Hawaiian Electric/HECO) played in the disaster.
Utilities now face three simultaneous problems (arguably of their own making):
climate change escalating the risks of catastrophic wildfires and storms
utilities across the country having aging energy infrastructure
homeownership patterns, disaster insurance coverage & premiums, and utility risk management plans built for a pre-climate-change risk environment
The smart ones will be proactively overhauling their processes and infrastructure to cope with this. The less smart ones will potentially be dragged kicking and screaming into this world in much the same way that PG&E and Hawaiian Electric currently are.
Hawaiian Electric is speaking with firms that specialize in restructuring advisory work, exploring options to address the electric utility’s financial and legal challenges arising from the Maui wildfires, said people familiar with the matter.
Hawaiian Electric is facing a selloff in its stock and bonds, and has been hit with lawsuits alleging that its actions both before and during the wildfires exacerbated the devastation Maui residents have suffered.
using Pihole as a local DNS server to have custom web addresses for software services running on your network and Nginx to handle port forwarding
Twingate (a better alternative to opening up a port and setting up Dynamic DNS to grant secure access to your network)
Pihole
Pihole is a lightweight localDNS server (it gets its name from the Raspberry Pi, a <$100 device popular with hobbyists, that it can run fully on).
A DNS (or Domain Name Server) converts human readable addresses (like www.google.com) into IP addresses (like 142.250.191.46). As a result, every piece of internet-connected technology is routinely making DNS requests when using the internet. Internet service providers typically offer their own DNS servers for their customers. But, some technology vendors (like Google and CloudFlare) also offer their own DNS services with optimizations on speed, security, and privacy.
A home-grown DNS server like Pihole can layer additional functionality on top:
DNS “filter” for ad / tracker blocking: Pihole can be configured to return dummy IP addresses for specific domains. This can be used to block online tracking or ads (by blocking the domains commonly associated with those activities). While not foolproof, one advantage this approach has over traditional ad blocking software is that, because this blocking happens at the network level, the blocking extends to all devices on the network (such as internet-connected gadgets, smart TVs, and smartphones) without needing to install any extra software.
DNS caching for performance improvements: In addition to the performance gains from blocking ads, Pihole also boosts performance by caching commonly requested domains, reducing the need to “go out to the internet” to find a particular IP address. While this won’t speed up a video stream or download, it will make content from frequently visited sites on your network load faster by skipping that internet lookup step.
Login to your OpenMediaVault web admin panel, go to [Services > Compose > Files], and press the button. Under Name put down Pihole and under File, adapt the following (making sure the number of spaces are consistent)
version: "3" services: pihole: container_name: pihole image: pihole/pihole:latest ports: - "53:53/tcp" - "53:53/udp" - "8000:80/tcp" environment: TZ: 'America/Los_Angeles' WEBPASSWORD: '<Password for the web admin panel>' FTLCONF_LOCAL_IPV4: '<your server IP address>' volumes: - '<absolute path to shared config folder>/pihole:/etc/pihole' - '<absolute path to shared config folder>/dnsmasq.d:/etc/dnsmasq.d' restart: unless-stopped
You’ll need to replace <Password for the web admin panel> with the password you’ll want to use to be access the Pihole web configuration interface, <your server IP address> with the static local IP address for your server, and <absolute path to shared config folder> with the absolute path to the config folder where you want Docker-installed applications to store their configuration information (accessible by going to [Storage > Shared Folders] in the administrative panel).
I live in the Bay Area so I set timezone TZ to America/Los_Angeles. You can find yours here.
Under Ports, I’ve kept the port 53 reservation (as this is the standard port for DNS requests) but I’ve chosen to map the Pihole administrative console to port 8000 (instead of the default of port 80 to avoid a conflict with the OpenMediaVault admin panel default). Note: This will prevent you from using Pihole’s default pi.hole domain as a way to get to the Pihole administrative console out-of-the-box. Because standard web traffic goes to port 80 (and this configuration has Pihole listening at port 8080), pi.hole would likely just direct you to the OpenMediaVault panel. While you could let pi.hole take over port 80, you would need to move OpenMediaVault’s admin panel to a different port (which itself has complexity). I ultimately opted with keeping OpenMediaVault at port 80 knowing that I could configure Pihole and Nginx proxy (see below) to redirect pi.hole to the right port.
You’ll notice this configures two volumes, one for dnsmasq.d, which is the DNS service, and one for pihole which provides an easy way to configure dnsmasq.d and download blocklists.
Note: the above instructions assume your home network, like most, is IPv4 only. If you have an IPv6 network, you will need to add an IPv6: True line under environment: and replace the FTLCONF_LOCAL_IPV4:'<server IPv4 address>' with FTLCONF_LOCAL_IPV6:'<server IPv6 address>'. For more information, see the official Pihole Docker instructions.
Once you’re done, hit Save and you should be returned to your list of Docker compose files for the next step. Notice that the new Pihole entry you created has a Down status, showing the container has yet to be initiated.
Disabling systemd-resolved: Most modern Linux operating systems include a built-in DNS resolver that listens on port 53 called systemd-resolved. Prior to initiating the Pihole container, you’ll need to disable this to prevent that port conflict. Use WeTTy (refer to the section Docker and OMV-Extras in my previous post) or SSH to login as the root user to your OpenMediaVault command line. Enter the following command:
nano /etc/systemd/resolved.conf
Look for the line that says #DNSStubListener=yes and replace it with DNSStubListener=no, making sure to remove the # at the start of the line. (Hit Ctrl+X to exit, Y to save, and Enter to overwrite the file). This configuration will tell systemd-resolved to stop listening to port 53.
To complete the configuration change, you’ll need to edit the symlink /etc/resolv.conf to point to the file you just edited by running:
sh -c 'rm /etc/resolv.conf && ln -s /etc/systemd/resolved.conf /etc/resolv.conf'
Now all that remains is to restart systemd-resolved:
systemctl restart systemd-resolved
How to start / update / stop / remove your Pihole container: You can manage all of your Docker Compose files by going to [Services > Compose > Files] in the OpenMediaVault admin panel. Click on the Pihole entry (which should turn it yellow) and press the (up) button. This will create the container, download any files needed, and, if you properly disabled systemd-resolved in the last step, initiate Pihole.
And that’s it! To prove it worked, go to your-server-ip:8000 in a browser and you should see the login for the Pihole admin webpage (see below). From time to time, you’ll want to update the container. OMV makes this very easy. Every time you press the (pull) button in the [Services > Compose > Files] interface, Docker will pull the latest version (maintained by the Pihole team).
Now that you have Pihole running, it is time to enable and configure it for your network.
Test Pihole from a computer: Before you change your network settings, it’s a good idea to make sure everything works.
On your computer, manually set your DNS service to your Pihole by putting in your server IP address as the address for your computer’s primary DNS server (Mac OS instructions; Windows instructions; Linux instructions). Be sure to leave any alternate / secondary addresses blank (many computers will issue DNS requests to every server they have on their list and if an alternative exists you may not end up blocking anything).
(Temporarily) disable any ad blocking service you may have on your computer / browser you want to test with (so that this is a good test of Pihole as opposed to your ad blocking software). Then try to go to https://consumerproductsusa.com/ — this is a URL that is blocked by default by Pihole. If you see a very spammy website promising rewards, either your Pihole does not work or you did not configure your DNS correctly.
Finally login to the Pihole configuration panel (your-server-ip:8000) using the password you set up during installation. From the dashboard click on the Queries Blocked box at the top (your colors may vary but it’s the red box on my panel, see below). On the next screen, you should see the domain consumerproductsusa.com next to the IP address of your computer, confirming that the address was blocked. You can now turn your ad blocking software back on!
You should now set the DNS service on your computer back to “automatic” or “DHCP” so that it will inherit its DNS settings from the network/router (and especially if this is a laptop that you may use on another network).
Configure DNS on router: Once you’ve confirmed that the Pihole service works, you should configure the default DNS settings on your router to make Pihole the DNS service for your entire network. The instructions for this will vary by router manufacturer. If you use Google Wifi as I do, here are the instructions.
Once this is completed, every device which inherits DNS settings from the router will now be using Pihole for their DNS requests.
Note: one downside of this approach is that the Pihole becomes a single point of failure for the entire network. If the Pihole crashes or fails, for any reason, none of your network’s DNS requests will go through until the router’s settings are changed or the Pihole becomes functional again. Pihole generally has good reliability so this is unlikely to be an issue most of the time, but I am currently using Google’s DNS as a fallback on my Google Wifi (for the times when something goes awry with my server) and I would also encourage you to know how to change the DNS settings for your router in case things go bad so that your access to the internet is not taken out unnecessarily.
Configure Pihole: To get the most out of Pihole’s ad blocking functionality, I would suggest three things
Select Good Upstream DNS Servers: From the Pihole administrative panel, click on Settings. Then select the DNS tab. Here, Pihole allows you to configure which external DNS services the DNS requests on your network should go to if they aren’t going to be blocked and haven’t yet been cached. I would recommend selecting the checkboxes next to Google and Cloudflare given their reputations for providing fast, secure, and high quality DNS services (and selecting multiple will provide redundancy).
Update Gravity periodically: Gravity is the system by which Pihole updates its list of domains to block. From the Pihole administrative panel, click on [Tools > Update Gravity] and click the Update button. If there are any updates to the blocklists you are using, these will be downloaded and “turned on”.
Configure Domains to block/allow: Pihole allows administrators to granularly customize the domains to block (blacklist) or allow (whitelist). From the Pihole administrative panel, click on Domains. Here, an admin can add a domain (or a regular expression for a family of domains) to the blacklist (if it’s not currently blocked) or the whitelist (if it currently is) to change what happens when a user on the network accesses the DNS.
I added whitelist exclusions for link.axios.com to let me click through links from the Axios email newsletters I receive and www.googleadservices.com to let my wife click through Google-served ads. Pihole also makes it easy to manually take a domain that a device on your network has requested to block/allow. Tap on Total Queries from the Pihole dashboard, click on the IP address of the device making the request, and you’ll see every DNS request (including those which were blocked) with a link beside them to add to the domain whitelist or blacklist.
Pihole will also allow admins to configure different rules for different sets of devices. This can be done by calling out clients (which can be done by clicking on Clients and picking their IP address / MAC address / hostnames), assigning them to groups (which can be defined by clicking on Groups), and then configuring domain rules to go with those groups (in Domains). Unfortunately because Google Wifi simply forwards DNS requests rather than distributes them, I can only do this for devices that are configured to directly point at the Pihole, but this could be an interesting way to impose parental internet controls.
Now you have a Pihole network-level ad blocker and DNS cache!
Local DNS and Nginx proxy
As a local DNS server, Pihole can do more than just block ads. It also lets you create human readable addresses for services running on your network. In my case, I created one for the OpenMediaVault admin panel (omv.home), one for WeTTy (wetty.home), and one for Ubooquity (ubooquity.home).
If your setup is like mine (all services use the same IP address but different ports), you will need to set up a proxy as DNS does not handle port forwarding. Luckily, OpenMediaVault has Nginx, a popular web server with a performant proxy, built-in. While many online tutorials suggest installing Nginx Proxy Manager, that felt like overkill, so I decided to configure Nginx directly.
To get started:
Configure the A records for the domains you want in Pihole: Login to your Pihole administrative console (your-server-ip:8000) and click on [Local DNS > DNS Records] from the sidebar. Under the section called Add a new domain/IP combination, fill out the Domain: you want for a given service (like omv.home or wetty.home) and the IP Address: (if you’ve been following my guides, this will be your-server-ip). Press the Add button and it will show up below. Repeat for all the domains you want. If you have a setup similar to mine, you will see many domains pointed at the same IP address (because the different services are simply different ports on my server).
To test if these work, enter any of the domains you just put in to a browser and it should take you to the login page for the OpenMediaVault admin panel (as currently they are just pointing at your server IP address).
Note 1: while you can generally use whatever domains you want, it is suggested that you don’t use a TLD that could conflict with an actual website (i.e. .com) or that are commonly used by networking systems (i.e. .local or .lan). This is why I used .home for all of my domains (the IETF has a list they recommend, although it includes .lan which I would advise against as some routers such as Google Wifi use this)
Note 2: Pihole itself automatically tries to forward pi.hole to its web admin panel, so you don’t need to configure that domain. The next step (configuring proxy port forwarding) will allow pi.hole to work.
Edit the Nginx proxy configuration: Pihole’s Local DNS server will send users looking for one of the domains you set up (i.e. wetty.home) to the IP address you configured. Now you need your server to forward that request to the appropriate port to get to the right service.
You can do this by taking advantage of the fact that Nginx, by default, will load any .conf file in the /etc/nginx/conf.d/ directory as a proxy configuration. Pick any file name you want (I went with dothome.conf because all of my service domains end with .home) and after using WeTTy or SSH to login as root, run:
nano /etc/nginx/conf.d/<your file name>.conf
The first time you run this, it will open up a blank file. Nginx looks at the information in this file for how to redirect incoming requests. What we’ll want to do is tell Nginx that when a request comes in for a particular domain (i.e. ubooquity.home or pi.hole) that request should be sent to a particular IP address and port.
Manually writing these configuration files can be a little daunting and, truth be told, the text file I share below is the result of a lot of trial and error, but in general there are 2 types of proxy commands that are relevant for making your domain setup work.
One is a proxy_pass where Nginx will basically take any traffic to a given domain and just pass it along (sometimes with additional configuration headers). I use this below for wetty.home, pi.hole, ubooquityadmin.home, and ubooquity.home. It worked without the need to pass any additional headers for WeTTy and Ubooquity, but for pi.hole, I had to set several additional proxy headers (which I learned from this post on Reddit).
The other is a 301 redirect where you tell the client to simply forward itself to another location. I use this for ubooquityadmin.home because the actual URL you need to reach is not / but /admin/ and the 301 makes it easy to setup an automatic forward. I then use the regex match ~ /(.*)$ to make sure every other URL is proxy_pass‘d to the appropriate domain and port.
You’ll notice I did not include the domain I configured for my OpenMediaVault console (omv.home). That is because omv.home already goes to the right place without needing any proxy to port forward.
If you are using other domains, ports, or IP addresses, adjust accordingly. Be sure all your curly braces have their mates ({}) and that each line ends with a semicolon (;) or Nginx will crash. I use Tab‘s between statements (i.e. between listen and 80) to format them more nicely but Nginx will accept any number or type of whitespace.
To test if your new configuration worked, save your changes (hit Ctrl+X to exit, Y to save, and Enter to overwrite the file if you are editing a pre-edited one). In the command line, run the following command to restart Nginx with your new configuration loaded.
systemctl restart nginx
Try to login to your OpenMediaVault administrative panel in a browser. If that works, it means Nginx is up and running and you at least didn’t make any obvious syntax errors!
Next try to access one of the domains you just configured (for instance pi.hole) to test if the proxy was configured correctly.
If either of those steps failed, use WeTTy or SSH to log back in to the command line and use the command above to edit the file (you can delete everything if you want to start fresh) and rerun the restart command after you’ve made changes to see if that fixes it. It may take a little bit of doing if you have a tricky configuration but once you’re set, everyone on the network can now use your configured addresses to access the services on your network.
The work required to set up each device for Wireguard is quite involved (you have to configure it on the VPN server and then pass credentials to the device via QR code or file)
It requires me to open up a port on my router for external traffic (a security risk) and maintain a Dynamic DNS setup that is vulnerable to multiple points of failure and could make changing domain providers difficult.
Simple graphical configuration of which resources should be made available to which devices
Easier to use client software with secure (but still easy to use) authentication
No need to configure Dynamic DNS or open a port
Support for local DNS rules (i.e. the domains I configured in Pihole)
I was intrigued (it didn’t hurt that Twingate has a generous free Starter plan that should work for most home server setups). To set up Twingate to enable remote access:
Create a Twingate account and Network: Go to their signup page and create an account. You will then be asked to set up a unique Network name. The resulting address, <yournetworkname>.twingate.com, will be your Network configuration page from where you can configure remote access.
Add a Remote Network: Click the Add button on the right-hand-side of the screen. Select On Premise for Location and enter any name you choose (I went with Home network).
Add Resources: Select the Remote Network you just created (if you haven’t already) and use the Add Resource button to add an individual domain name or IP address and then grant access to a group of users (by default, it will go to everyone).
With my configuration, I added 5 domains (pi.hole + the four .home domains I configured through Pihole) and 1 IP address (for the server, to handle the ubooquityadmin.home forwarding and in case there was ever a need to access an additional service on my server that I had not yet created a domain for).
Install Connector Docker Container: To make the selected network resources available through Twingate requires installing a Twingate Connector to something internet-connected on the network.
Press the Deploy Connector button on one of the connectors on the right-hand-side of the Remote Network page (mine is called flying-mongrel). Select Docker in Step 1 to get Docker instructions (see below). Then press the Generate Tokens button under Step 2 to create the tokens that you’ll need to link your Connector to your Twingate network and resources. With the Access Token and Refresh Token saved, you are ready to configure Docker to install. Login to the OpenMediaVault administrative panel and go to [Services > Compose > Files] and press the button. Under Name put down Twingate Connector and under File, enter the following (making sure the number of spaces are consistent)
You’ll need to replace <your network name> with the name of the Twingate network you created, <your connector access token> and <your connector refresh token> with the access token and refresh token generated from the Twingate website. Do not add any single or double quotation marks around the network name or the tokens as they will result in a failed authentication with Twingate (as I was forced to learn through experience).
Once you’re done, hit Save and you should be returned to your list of Docker compose files. Click on the entry for Twingate Connector you just created and then press the (up) button to initialize the container.
Go back to your Twingate network page and select the Remote Network your Connector is associated with. If you were successful, within a few moments, the Connector’s status will reflect this (see below for the before and after). If, after a few minutes there is still no change, you should check the container logs. This can be done by going to [Services > Compose > Services] in the OpenMediaVault administrative panel. Select the Twingate Connector container and press the (logs) button in the menubar. The TWINGATE_LOG_LEVEL=7 setting in the Docker configuration file sets the Twingate Connector to report all activities in great detail and should give you (or a helpful participant on the Twingate forum) a hint as to what went wrong.
Add Users and Install Clients: Once the configuration is done and the Connector is set up, all that remains is to add user accounts and install the Twingate client software on the devices that should be able to access the network resources.
Users can be added (or removed) by going to your Twingate network page and clicking on the Team link in the menu bar. You can Add User (via email) or otherwise customize Group policies. Be mindful of the Twingate Starter plan limit to 5 users…
As for the devices, the client software can be found at https://get.twingate.com/. Once installed, to access the network, the user will simply need to authenticate.
Remove my old VPN / Dynamic DNS setup. This is not strictly necessary, but if you followed my instructions from before, you can now undo those by:
Closing the port you opened from your Router configuration
Disabling Dynamic DNS setup from your domain provider
“Down”-ing and deleting the container and configuration file for DDClient (you can do this by going to [Services > Compose > Files] from OpenMediaVault admin panel)
Deleting the configured Wireguard clients and tunnels (you can do this by going to [Services > Wireguard] from the OpenMediaVault admin panel) and then disabling the Wireguard plugin (go to [System > Plugins])
Removing the Wireguard client from my devices
And there you have it! A secure means of accessing your network while retaining your local DNS settings and avoiding the pitfalls of Dynamic DNS and opening a port.
Resources
There were a number of resources that were very helpful in configuring the above. I’m listing them below in case they are helpful:
Stop me if you’ve heard this one before… Adoption of a technology is being impeded by too many standards. The solution? A new standard, of course, and before you know it, we now have another new standard to deal with.
The smart home industry needs to figure out how to properly embrace Thread (and Matter). It (or something like it) will be necessary for broader smart home / Internet of Things adoption.
The Thread protocol offers a robust mesh network designed to solve many of the smart home’s biggest problems. But only if everyone can agree on how to use it.
As a former “Excel monkey”, I am extremely tickled by the fact that what used to be analyst bravado about Excel skills (being able to create big spreadsheet models without touching the mouse was a big thing) is now a sport with viewers.
But it’s a testament to how powerful and versatile spreadsheets are. And how many people know what it is.
The joke in SaaS is that every SaaS product is basically competing with Excel. Well, apparently, Excel’s competing with e-sports and games now too!
This year, there’s a new wrinkle: it’s an elimination race. Every five minutes, the player with the fewest points will be eliminated until there’s only one Excel-er remaining. “We have already shot the game,” says Andrew Grigolyunovich, the founder and CEO of the Financial Modeling World Cup, the organization that oversees the event. It’s now being edited down for ESPN consumption, he says, and the whole match will come out on Friday as well. “It’s a really fun, exciting event.”
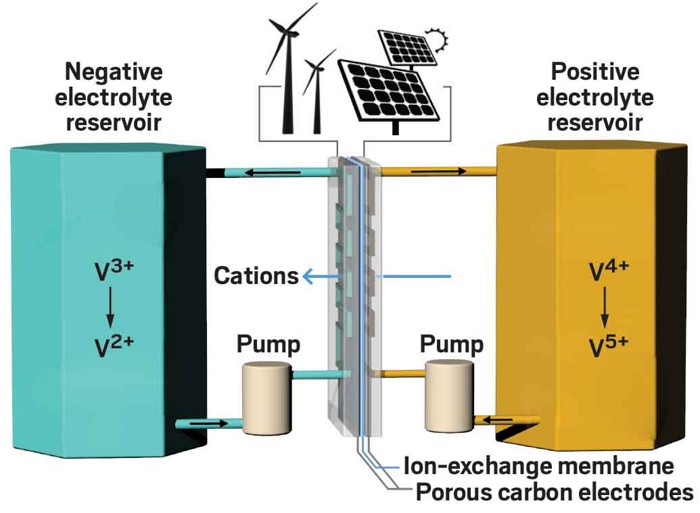
I’ve been pitched by numerous flow battery companies in my days as a deeptech/climatetech investor. The promise of the technology has always been:
Long cycle life (the number of charge-discharge cycles you can do before the performance degrades)
Easy to scale: you want 2x the storage? Just get 2x the electrolyte!
Low fire risk: most flow batteries use water-based electrolytes which won’t ignite in the air (the way the lithium in lithium-ion batteries do)
Despite compelling benefits, this category never achieved the level of success or scale as lithium-ion did. This was due in part to a variety of technological limitations (poor energy density, lower cycle efficiency, concerns around the amount of Vanadium-containing electrolyte “lying around” in a system, etc). But, the main cause was the breath-taking progress lithium-ion batteries have made in cost, energy density, and safety driven first by consumer electronics demand and then by electric vehicle demand.
This C&EN article covers the renewed optimism the flow battery world is experiencing as market interest in the technology revitalizes.
My hot-take🔥: while technological improvements play a part, once again, what is driving the flow battery market is what’s happening in lithium-ion world. There simply is too much demand for energy storage and growing uncertainty about the ability of lithium-ion to handle it in the face of the conflict between the West and China (the leading supplier of lithium ion batteries) and supply chain concerns about critical minerals for lithium ion batteries (like nickel and cobalt). Grid storage players have to look elsewhere. (Electric vehicle companies would probably like to but do not have the option!)
Considering the importance of grid energy storage in electrifying our world and onboarding new renewable generation, I think having and seeing more options is a good thing. So I, too, am optimistic here 👍🏻
Note: this is the first in a (hopefully ongoing) series of posts called “What I’m Reading” where I’ll share & comment on an interesting article I’ve come across!
Redox flow batteries have a reputation of being second best. Less energy intensive and slower to charge and discharge than their lithium-ion cousins, they fail to meet the performance requirements of snazzy, mainstream applications, such as cars and cell phones. There’s no such thing as a flow-battery Tesla.
But the companies at the International Flow Battery Forum in Prague in late June were adamant that flow batteries are now cheaper, more reliable, and safer than lithium ion in a growing number of real-world stationary energy applications. Flow-battery makers say their technology—and not lithium ion—should be the first choice for capturing excess renewable energy and returning it when the sun is not out and the wind is not blowing.
VPN — lets me connect to my storage and media server when I’m outside of my home
Until about a week ago, I had run a Plex media server on my aging (8 years old!) NVIDIA SHIELD TV. While I loved the device, it was starting to show it’s age – it would sometimes overheat and not boot for several days. My home technology setup had also shifted. I bought the SHIELD all those years ago to put Android TV functionality onto my “dumb” TV.
But, about a year ago, I upgraded to a newer Sony TV which had it built-in. Now, the SHIELD felt “extra” and the media server felt increasingly constrained by what it could not do (e.g., slow network access speeds, can only run services that are Android apps, etc.)
I considered buying a high-end consumer NAS from Synology or QNAP (which would have been much simpler!), but decided to build my own to both get better hardware for less money but also as a fun project which would teach me more about servers and let me configure everything to my heart’s content.
If you’re interested in doing something similar, let me walk you through my hardware choices and the steps I took to get to my current home server setup.
Note: on the recommendation of a friend, I’ve since reconfigured how external access works to not rely on a VPN with an open port and Dynamic DNS and instead use Twingate. For more information, refer to my post on Setting Up Pihole, Nginx Proxy, and Twingate with OpenMediaVault
Hardware
I purchased a Beelink EQ12 Mini, a “mini PC” (fits in your hand, power-efficient, but still capable of handling a web browser, office applications, or a media server), during Amazon’s Prime Day sale for just under $200.
While I’m very happy with the choice I made, for those of you contemplating something similar, the exact machine isn’t important. Many of the mini PC brands ultimately produce very similar hardware, and by the time you read this, there will probably be a newer and better product. But, I chose this particular model because:
It was from one of the more reputable Mini PC brands which gave me more confidence in its build quality (and my ability to return it if something went wrong). Other reputable vendors beyond Beelink include Geekom, Minisforum, Chuwi, etc.
It had a USB-C port which helps with futureproofing, and the option to convert this into something else useful if this server experiment doesn’t work out.
It had an Intel CPU. While AMD makes excellent CPUs, the benefit of going with Intel is support for Intel Quick Sync, which allows for hardware accelerated video transcode (converting video and audio streams to different formats and resolutions – so that other devices can play them – without overwhelming the system or needing a beefy graphics card). Many popular media servers support Intel Quick Sync-powered transcode.
It was not a i3/5/7/9 chip. Intel’s higher end chips have names that include “i3” or “i5” or “i7”. Those are generally overkill on performance, power consumption, and price for a simple file and media server. All I needed for my purposes was a lower-end Celeron-type device.
It was the most advanced Intel architecture I could find for ≤$200. While I didn’t need the best performance, there was no reason to avoid more advanced technology. Thankfully, the N100 chip in the EQ12 Mini uses Intel’s 12th Generation Core architecture (Alder Lake). Many of the other mini-PCs at this price range had older (10th and 11th generation) CPUs.
I went with the smallest RAM and onboard storage option. I wasn’t planning on putting much on the included storage (because you want to isolate the operating system for the server away from the data) nor did I expect to tax the computer memory for my use case.
I also considered purchasing a Raspberry Pi, a <$100 low-power device popular with hobbyists, but the lack of transcode and the non-x86 architecture (Raspberry Pi’s use ARM CPUs and won’t be compatible with all server software) pushed me towards an Intel-based mini PC.
In addition to the mini-PC, I also needed:
Storage: a media server / NAS without storage is not very useful. I had a 4 TB USB hard drive (previously connected to my SHIELD TV) which I used here, and I also bought a 4 TB SATA SSD (for ~$150) to mount inside the mini-PC.
Note 1: if you decide to go with OpenMediaVault as I have, install the Linux distribution before you install the SATA drive. The installer (foolishly) tries to install itself to the first drive it finds, so don’t give it any bad options.
Note 2: most Mini PC manufacturers say their systems only support additional drives up to 2 TB. This appears to be mainly the manufacturers being overly conservative. My 4 TB SATA SSD works like a charm.
A USB stick: Most Linux distributions (especially those that power open source NAS solutions) are installed from a bootable USB stick. I used one that was lying around that had 2 GB on it.
Ethernet cables and a “dumb” switch: I use Google Wifi in my home and I wanted to connect both my TV and my new media server to the router in my living room. To do that, I bought a simple Ethernet switch (you don’t need anything fancy because it’s just bridging several devices) and 3 Ethernet cables to tie it all together (one to connect the router to the switch, one to connect the TV to the switch, and one to connect the server to the switch). Depending on your home configuration, you may want something different.
A Monitor & Keyboard: if you decide to go with OpenMediaVault as I have, you’ll only need this during the installation phase as the server itself is controllable through a web interface. So, I used an old keyboard and monitor (that I’ve since given away).
OpenMediaVault
There are a number of open source home server / NAS solutions you can use. But I chose to go with OpenMediaVault because it’s:
built on Debian (a well-supported, widely used flavor of Linux)
Plug the USB stick into the mini PC (and make sure to connect the monitor and keyboard) and then turn the machine on. If it goes to Windows (i.e. it doesn’t boot from your USB stick), you’ll need to restart and go into BIOS (you can usually do this by pressing Delete or F2 or F7 after turning on the machine) to configure the machine to boot from a USB drive.
You should pick a good root password and write it down (it gates administrative access to the machine, and you’ll need it to make some of the changes below).
You can pick pretty much any name you want for the hostname and domain name (it shouldn’t affect anything but it will be what your machine calls itself).
Make sure to select the right drive for installation
And that should be it! After you complete the installation, you will be prompted to enter the root password you created to login.
Unfortunately for me, OpenMediaVault did not recognize my mini PC’s ethernet ports or wireless card. If it detects your network adapter just fine, you can skip this next block of steps. But, if you run into this, select the “does not have network card” option and “minimal setup” options during install. You should still be able to get the end of the process. Then, once the OpenMediaVault operating system installs and reboots:
Login by entering the root password you picked during the installation and make sure your system is plugged in to your router via ethernet. Note: Linux is known to have issues recognizing some wireless cards and it’s considered best practice to run a media server off of Ethernet rather than WiFi.
In the command line, enter omv-firstaid. This is a gateway to a series of commonly used tools to fix an OpenMediaVault install. In this case, select the Configure Network Interface option and say yes to all the IPv4 DHCP options (you can decide if you want to set up IPv6).
Step 2 should fix the issue where OpenMediaVault could not see your internet connection. To prove this, you should try two things:
Enter ping google.com -c 3 in the command line. You should see 3 lines with something like 64 bytes from random-url.blahurl.net showing that your system could reach Google (and thus the internet). If it doesn’t work, try again in a few minutes (sometimes it takes some time for your router to register a new system).
Enter ip addr in the command line. Somewhere on the screen, you should see something that probably looks like inet 192.168.xx.xx/xx. That is your local IP address and it’s a sign that the mini PC has connected to your router.
Now you need to update the Linux operating system so that it knows where to look for updates to Debian. As of this writing, the latest version of OpenMediaVault (6) is based on Debian 11 (codenamed Bullseye), so you may need to replace bullseye with <name of Debian codename that your OpenMediaVault is based on> in the text below if your version is based on a different version of Debian (i.e. Bookworm, Trixie, etc.).
In the command line, enter nano /etc/apt/sources.list. This will let you edit the file that contains all the information on where your Linux operating system will find valid software updates. Enter the text below underneath all the lines that start with # (replacing bullseye with the name of the Debian version that underlies your version of OpenMediaVault if needed).
deb http://deb.debian.org/debian bullseye main deb-src http://deb.debian.org/debian bullseye main deb http://deb.debian.org/debian-security/ bullseye-security main deb-src http://deb.debian.org/debian-security/ bullseye-security main deb http://deb.debian.org/debian bullseye-updates main deb-src http://deb.debian.org/debian bullseye-updates main
Then press Ctrl+X to exit, press Y when asked if you want to save your changes, and finally Enter to confirm that you want to overwrite the existing file.
To prove that this worked, in the command line enter apt-get update and you should see some text fly by that includes some of the URLs you entered into sources.list. Next enter apt-get upgrade -y, and this should install all the updates the system found.
Congratulations, you’ve installed OpenMediaVault!
Setting up the File Server
You should now connect any storage (internal or USB) that you want to use for your server. You can turn off the machine if you need to by pulling the plug, or holding the physical power button down for a few seconds, or by entering shutdown now in the command line. After connecting the storage, turn the system back on.
Once setup is complete, OpenMediaVault can generally be completely controlled and managed from the web. But to do this, you need your server’s local IP address. Log in (if you haven’t already) using the root password you set up during the installation process. Enter ip addr in the command line. Somewhere on the screen, you should see something that looks like inet 192.168.xx.xx/xx. That set of numbers connected by decimal points but before the slash (for example: 192.168.444.23) is your local IP address. Write that down.
Now, go into any other computer connected to the same network (i.e. on WiFi or plugged into the router) as the media server and enter the local IP address you wrote down into the address bar of a browser. If you configured everything correctly, you should see something like this (you may have to change the language to English by clicking on the globe icon in the upper right):
The OpenMediaVault administrative panel login
Congratulations, you no longer need to connect a keyboard or mouse to your server, because you can manage it from any other computer on the network!
Login using the default username admin and default password openmediavault. Below are the key things to do first. (Note: after hitting Save on a major change, as an annoying extra precaution, OpenMediaVault will ask you to confirm the change again with a bright yellow confirmation banner at the top. You can wait until you have several changes, but you need to make sure you hit the check mark at least once or your changes won’t be reflected):
Change your password: This panel controls the configuration for your system, so it’s best not to let it be the default. You can do this by clicking on the (user settings) icon in the upper-right and selecting Change Password
Some useful odds & ends:
Make auto logout (time before the panel logs you out automatically) longer. You can do this by going to [System > Workbench] in the menu and changing Auto logout to something like 60 minutes
Set the system timezone. You can do this by going to [System > Date & Time] and changing the Time zone field.
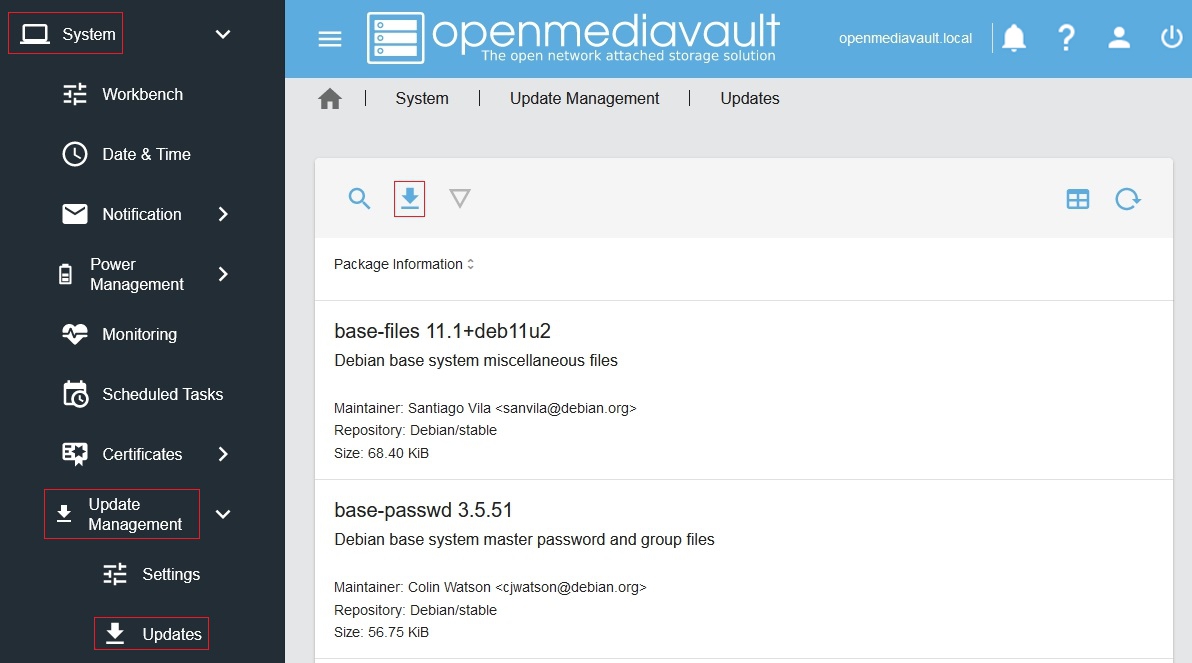
Update the software: On the left-hand side, select [System > Update Management > Updates]. Press the button to search for new updates. If any show up press the button to install everything on the list that it can. (see below, Image credit: OMV-extras Wiki)
Mount your storage:
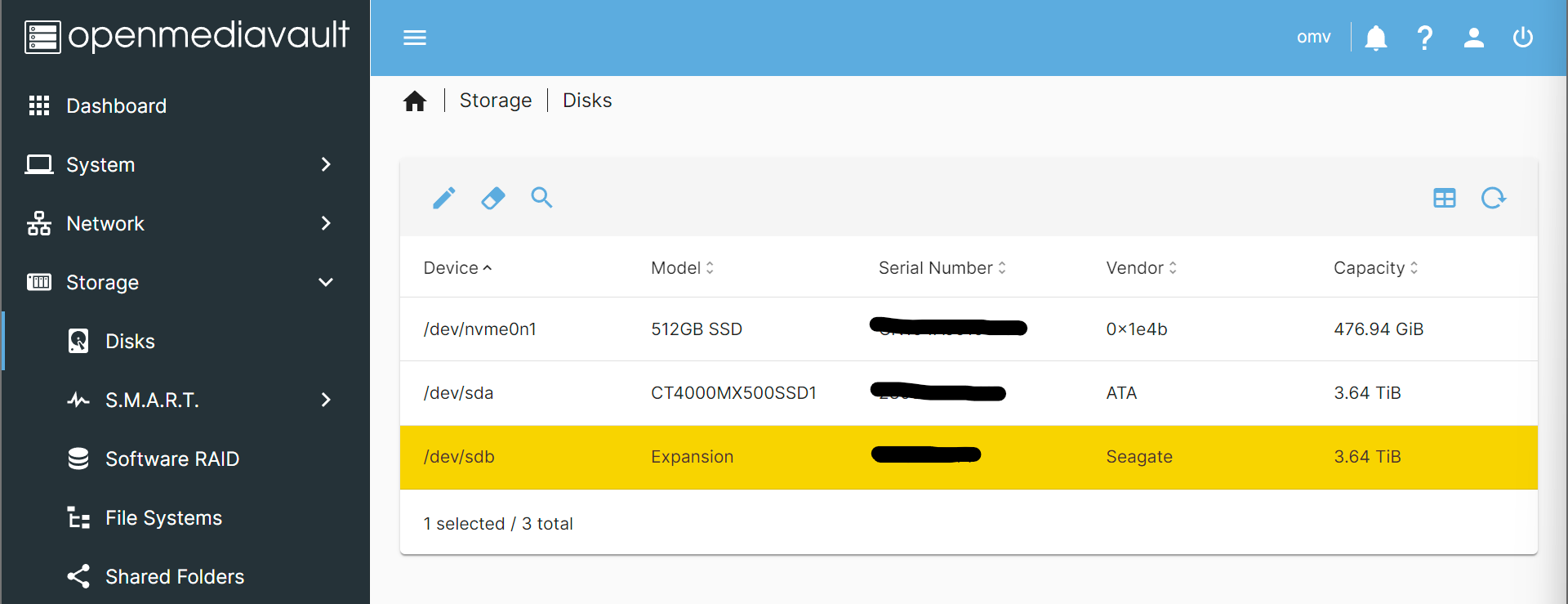
From the menu, select [Storage > Disks]. The table that results (see below) shows everything OpenMediaVault sees connected to your server. If you’re missing anything, time to troubleshoot (check the connection and then make sure the storage works on another computer).
It’s a good idea (although not strictly necessary) to reformat any un-empty disks before using them with OpenMediaVault for performance. You can do this by selecting the disk entry (marking it yellow) and then pressing the (Wipe) button
Go to [Storage > File Systems]. This shows what drives (and what file systems) are accessible to OpenMediaVault. To properly mount your storage:
Press the button for every unformatted drive added you may want to mount to OpenMediaVault. This will add a disk with an existing file system to the purview of your file server.
Press the button in the upper-left (just to the right of the triangular button) to add a drive that’s just been formatted. Of the file system options that come up, I would choose EXT4 (it’s what modern Linux operating systems tend to use). This will result in your chosen file system being added to the drive before it’s ultimately mounted.
Set up your File Server: Ok, you’ve got storage! Now you want to make it available for the computers on your network. To do this, you need to do three things:
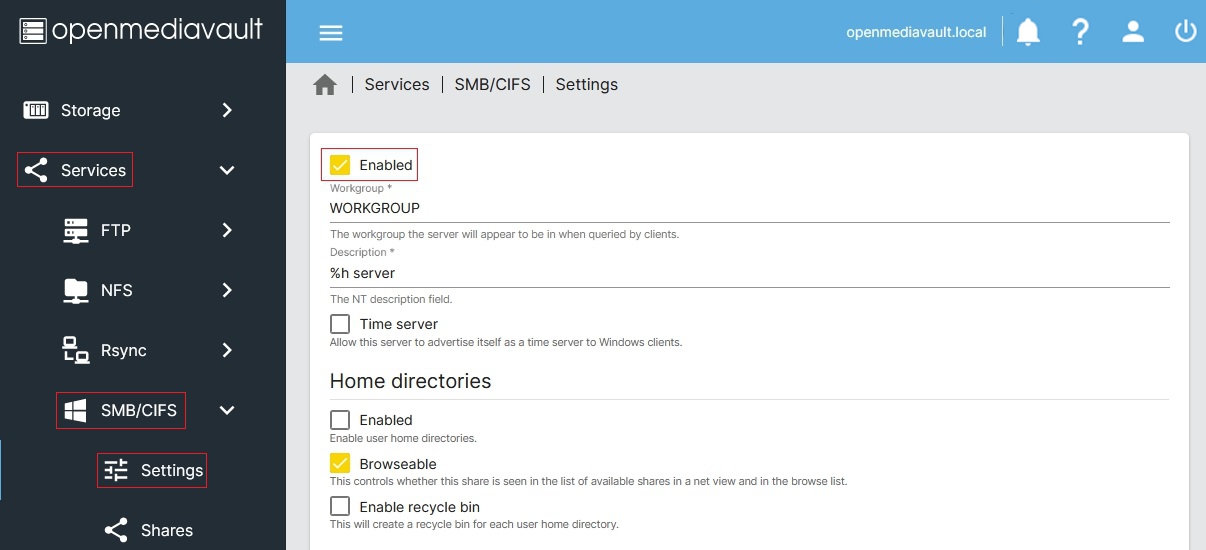
Enabling SMB/CIFS: Windows, Mac OS, and Linux systems tend to work pretty well with SMB/CIFS for network file shares. From the menu, select [Services > SMB/CIFS > Settings].
Check the Enabled box. If your LAN workgroup is something other than the default WORKGROUP you should enter it. Now any device on your network that supports SMB/CIFS will be able to see the folders that OpenMediaVault shares. (see below, Image credit: OMV-extras Wiki)
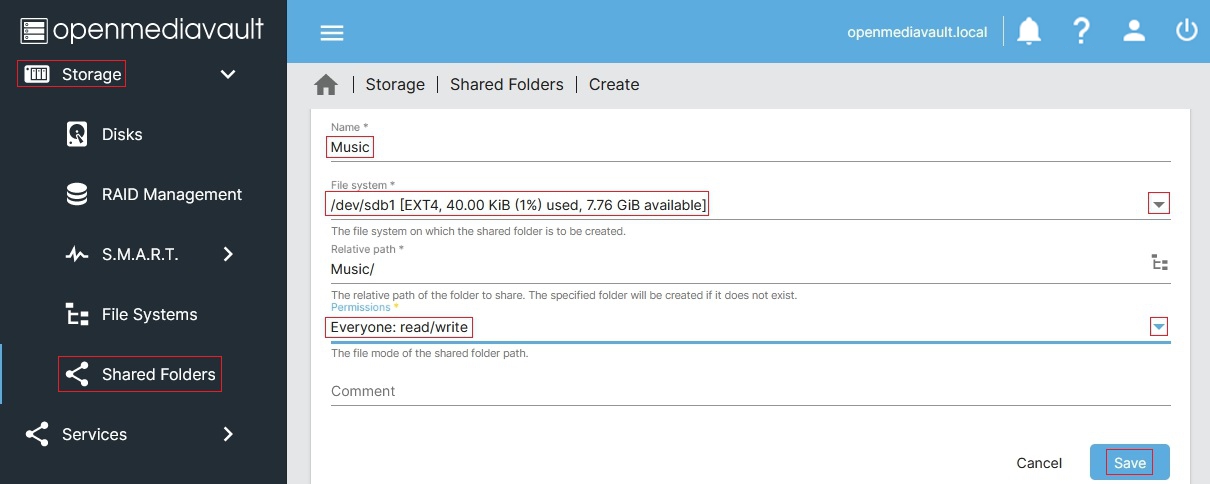
Selecting folders to share: On the left-hand-side of the administrative panel, select [Storage > Shared Folders]. This will list all the folders that can be shared.
To make a folder available to your network, select the button in the upper-left, and fill out the Name (what you want the folder to be called when other’s access it) and select the File System you’ve previously mounted that the folder will connect to. You can write out the name of the directory you want to share and/or use the directory folder icon to the right of the Relative Path field to help select the right folder. Under Permissions, for simplicity I would assign Everyone: read/write. (see below, Image credit: OMV-extras Wiki)
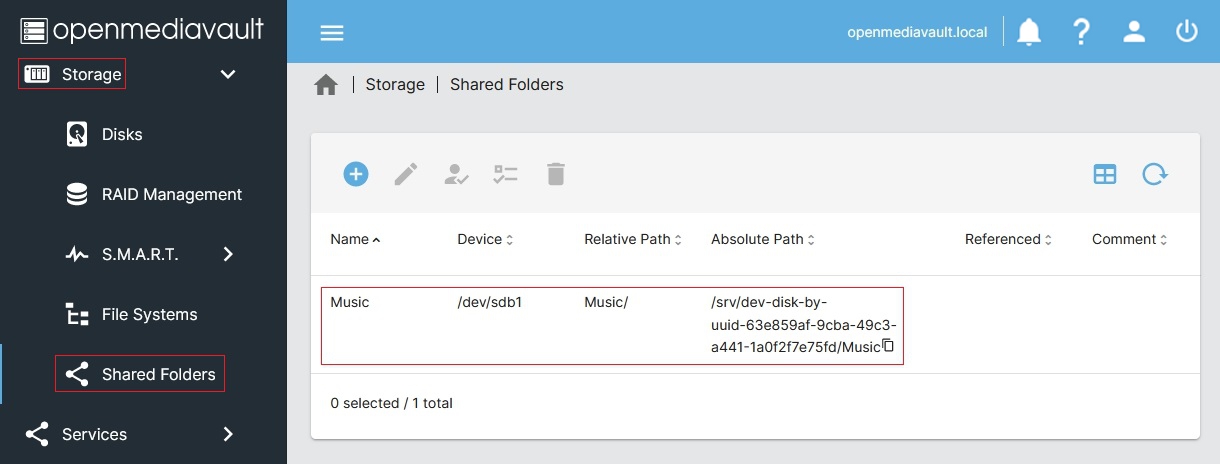
Hit Save to return to the list of folder shares (see below for what a completed entry looks like, Image credit: OMV-extras Wiki). Repeat the process to add as many Shared Folders as you’d like.
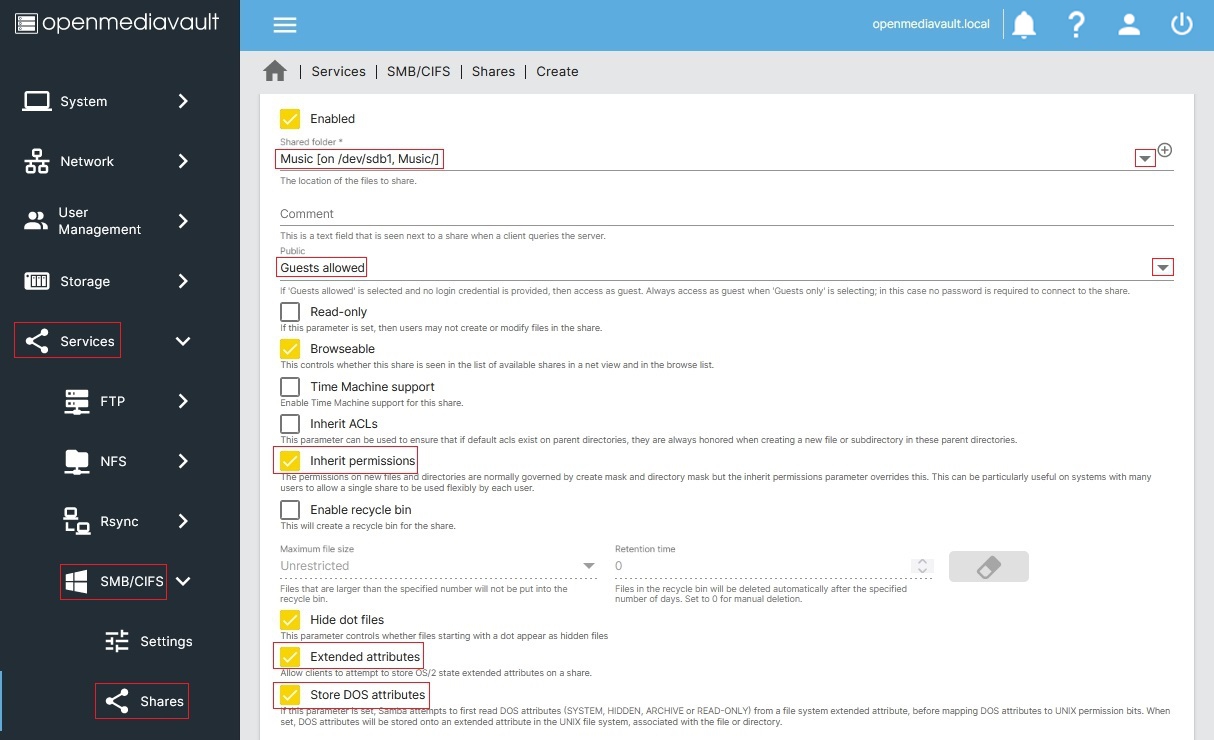
Make the shared folders available to SMB/CIFS: To do this go to [Services > SMB/CIFS > Shares]. Hit the button and, in, Shared Folder, select the Shared Folder you configured from the dropdown. Under Public, select Guests allowed – this will allow users on the network to access the folder without supplying a username or password. Check the Inherit Permissions, Extended attributes, and Store DOS attributes boxes as well and then hit Save. Repeat this for all the shared folders you want to make available. (Image credit: OMV-extras Wiki)
Set a static local IP: Home networks typically dynamically assign IP addresses to the devices on the network (something called DHCP). As a result, the IP address for your server may suddenly change. To give your server a consistent address to connect to, you should configure your router to assign a static IP to your server. The exact instructions will vary by router so you’ll need to consult your router’s documentation. In my household, we use Google Wifi and, if you do too, here are the instructions for doing so. (Make sure to write down the static IP you assign to the server as you will need it later. If you change the IP from what it already was, make sure to log into the OpenMediaVault panel from that new address before proceeding.)
Check that the shared folders show up on your network: Linux, Mac OS, and Windows all have separate ways of mounting a SMB/CIFS file share. The steps above hopefully simplify this by:
letting users connect as a Guest (no extra authentication needed)
Enter containers. Containers are “portable environments” for software, first popularized by the company Docker, that gives software a predictable background to run on. This makes it easier to run applications reliably, regardless of machine (because the application only sees what the container shows it). It also means a greatly reduced risk of a misconfigured app affecting another since the application “lives” in its own container.
While this has tremendous implications for software in general, for our purposes, this just makes it a lot easier to install software … provided you have Docker installed. For OpenMediaVault, the best way to get Docker is to install OMV-extras.
If you know how to use ssh, go ahead and use it to access your server’s IP address, login as the root user, and skip to Step 4. But, if you don’t, the easiest way to proceed is to set up WeTTY (Steps 1-3):
Install WeTTY: Go to [System > Plugins] and search or scroll until you find the row for openmediavault-wetty. Click on it to mark it yellow and then press the button to install it. WeTTY is a web-based terminal which will let you access the server command line from a browser.
Enable WeTTY: Once the install is complete, go to [Services > WeTTY], check the Enabled box, and hit Save. You’ll be prompted by OpenMediaVault to confirm the pending change.
Press Open UIbutton on the page to access WeTTY: It should open up a new tab that takes you to your-ip-address:2222 which should open up a black screen which is basically the command line for your server! Enter root when prompted for your username and then your root password that you configured during installation.
Installation will take a while but once it’s complete, you can verify it by going back to your administrative panel, refreshing the page, and seeing if there is a new menu item [System > omv-extras].
Enable the Docker repo: From the administrative panel, go to [System > omv-extras] and check the Docker repo box. Press the apt clean button once you have.
Install the Docker-compose plugin: Go to [System > Plugins] and search or scroll down until you find the entry for openmediavault-compose. Click on it to mark it yellow and then press the button on the upper-left to install it. To confirm that it’s been installed, you should see a new menu item [Services > Compose]
Update the System: As before, select [System > Update Management > Updates]. Press the button to search for new updates. Press the button which will automatically install everything.
Create three shared folders: compose, containers, and config: Just as with setting up the network folder shares, you can do this by going to [Storage > Shared Folders] and pressing the button in the upper left. You can generally pick any location you’d like, but make sure it’s on a file system with a decent amount of storage as media server applications can store quite a bit of configuration and temporary data (e.g. preview thumbnails).
compose and containers will be used by Docker to store the information it needs to set up and operate the containers you’ll want.
I would also recommend sharing config on the local network to make it easier to see and change the application configuration files (go to [Services > SMB/CIFS > Shares] and add it in the same way you did for the File Server step). Later below, I use this to add a custom theme to Ubooquity.
Configure Docker Compose: Go to [Services > Compose > Settings]. Where it says Shared folder under Compose Files, select the compose folder you created in Step 8. Where it says Docker storage under Docker, copy the absolute path (not the relative path) for the containers folder (which you can get from [Storage > Shared Folders]). Once that’s all set. Press Reinstall Docker.
Set up a User for Docker: You’ll need to create a separate user for Docker as it is dangerous to give any application full access to your root user. Go to [Users > Users] (yes, that is Users twice). Press the button to create a new user. You can give it whatever name (i.e. dockeruser) and password you want, but under Groups make sure to select both docker and users. Hit Save and once you’re set you should see your new user on the table. Make a note of the UID and GID (they’ll probably be 1000 and 100, respectively, if this is your first user other than the root) as you’ll need it when you install applications.
That was a lot! But, now you’ve set up Docker Compose. Now let’s use it to install some applications!
Setting up Media Server(s)
Before you set up the applications that access your data, you should make sure all of that data (i.e. photos you’ve taken, music you’ve downloaded, movies you’ve ripped / bought, PDFs you’d like to make available, etc.) are on your server and organized.
My suggestion is to set up a shared folder accessible to the network (mine is called Media) and have subdirectories in that folder corresponding for the different types of files that you may want your media server(s) to handle (for example: Videos, Photos, Files, etc). Then, use the network to move the files over (you should get comparable, if not faster, speeds as a USB transfer on a local area network).
The two media servers I’ve set up on my system are Plex (to serve videos, photos, and music) and Ubooquity (to serve files and especially ePUB/PDFs). There are other options out there, many of which can be similarly deployed using Docker compose, but I’m just going to cover my setup with Plex and Ubooquity below.
Plex
Why I chose it:
I’ve been using Plex for many years now, having set up clients on virtually all of my devices (phones, tablets, computers, and smart TVs).
I bought a lifetime Plex Pass a few years back which gives me access to even more functionality (including Intel Quick Sync transcode).
It has a wealth of automatic features (i.e. automatic video detection and tagging, authenticated access through the web without needing to configure a VPN, etc.) that have worked reliably over the years.
How to set up Docker Compose: Go to [Services > Compose > Files] and press the button. Under Name put down Plex and under File, paste the following (making sure the number of spaces are consistent)
version: "2.1" services: plex: image: lscr.io/linuxserver/plex:latest container_name: plex network_mode: host environment: - PUID=<UID of Docker User> - PGID=<GID of Docker User> - TZ=America/Los_Angeles - VERSION=docker devices: - /dev/dri/:/dev/dri/ volumes: - <absolute path to shared config folder>/plex:/config - <absolute path to Media folder>:/media restart: unless-stopped
You need to replace <UID of Docker User> and <GID of Docker User> with the UID and GID of the Docker user you created when you set up Docker Compose (Step 10 above), which will likely be 1000 and 100 if you followed the steps I laid out.
You can get the the absolute paths to your config folder and the location of your media files by going to [Storage > Shared Folders] in the administrative panel. I added a /plex to the config folder path under volumes:. This way you can install as many apps through Docker as you want and consolidate all of their configuration files in one place, while still keeping them separate.
If you have an Intel QuickSync CPU, the two lines that start with devices: and /dev/dri/ will allow Plex to use it (provided you also paid for a Plex Pass). If you don’t have a chip with Intel QuickSync, haven’t paid for Plex Pass, or don’t want it, leave out those two lines.
I live in the Bay Area so I set timezone TZ to America/Los_Angeles. You can find yours here.
Once you’re done, hit Save and you should be returned to your list of Docker compose files for the next step. Notice that the new Plex entry you created has a Down status, showing the container has yet to be initiated.
How to start / update / stop / remove your Plex container: You can manage all of your Docker Compose files by going to [Services > Compose > Files]. Click on the Plex entry (which should turn it yellow) and press the (up) button. This will create the container, download any files needed, and run it.
And that’s it! To prove it worked, go to http://your-ip-address:32400/web in a browser and you should see a login screen (see image below)
From time to time, you’ll want to update your software. Docker makes this very easy. Because of the image: lscr.io/linuxserver/plex:latest line, every time you press the (pull) button, Docker will pull the latest version from linuxserver.io (a group that maintains commonly used Linux containers) and, usually, you can get away with an update without needing to stop or restart your container.
Similarly, to stop the Plex container, simply tap the (stop) button. And to delete the container, tap the (down) button.
Do the setup wizard. It has good default settings (automatic library scans, remote access, etc.) — and I haven’t had to make many tweaks.
Take advantage of remote access — You can access your Plex server even when you’re not at home just by going to plex.tv and logging in.
Install Plex clients everywhere — It’s available on pretty much everything (Web, iOS, Android) and, with remote access, becomes a pretty easy way to get access to all of your content
I hide most of Plex’s default content in the Plex clients I’ve setup. While their ad-sponsored offerings are actually pretty good, I’m rarely consuming those. You can do this by configuring which things are pinned, and I pretty much only leave the things on my media server up.
Ubooquity
Why I chose it: Ubooquity has, sadly, not been updated in almost 5 years as of this writing. But, I still chose it for two reasons. First, unlike many alternatives, it does not require me to create a new file organization structure or manually tag my old files to work. It simply shows me my folder structure, lets me open the files one page at a time, maintains read location across devices, and lets me have multiple users.
Second, it’s available as a container on linuxserver.io (like Plex) which makes it easy to install and means that the infrastructure (if not the application) will continue to be updated as new container software comes out.
I may choose to switch (and the beauty of Docker is that it’s very easy to just install another content server to try it out) but for now Ubooquity made the most sense.
How to set up the Docker Compose configuration: Like with Plex, go to [Services > Compose > Files] and press the button. Under Name put down Ubooquity and under File, paste the following
--- version: "2.1" services: ubooquity: image: lscr.io/linuxserver/ubooquity:latest container_name: ubooquity environment: - PUID=<UID of Docker User> - PGID=<GID of Docker User> - TZ=America/Los_Angeles - MAXMEM=512 volumes: - <absolute path to shared config folder>/ubooquity:/config - <absolute path to shared Media folder>/Books:/books - <absolute path to shared Media folder>/Comics:/comics - <absolute path to shared Media folder>/Files:/files ports: - 2202:2202 - 2203:2203 restart: unless-stopped
You need to replace <UID of Docker User> and <GID of Docker User> with the UID and GID of the Docker user you created when you set up Docker Compose (Step 10 above), which will likely be 1000 and 100 if you followed the steps I laid out.
You can get the the absolute paths to your config folder and the location of your media files by going to [Storage > Shared Folders] in the administrative panel. I added a /ubooquity to the config folder path under volumes:. This way you can install as many apps through Docker as you want and consolidate all of their configuration files in one place, while still keeping them separate.
I live in the Bay Area so I set timezone TZ to America/Los_Angeles. You can find yours here.
Once you’re done, hit Save and you should be returned to your list of Docker compose files for the next step. Notice that the Ubooquity entry you created has a Down status, showing it has yet to be initiated.
How to start / update / stop / remove your Ubooquity container: You can manage all of your Docker Compose files by going to [Services > Compose > Files]. Click on the Ubooquity entry (which should turn it yellow) and press the (up) button. This will create the container, download any files needed, and run the system.
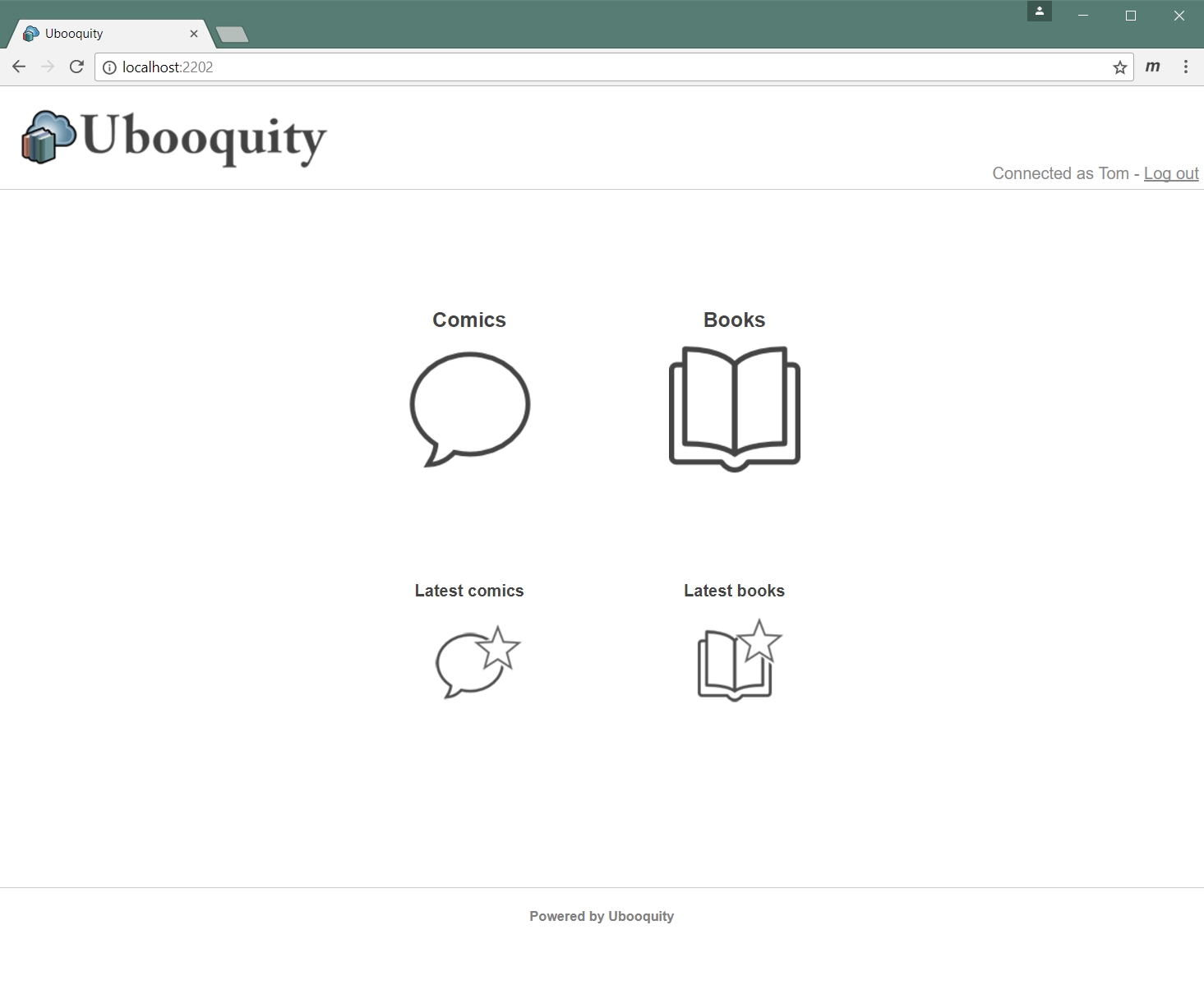
And that’s it! To prove it worked, go to your-ip-address:2202/ubooquity in a browser and you should see the user interface (image credit: Ubooquity)
From time to time, you’ll want to update your software. Docker makes this very easy. Because of the image: lscr.io/linuxserver/ubooquity:latest line, every time you press the (pull) button, Docker will pull the latest version from linuxserver.io (a group that maintains commonly used Linux containers) and, usually, you can get away with an update without needing to stop or restart your container.
Similarly, to stop the Ubooquity container, simply tap the (stop) button. And to remove the container, tap the (down) button.
Getting started with Ubooquity: While Ubooquity will more or less work out of the box, if you want to really configure your setup you’ll need to go to the admin panel atyour-ip-address:2203/ubooquity/admin (you will be prompted to create a password the first time)
In the General tab, you can see how many files are tracked in the table at the top, configure how frequently Ubooquity scans your folders for new files under Automatic scan period, manually launch a scan if you just added files with Launch New Scan, and select a theme for the interface.
If you want to create User accounts to have separate read state management or to segment which users can access specific content, you can create these users in the Security tab of the administrative panel. By doing so, you’ll need to manually go into the content type tabs (i.e. Comics, Books, Raw Files) and manually configure which users have access to which shared folders.
The easiest way to do this is to download the ZIP file at the link I gave. Unzip it on your computer (in this case it will result in the creation of a directory called plextheme-reading). Then, assuming the config shared folder you set up previously is shared across the network, take the unzipped directory and put it into the /ubooquity/themes subdirectory of the config folder.
Lastly, go back to the General tab in Ubooquity admin and, next to Current theme select plextheme-reading
Edit (10-Aug-2023): I’ve since switched to using a Local DNS service powered by Pihole to access Ubooquity using a human readable web address ubooquity.home that every device on my network can access. For information on how to do this, refer to my post on Setting Up Pihole, Nginx Proxy, and Twingate with OpenMediaVault Because entering in a local ip address and remembering 2202 or 2203 and the folders afterwards is a pain, I created keyword shortcuts for these in Chrome. The instructions for doing this will vary by browser, but to do this in Chrome, go to chrome://settings/searchEngines. There is a section of the page called Site search. Press the Add button next to it. Even though the dialog box says Add Search Engine, in practice you can use this to add keywords to any URL, just put a name for the shortcut in the Search Engine field, the shortcut you want to use in Shortcut (I used ubooquity for the core application and ubooquityadmin for the administrative console) and the URLs in URL with %s in place of query (i.e. http://your-ip-address:2202/ubooquity and http://your-ip-address:2203/ubooquity/admin).
Now to get to Ubooquity, I simply type in ubooquity in the Chrome address bar rather than a hodge podge of numbers and slashes that I’ll probably forget
External Access
One of Plex’s best features is making it very easy to access your media server even when you’re not on your home network. Having experienced that, I wanted the same level of access when I was out of the house to my network file share and applications like Ubooquity.
Edit (10-Aug-2023): I’ve since switched my method of granting external access to Twingate. This provides secure access to network resources without needing to configure Dynamic DNS, a VPN, or open up a port. For more information on how to do this, refer to my post on Setting Up Pihole, Nginx Proxy, and Twingate with OpenMediaVault
There are a few ways to do this, but the most secure path is through a VPN (virtual private network). VPNs are secure connections between computers that mimic actually being directly networked together. In our case, it lets a device securely access local network resources (like your server) even when it’s not on the home network.
OpenMediaVault makes it relatively easy to use Wireguard, a fast and popular VPN technology with support for many different types of devices. To set up Wireguard for your server for remote access, you’ll need to do six things:
Get a domain name and enable Dynamic DNS on it Most residential internet customers do not have a static IP. This means that the IP address for your home, as the rest of the world sees it, can change without warning. This makes it difficult to access externally (in much the same way that DHCP makes it hard to access your home server internally).
To address this, many domain providers offer Dynamic DNS, where a domain name (for example: myurl.com) can point to a different IP address depending on when you access it, so long as the domain provider is told what the IP address should be whenever it changes.
The exact instructions for how to do this will vary based on who your domain provider is. I use Namecheap and took an existing domain I owned and followed their instructions for enabling Dynamic DNS on it. I personally configured mine to use my vpn. subdomain, but you should use the setup you’d like, so long as you make a note of it for step 3 below.
If you don’t want to buy your own domain and are comfortable using someone else’s, you can also sign up for Duck DNS which is a free Dynamic DNS service tied to a Duck DNS subdomain.
Set up DDClient. To update the IP address your domain provider maps the domain to, you’ll need to run a background service on your server that will regularly check its IP address. One common way to do this is a software package called DDClient.
Thankfully, setting up DDClient is fairly easy thanks (again!) to a linuxserver.io container. Like with Plex & Ubooquity, go to [Services > Compose > Files] and press the button. Under Name put down DDClient and under File, paste the following
You need to replace <UID of Docker User> and <GID of Docker User> with the UID and GID of the Docker user you created when you set up Docker Compose (Step 10 above), which will likely be 1000 and 100 if you followed the steps I laid out.
You can get the the absolute path to your config folder by going to [Storage > Shared Folders] in the administrative panel. I added a /ddclient to the config folder path. This way you can install as many apps through Docker as you want and consolidate all of their configuration files in one place, while still keeping them separate.
I live in the Bay Area so I set timezone TZ to America/Los_Angeles. You can find yours here.
Once you’re done, hit Save and you should be returned to your list of Docker compose files. Click on the DDClient entry (which should turn it yellow) and press the (up) button. This will create the container, download any files needed, and run DDClient. Now, it is ready for configuration.
Configure DDClient to work with your domain provider. While the precise configuration of DDClient will vary by domain provider, the process will always involve editing a text file. To do this, login to your server using SSH or WeTTy (see the section above on Installing OMV-Extras) and enter into the command line:
nano <absolute path to shared config folder>/ddclient/ddclient.conf
Remember to substitute <absolute path to shared config folder> with the absolute path to the config folder you set up for your applications (which you can access by going to [Storage > Shared Folders] in the administrative panel).
This will open up Linux’s native text editor. Scroll to the very bottom and enter the configuration information that your domain provider requires for DynamicDNS to work. As I use Namecheap, I followed these instructions. In general, you’ll need to supply some type of information about the protocol, the server, your login / password for the domain provider, and the subdomain you intend to map to your IP address.
Then press Ctrl+X to exit, press Y when asked if you want to save, and finally Enter to confirm that you want to overwrite the old file.
Set up Port Forwarding on your router. Dynamic DNS gives devices outside of your network a consistent “address” to get to your server but it won’t do any good if your router doesn’t pass those external requests through. In this case, you’ll need to tell your router to let incoming UDP requests from port 51820 through to your server to line up with Wireguard’s defaults.
The exact instructions will vary by router so you’ll need to consult your router’s documentation. In my household, we use Google Wifi and, if you do too, here are the instructions for doing so.
Enable Wireguard. If you installed OMV-Extras above as I suggested, you’ll have access to a Plugin that turns on Wireguard. Go to [System > Plugins] on the administrative panel and then search or scroll down until you find the entry for openmediavault-wireguard. Click on it to mark it yellow and then press the button to install it.
Now go to [Services > Wireguard > Tunnels] and press the (create) button to set up a VPN tunnel. You can give it any Name you want (i.e. omv-vpn). Select your server’s main network connection for Network adapter. But, most importantly, under Endpoint, add the domain you just configured for DynamicDNS/DDClient (for example, vpn.myurl.com). Press Save
Set up Wireguard on your devices. With a Wireguard tunnel configured, your next step is to set up the devices (called clients or peers) to connect. This has two parts.
First, install the Wireguard applications on the devices themselves. Go to wireguard.com/install and download or set up the Wireguard apps. There are apps for Windows, MacOS, Android, iOS, and many flavors of Linux
Then, go back into your administrative panel and go to [Services > Wireguard > Clients] and press the (create) button to create a valid client for the VPN. Check the box next to Enable, select the tunnel you just created under Tunnel number, put a name for the device you’re going to connect under Name, and assign a unique (or it will not work) client number in Client Number . Press Save and you’ll be brought back to the Client list. Make sure to approve the change and then press the (client config) button. What you should do next depends on what kind of client device you’re configuring.
If the device you’re configuring is not a smartphone (i.e. a computer), copy the text that shows up in the Client Config popup that comes up and save that as a .conf file (for example: work_laptop_wireguard.conf). Send that file to the device in question as that file will be used by the Wireguard app on that device to configure and access the VPN. Hit Close when you’re done
If the device you’re configuring is a smartphone, hit Close button on the Client Config popup that comes up as you will be presented with a QR code that your smartphone Wireguard app can capture to configure the VPN connection.
Now go into your Wireguard app on the client device and use it to either take a picture of the QR code when prompted or load the .conf file. Your device is now configured to connect to your server securely no matter where you are. A good test of this is to disconnect a set up smartphone from your home WiFi and enable the VPN. Since you’re no longer on WiFi you should not be on the same network as your server. If you can enter http://your-ip-address in this mode into a browser and still reach the administrative panel for OpenMediaVault, you’re home free!
One additional note: by default, Wireguard also acts as a proxy, meaning all internet traffic you send from the device will be routed through the server. This can be valuable if you’re trying to access a blocked website or pretend to be from a different location, but it can also be unnecessarily slow (and bandwidth consuming). I have my Wireguard configured to only route traffic that is going to my server’s local IP address through Wireguard. You can do this by configuring your client device’s Allowed IPs to your-ip-address (for example: 192.168.99.99) from the Wireguard app.
Congratulations, you have now configured a file server and media server that you can securely access from anywhere!
Concluding Thoughts
A few concluding thoughts:
This was probably way too complicated for most people. Believe it or not, what was written above is a shortened version of what I went through. Even holding aside that use of the command line and Docker automatically makes this hard for many consumers, I still had to deal with missing drivers, Linux not recognizing my USB drive through the USB C port (but through the USB A one?), puzzling over different external access configurations (VPN vs Let’s Encrypt SSL on my server vs self-sign certificate), and minimal feedback when my initial attempts to use Wireguard failed. While I learned a great deal, for most people, it makes more sense to go completely third party (i.e. use Google / Amazon / Apple for everything) or, if you have some pain tolerance, with a high-end NAS.
Docker/containerization is extremely powerful. Prior to this, I had thought of Docker as just a “flavor” of virtual machine, a software technology underlying cloud computing which abstracts server software from server hardware. And, while there is some overlap, I completely misunderstood why containers were so powerful for software deployment. By using 3 fairly simple blocks of text, I was able to deploy 3 complicated applications which needed different levels of hardware and network access (Ubooquity, DDClient, Plex) in minutes without issue.
I was pleasantly surprised by how helpful the blogs and forums were. While the amount of work needed to find the right advice can be daunting, every time I ran into an issue, I was able to find some guidance online (often in a forum or subreddit). While there were certainly … abrasive personalities, by in large many of the questions being asked were by non-experts and they were answered by experts showing patience and generosity of spirit. Part of the reason I wrote this is to pay this forward for the next set of people who want to experiment with setting up their own server.
I am excited to try still more applications. Lists about what hobbyists are running on their home servers like this and this and this make me very intrigued by the possibilities. I’m currently considering a network-wide adblocker like Pi-Hole and backup tools like BorgBackup. There is a tremendous amount of creativity out there!
For more help on setting any of this stuff up, here are a few additional resources that proved helpful to me:
OMV Extras Wiki — probably the single best source of help I turned to in setting up OpenMediaVault, Docker Compose, and Wireguard
Section 230 of the Communications Decency Act has been rightfully called “the twenty-six words that created the Internet.” It is a valuable legal shield which allows internet hosts and platforms the ability to distribute user-generated content and practice moderation without unreasonable fear of being sued, something which forms the basis of all social media, user review, and user forum, and internet hosting services.
While I think it’s reasonable to modify Section 230 to obligate platforms to help victims of clearly heinous acts like cyberstalking, swatting, violent threats, and human rights violations, what the Democratic Senators are proposing goes far beyond that in several dangerous ways.
First, Warner and his colleagues have proposed carving out from Section 230 all content which accompanies payment (see below). While I sympathize with what I believe was the intention (to put a different bar on advertisements), this is remarkably short-sighted, because Section 230 applies to far more than companies with ad / content moderation policies Democrats dislike such as Facebook, Google, and Twitter.
It also encompasses email providers, web hosts, user generated review sites, and more. Any service that currently receives payment (for example: a paid blog hosting service, any eCommerce vendor who lets users post reviews, a premium forum, etc) could be made liable for any user posted content. This would make it legally and financially untenable to host any potentially controversial content.
Secondly, these rules will disproportionately impact smaller companies and startups. This is because these smaller companies lack the resources that larger companies have to deal with the new legal burdens and moderation challenges that such a change to Section 230 would call for. It’s hard to know if Senator Warner’s glip answer in his FAQ that people don’t litigate small companies (see below) is ignorance or a willful desire to mislead, but ask tech startups how they feel about patent trolls and whether or not being small protects them from frivolous lawsuits
Third, the use of the language “affirmative defense” and “injunctive relief” may have far-reaching consequences that go beyond minor changes in legalese (see below). By reducing Section 230 from an immunity to an affirmative defense, it means that companies hosting content will cease to be able to dismiss cases that clearly fall within Section 230 because they now have a “burden of [proof] by a preponderance of the evidence.”
Similarly, carving out “injunctive relief” from Section 230 protections (see below) means that Section 230 doesn’t apply if the party suing is only interested in taking something down (but not financial damages)
I suspect the intention of these clauses is to make it harder for large tech companies to dodge legitimate concerns, but what this practically means is that anyone who has the money to pursue legal action can simply tie up any internet company or platform hosting content that they don’t like.
That may seem like hyperbole, but this is what happened in the UK until 2014 where libel / slander laws making it easy for wealthy individuals and corporations to sue anyone for negative press due to weak protections. Imagine Jeffrey Epstein being able to sue any platform for carrying posts or links to stories about his actions or any individual for forwarding an unflattering email about him.
There is no doubt that we need new tools and incentives (both positive and negative) to tamp down on online harms like cyberbullying and cyberstalking, and that we need to come up with new and fair standards for dealing with “fake news”. But, it is distressing that elected officials will react by proposing far-reaching changes that show a lack of thoughtfulness as it pertains to how the internet works and the positives of existing rules and regulations.
It is my hope that this was only an early draft that will go through many rounds of revisions with people with real technology policy and technology industry expertise.
Amazon’s Lightsail service has made it remarkably cheap and simple for people hosting webpages (including this blog) and simple web applications to get access to high quality virtual private servers (VPS). Beyond the ability to do really stupid things with your VPS powers, my only real complaint with the experience thus far has been that getting HTTPS working with Let’s Encrypt’s free SSL certificates has been a a hassle, requiring a lot more DNS configuration and manual command-line tweaking than is really necessary.
Manually adjusting your DNS configuration with TXT records to confirm domain ownership (each renewal)
Manually copying of certificate files to the right directory
Requires you to manually setup URL redirection (i.e. moving your HTTP URLs to HTTPS, figuring out how to handle “www.” subdomain, etc)
Manual renewal every cycle (Let’s Encrypt certificates expire every 90 days)
Bitnami’s new command line tool (bncert) is vastly simpler to use:
Assuming you’ve already linked the domain you wish to enable HTTPS for to the public IP address for your server, the domain certification is handled automatically without any effort (if it’s not, you may need to add TXT records)
Automatically configures URL redirection for you based on what you enter when prompted
Automatically puts the certificates where they need to be
Automatically renews your certificates in 80 days (right before they expire)
The only downside I can see from the new bncert tool is that it does not support a wildcard certificate (which would work with any subdomain the way that certbot did), so if you’re planning on using multiple subdomains, it may be worth first planning out which domains you intend to use prior to using bncert (or to continue with certbot)
If you’re using a recent Bitnami WordPress image, bncert should already be present (and you can simply follow the instructions on the Lightsail documentation page and skip Step 4) — if not, you can either install the tool (Step 4 of the instructions) or (and this is the path I’d recommend) create a new Lightsail image and migrate your WordPress blog over. It’s a bit of a pain but it’s worth the effort as if you’ve been using an older version of Bitnami WordPress, there’s a good chance you’re using an out of date PHP installation. For help, here is a guide I wrote to how to move an old WordPress blog to a new WordPress setup.
Then the only remaining step is to change your WordPress Domain name in the wp-config.php file (so that your WordPress install thinks of itself as an https rather than an http domain). To do this, use the Lightsail command line interface and enter
sudo nano /opt/bitnami/wordpress/wp-config.php
This opens up a text editor (nano). Use the down key until you see a pair of lines that say:
If you’ve been exposed to any financial news in the last few days, you’ll have heard of Gamestop, the mostly brick and mortar video gaming retailer who’s stock has been caught between many retail investors on the subreddit r/WallstreetBets and hedge fund Melvin Capital which had been actively betting against the company. The resulting short squeeze (where a rising stock price forces investors betting against a company to buy shares to cover their own potential losses — which itself can push the stock price even higher) has been amazing to behold with the worth of Gamestop shares increasing over 10-fold in a matter of months.
While it’s hard not to get swept up in the idea of “the little guy winning one over on a hedge fund”, the narrative that this is Main Street winning over Wall Street is overblown.
First, speaking practically, it’s hard to argue that giving one hedge fund a black eye by making Gamestop executives & directors and large investment funds holding $100M’s of Gamestop prior to the increase wealthier is anyone winning anything over on Wall Street. And that’s not even accounting for the fact that hedge funds are usually managing a significant amount of money on behalf of pension funds and foundation / university endowments.
Second, while the paper value of recent investments in Gamestop has clearly jumped through the roof, what these investors will actually “win” is unclear. Even holding aside short-term capital gains taxes that many retail investors are unclear on, the reality is that, to make money on an investment, you not only have to buy low, you have to successfully sell high. By definition, any company experiencing a short-squeeze is volume-limited — meaning that it’s the lack of sellers that is causing the increase in price (the only way to get someone to sell is to offer them a higher price). If the stock price changes direction, it could trigger a flood of investors flocking to sell to try to hold on to their gains which can create the opposite problem: too many people trying to sell relative to people trying to buy which can cause the price to crater.
Regulatory and legal experts are better suited to weigh in on whether or not this constitutes market manipulation that needs to be regulated. For whatever it’s worth, I personally feel that Redditors egging each other on is no different than an institutional investor hyping their investments on cable TV.
While many retail investors view these restrictions as a move by Wall Street to screw the little guy, there’s a practical reality here that the brokerages are probably fearful of:
Lawsuits from investors, some of whom will eventually lose quite a bit of money here
SEC actions and punishments due to eventual outcry from investors losing money
I love stories of hedge funds facing the consequences of the risks they take on — but the idea that this is a clear win for Main Street is suspect (as is the idea that the right answer for most retail investors is to HODL through thick and through thin).
I’ve been a big fan of moving my personal page over to AWS Lightsail. But, if I had one complaint, it’s the dangerous combination of (1) their pre-packaged WordPress image being hard to upgrade software on and (2) the training-wheel-lacking full root access that Lightsail gives to its customers. That combination led me to make some regrettable mistakes yesterday which resulted in the complete loss of my old blog posts and pages.
It’s the most painful when you know your problems are your own fault. Thankfully, with the very same AWS Lightsail, it’s easy enough to start up a new WordPress instance. With the help of site visit and search engine analytics, I’ve prioritized the most popular posts and pages to resurrect using Google’s cache.
Unfortunately, that process led to my email subscribers receiving way too many emails from me as I recreated each post. For that, I’m sorry — mea culpa — it shouldn’t happen again.
I’ve come to terms with the fact that I’ve lost the majority of the 10+ years of content I’ve created. But, I’ve now learned the value of systematically backing up things (especially my AWS Lightsail instance), and hopefully I’ll write some good content in the future to make up for what was lost.
While not usually so dramatic, volatility is a fact of life for investors. In researching how to create a long-term investment strategy that can cope with volatility, I found a lot of the writing on the subject unsatisfying for two reasons:
First, much of the writing on investment approaches leans heavily on historical comparisons (or “backtesting”). While it’s important to understand how a particular approach would play out in the past, it is dangerous to assume that volatility will always play out in the same way. For example, take a series of coin tosses. It’s possible that during the most recent 100 flips, the coin came up heads 10 times in a row. Relying mainly on backtesting this particular sequence of coin tosses could lead to conclusions that rely on a long sequences of heads always coming up. In a similar way, investment strategies that lean heavily on backtesting recent history may be well-situated for handling the 2008 crash and the 2010-2019 bull market but fall apart if the next boom or bust happens in a different way.
Second, much of the analysis on investment allocation is overly focused on arithmetic mean returns rather than geometric means. This sounds like a minor technical distinction, but to illustrate why it’s significant, imagine that you’ve invested $1,000 in a stock that doubled in the first year (annual return: 100%) and then halved the following year (annual return: -50%). Simple math shows that, since you’re back where you started, you experienced a return over those two years (in this case, the geometric mean return) of 0%. The arithmetic mean, on the other hand, comes back with a market-beating 25% return [1/2 x (100% + -50%)]! One of these numbers suggests this is an amazing investment and the other correctly calls it as a terrible one! Yet despite the fact that the arithmetic mean always overestimates the (geometric mean) return that an investor experiences, much of the practice of asset allocation and portfolio theory is still focused on arithmetic mean returns because they are easier to calculate and build precise analytical solutions around.
Visualizing a 40-Year Investment in the S&P500
To overcome these limitations, I used Monte Carlo simulations to visualize what volatility means for investment returns and risk. For simplicity, I assumed an investment in the S&P500 would see annual returns that look like a normal distribution based on how the S&P500 has performed from 1928 – 2019. I ran 100,000 simulations of 40 years of returns and looked at what sorts of (geometric mean) returns an investor would see.
This first chart below is a heatmap showing the likelihood that an investor will earn a certain return in each year (the darker the shade of blue, the more simulations wound up with that geometric return in that year).
Density Map of 40-YearReturns for Investment in S&P500 Densities are log (base 10)-adjusted; Assumes S&P500 returns are normally distributed (clipped from -90% to +100%) based on 1928-2019 annual returns; Years go from 0-39 (rather than 1-40)
This second chart below is a different view of the same data, calling out what the median return (the light blue-green line in the middle; where you have a 50-50 shot at doing better or worse) looks like. Going “outward” from the median line are lines representing the lower and upper bounds of the middle 50%, 70%, and 90% of returns.
Confidence Interval Map of 40-Year Return for Investment in S&P500 (from outside to middle) 90%, 70%, and 50% confidence interval + median investment returns. Assumes S&P500 returns are normally distributed (clipped from -90% to +100%) based on 1928-2019 annual returns
Finally, the third chart below captures the probability that an investment in the S&P500 over 40 years will result not in a loss (the darkest blue line at the top), will beat 5% (the second line), will beat 10% (the third line), and will beat 15% (the lightest blue line at the bottom) returns.
Probability 40-Year Investment in S&P500 will Exceed 0%, 5%, 10%, and 15% Returns (from top to bottom/darkest to lightest) Probability that 40-year S&P500 returns simulation beat 0%, 5%, 10%, and 15% geometric mean return. Assumes S&P500 returns are normally distributed (clipped from -90% to +100%) based on 1928-2019 annual returns
The charts are a nice visual representation of what uncertainty / volatility mean for an investor and show two things.
First, the level of uncertainty around what an investor will earn declines the longer they can go without touching the investment. In the early years, there is a much greater spread in returns because of the high level of volatility in any given year’s stock market returns. From 1928 – 2019, stock markets saw returns ranging from a 53% increase to a 44% drop. Over time, however, reversion to the mean (a fancy way of saying a good or bad year is more likely to be followed by more normal looking years) narrows the variation an investor is likely to see. As a result, while the median return stays fairly constant over time (starting at ~11.6% in year 1 — in line with the historical arithmetic mean return of the market — but dropping slowly to ~10% by year 10 and to ~9.8% starting in year 30), the “spread” of returns narrows. In year 1, you would expect a return between -21% and 44% around 90% of the time. But by year 5, this narrows to -5% to 25%. By year 12, this narrows further to just above 0% to 19.4% (put another way, the middle 90% of returns does not include a loss). And at year 40, this narrows to 4.6% to 15%.
Secondly, the risk an investor faces depends on the return threshold they “need”. As the probability chart shows, if the main concern is about losing money over the long haul, then the risk of that happening starts relatively low (~28% in year 1) and drops rapidly (~10% in year 7, ~1% in year 23). If the main concern is about getting at least a 5% return, this too drops from ~37% in year 1 to ~10% by year 28. However, if one needs to achieve a return greater than the median (~9.8%), then the probability gets worse over time and gets worse the greater the return threshold needed. To beat a 15% return, in year 1, there is a ~43% chance that this will happen. But this rapidly shrinks to ~20% by year 11, ~10% by year 24, and ~5% by year 40.
The Impact of Increasing Average Annual Return
These simulations are a useful way to explore how long-term returns vary. Let’s see what happens if we increase the (arithmetic) average annual return by 1% from the S&P500 historical average.
As one might expect, the heatmap for returns (below) generally looks about the same:
Density Map of 40-YearReturns for Higher Average Annual Return Investment Densities are log (base 10)-adjusted; Assumes an asset with normally distributed annual returns (clipped from -90% to +100%) based on 1928-2019 S&P500 annual returns but with 1% higher mean. Years go from 0-39 (rather than 1-40)
Looking more closely at the contour lines and overlaying them with the contour lines of the original S&P500 distribution (below, green is the new, blue the old), it looks like all the lines have roughly the same shape and spread, but have just been shifted upward by ~1%.
Confidence Interval Map of 40-Year Return for Higher Average Return Investment (Green) vs. S&P500 (Blue) (from outside to middle/darkest to lightest) 90%, 50% confidence interval, and median investment returns for S&P500 (blue lines; assuming normal distribution clipped from -90% to +100% based on 1928-2019 annual returns) and hypothetical investment with identical variance but 1% higher mean (green lines)
This is reflected in the shifts in the probability chart (below). The different levels of movement correspond to the impact an incremental 1% in returns makes to each scenario. For fairly low returns (i.e. the probability of a loss), the probability will not change much as it was low to begin with. Similarly, for fairly high returns (i.e., 15%), adding an extra 1% is unlikely to make you earn vastly above the median. On the other hand, for returns that are much closer to the median return, the extra 1% will have a much larger relative impact on an investment’s ability to beat those moderate return thresholds.
Probability Higher Average Return Investment (Green) and S&P500 (Blue) will Exceed 0%, 5%, 10%, and 15% Returns (from top to bottom/darkest to lightest) Probability that 40-year S&P500 returns simulation beat 0%, 5%, 10%, and 15% geometric mean return. Assumes S&P500 returns are normally distributed (clipped from -90% to +100%) based on 1928-2019 annual returns. Higher average return investment is a hypothetical asset with identical variance but 1% higher mean
Overall, there isn’t much of a surprise from increasing the mean: returns go up roughly in line with the change and the probability that you beat different thresholds goes up overall but more so for moderate returns closer to the median than the extremes.
What about volatility?
The Impact of Decreasing Volatility
Having completed the prior analysis, I expected that tweaking volatility (in the form of adjusting the variance of the distribution) would result in preserving the basic distribution shape and position but narrowing or expanding it’s “spread”. However, I was surprised to find that adjusting the volatility didn’t just impact the “spread” of the distribution, it impacted the median returns as well!
Below is the returns heatmap for an investment that has the same mean as the S&P500 from 1928-2019 but 2% lower variance. A quick comparison with the first heat/density map shows that, as expected, the overall shape looks similar but is clearly narrower.
Density Map of 40-YearReturns for Low Volatility Investment Densities are log (base 10)-adjusted; Assumes S&P500 returns are normally distributed (clipped from -90% to +100%) based on 1928-2019 annual returns but with 2% lower variance. Years go from 0-39 (rather than 1-40)
Looking more closely at the contour lines (below) of the new distribution (in red) and comparing with the original S&P500 distribution (in blue) reveals, however, that the difference is more than just in the “spread” of returns, but in their relative position as well! The red lines are all shifted upward and the upward shift seems to increase over time. It turns out a ~2% decrease in variance appears to buy a 1% increase in the median return and a 1.5% increase in the lower bound of the 50% confidence interval at year 40!
Confidence Interval Map of 40-Year Return for Low Volatility Investment (Red) vs. S&P500 (Blue) Left: (from outside to middle/darkest to lightest) 90%, 50% confidence interval, and median investment returns for S&P500 (blue lines; assuming normal distribution clipped from -90% to +100% based on 1928-2019 annual returns) and hypothetical investment with identical mean but 2% lower variance (red lines). Right: Zoomed-in look just at the median lines and 50% confidence interval bounds
The probability comparison (below) makes the impact of this clear. With lower volatility, not only is an investor better able to avoid a loss / beat a moderate 5% return (the first two red lines having been meaningfully shifted upwards from the first two blue lines), but by raising the median return, the probability of beating a median-like return (10%) gets better over time as well! The one area the lower volatility distribution under-performs the original is in the probability of beating a high return (15%). This too makes sense — because the hypothetical investment experiences lower volatility, it becomes less likely to get the string of high returns needed to consistently beat the median over the long term.
Probability Low Volatility Investment (Red) and S&P500 (Blue) will Exceed 0%, 5%, 10%, and 15% Returns (from top to bottom/darkest to lightest) Probability that 40-year S&P500 returns simulation beat 0%, 5%, 10%, and 15% geometric mean return. Assumes S&P500 returns are normally distributed (clipped from -90% to +100%) based on 1928-2019 annual returns. Low volatility investment is a hypothetical asset with identical mean but 2% lower variance
The Risk-Reward Tradeoff
Unfortunately, it’s not easy to find a “S&P500 but less volatile” or a “S&P500 but higher return”. In general, higher returns tend to go with greater volatility and vice versa.
While the exact nature of the tradeoff will depend on the specific numbers, to see what happens when you combine the two effects, I charted out the contours and probability curves for two distributions with roughly the same median return (below): one investment with a higher return (+1%) and higher volatility (+2% variance) than the S&P500 and another with a lower return (-1%) and lower volatility (-2% variance) than the S&P500:
Confidence Interval Map for Low Volatility/Low Return (Purple) vs. High Volatility/High Return (Gray) Left: (from outside to middle/darkest to lightest) 90%, 50% confidence interval, and median investment returns for hypothetical investment with 1% higher mean and 2% higher variance than S&P500 (gray) and one with 1% lower mean and 2% lower variance than S&P500 (purple). Both returns assume normal distribution clipped from -90% to +100% with mean/variance based on 1928-2019 annual returns for S&P500. Right: Zoomed-in look just at the median lines and 50% confidence interval bounds
Probability Low Volatility/Low Return (Purple) vs. High Volatility/High Return (Gray) Exceed 0%, 5%, 10%, and 15% Returns (from top to bottom/darkest to lightest) Probability that 40-year returns simulation for hypothetical investment with 1% higher mean and 2% higher variance than S&P500 (gray) and one with 1% lower mean and 2% lower variance than S&P500 (purple) beat 0%, 5%, 10%, and 15% geometric mean return. Both returns assume normal distribution clipped from -90% to +100% with mean/variance based on 1928-2019 annual returns for S&P500.
The results show how two different ways of targeting the same long-run median return compare. The lower volatility investment, despite the lower (arithmetic) average annual return, still sees a much improved chance of avoiding loss and clearing the 5% return threshold. On the other hand, the higher return investment has a distinct advantage at outperforming the median over the long term and even provides a consistent advantage in beating the 10% return threshold close to the median.
Takeaways
The simulations above made it easy to profile unconventional metrics (geometric mean returns and the probability to beat different threshold returns) across time without doing a massive amount of hairy, symbolic math. By charting out the results, they also helped provide a richer, visual understanding of investment risk that goes beyond the overly simple and widely held belief that “volatility is the same thing as risk”:
Time horizon matters as uncertainty in returns decreases with time: As the charts above showed, “reversion to the mean” reduces the uncertainty (or “spread”) in returns over time. What this means is that the same level of volatility can be viewed wildly differently by two different investors with two different time horizons. An investor who needs the money in 2 years could find one level of variance unbearably bumpy while the investor saving for a goal 20 years away may see it very differently.
The investment return “needed” is key to assessing risk: An investor who needs to avoid a loss at all costs should have very different preferences and assessments of risk level than an investor who must generate higher returns in order to retire comfortably, even at the same time. The first investor should prioritize lower volatility investments and longer holding periods, while the latter should prioritize higher volatility investments and shorter holding periods. It’s not just a question of personal preferences about gambling & risk, as much of the discussion on risk tolerance seems to suggest, because the same level of volatility should rationally be viewed differently by different investors with different financial needs.
Volatility impacts long-run returns: Higher volatility decreases long-term median returns, and lower volatility increases long-term returns. From some of my own testing, this seems to happen at roughly a 2:1 ratio (where a 2% increase in variance decreases median returns by 1% and vice versa — at least for values of return / variance near the historical values for S&P500). The result is that understanding volatility is key to formulating the right investment approach, and it creates an interesting framework with which to evaluate how much to hold of lower risk/”riskless” things like cash and government bonds.
What’s Next
Having demonstrated how simulations can be applied to get a visual understanding of investment decisions and returns, I want to apply this analysis to other problems. I’d love to hear requests for other questions of interest, but for now, I plan to look into:
I’ve been reading a lot of year-end/decade-end reflections (as one does this time of year) — and while a part of me wanted to #humblebrag about how I got a 🏠/💍/👶🏻 this decade 😇 — I thought it would be more interesting & profound to instead call out 10 worldviews & beliefs I had going into the 2010s that I no longer hold.
Sales is an unimportant skill relative to hard work / being smart As a stereotypical “good Asian kid” 🤓, I was taught to focus on nailing the task. I still think that focus is important early in one’s life & career, but this decade has made me realize that everyone, whether they know it or not, has to sell — you sell to employers to hire you, academics/nonprofits sell to attract donors and grant funding, even institutional investors have to sell to their investors/limited partners. Its a skill at least as important (if not more so).
Marriage is about finding your soul-mate and living happily ever after Having been married for slightly over half the decade, I’ve now come to believe that marriage is less about finding the perfect soul-mate (the “Hollywood version”) as it is about finding a life partner who you can actively choose to celebrate (despite and including their flaws, mistakes, and baggage). Its not that passionate love is unimportant, but its hard to rely on that alone to make a lifelong partnership work. I now believe that really boring-sounding things like how you make #adulting decisions and compatibility of communication style matter a lot more than things usually celebrated in fiction like the wedding planning, first dates, how nice your vacations together are, whether you can finish each other’s sentences, etc.
Industrial policy doesn’t work I tend to be a big skeptic of big government policy — both because of unintended consequences and the risks of politicians picking winners. But, a decade of studying (and working with companies who operate in) East Asian economies and watching how subsidies and economies of scale have made Asia the heart of much of advanced manufacturing have forced me to reconsider. Its not that the negatives don’t happen (there are many examples of China screwing things up with heavy-handed policy) but its hard to seriously think about how the world works without recognizing the role that industrial policy played. For more on how land management and industrial policies impacted economic development in different Asian countries, check out Joe Studwell’s book How Asia Works
Obesity & weight loss are simple — its just calories in & calories out From a pure physics perspective, weight gain is a “simple” thermodynamic equation of “calories in minus calories out”. But in working with companies focused on dealing with prediabetes/obesity, I’ve come to appreciate that this “logic” not only ignores the economic and social factors that make obesity a public health problem, it also overlooks that different kinds of foods drive different physiological responses. As an example that just begins to scratch the surface, one very well-controlled study (sadly, a rarity in the field) published in July showed that, even after controlling for exercise and calories, carbs, fat, fiber, and other nutrients present in a meal, diets consisting of processed foods resulted in greater weight-gain than a diet consisting of unprocessed foods
Revering luminaries & leaders is a good thing Its very natural to be so compelled by an idea / movement that you find yourself idolizing the people spearheading it. The media feeds into this with popular memoirs & biographies and numerous articles about how you can think/be/act more like [Steve Jobs/Jeff Bezos/Warren Buffett/Barack Obama/etc]. But, over the past decade, I’ve come to feel that this sort of reverence leads to a pernicious laziness of thought. I can admire Steve Jobs for his brilliance in product design but do I want to copy his approach to management or his use of alternative medicine to treat his cancer or condoning how he treated his illegitimate daughter. I think its far better to appreciate an idea and the work of the key people behind it than to equate the piece of work with the person and get sucked in to that cult of personality.
Startups are great place for everyone Call it being sucked into the Silicon valley ethos but for a long time I believed that startups were a great place for everyone to build a career: high speed path to learning & responsibility, ability to network with other folks, favorable venture funding, one of the only paths to getting stock in rapidly growing companies, low job seeking risk (since there’s an expectation that startups often fail or pivot). Several years spent working in VC and startups later, and, while I still agree with my list above, I’ve come to believe that startups are really not a great place for most people. The risk-reward is generally not great for all but the earliest of employees and the most successful of companies, and the “startups are great for learning” Kool-aid is oftentimes used to justify poor management and work practices. I still think its a great place for some (i.e. people who can tolerate more risk [b/c of personal wealth or a spouse with a stable high-paying job], who are knowingly optimizing for learning & responsibility, or who are true believers in a startup’s mission), but I frankly think most people don’t fit the bill.
Microaggressions are just people being overly sensitive I’ve been blessed at having only rarely faced overt racism (telling me to go back to China 🙄 / or that I don’t belong in this country). It’s a product of both where I’ve spent most of my life (in urban areas on the coasts) and my career/socioeconomic status (it’s not great to be overtly racist to a VC you’re trying to raise money from). But, having spent some dedicated time outside of those coastal areas this past decade and speaking with minorities who’ve lived there, I’ve become exposed to and more aware of “microaggressions”, forms of non-overt prejudice that are generally perpetrated without ill intent: questions like ‘so where are you really from?’ or comments like ‘you speak English really well!’. I once believed people complaining about these were simply being overly sensitive, but I’ve since become an active convert to the idea that, while these are certainly nowhere near as awful as overt hate crimes / racism, they are their own form of systematic prejudice which can, over time, grate and eat away at your sense of self-worth.
The Western model (liberal democracy, free markets, global institutions) will reign unchallenged as a model for prosperity I once believed that the Western model of (relatively) liberal democracy, (relatively) free markets, and US/Europe-led global institutions was the only model of prosperity that would reign falling the collapse of the Soviet Union. While I probably wouldn’t have gone as far as Fukuyama did in proclaiming “the end of history”, I believed that the world was going to see authoritarian regimes increasingly globalize and embrace Western institutions. What I did not expect was the simultaneous rise of different models of success by countries like China and Saudi Arabia (who, frighteningly, now serve as models for still other countries to embrace), as well as a lasting backlash within the Western countries themselves (i.e. the rise of Trump, Brexit, “anti-globalism”, etc). This has fractured traditional political divides (hence the soul-searching that both major parties are undergoing in the US and the UK) and the election of illiberal populists in places like Mexico, Brazil, and Europe.
Strategy trumps execution As a cerebral guy who spent the first years of his career in the last part of the 2000s as a strategy consultant, it shouldn’t be a surprise that much of my focus was on formulating smart business strategy. But having spent much of this decade focused on startups as well as having seen large companies like Apple, Amazon, and Netflix brilliantly out-execute companies with better ‘strategic positioning’ (Nokia, Blackberry, Walmart, big media), I’ve come around to a different understanding of how the two balance each other.
We need to invent radically new solutions to solve the climate crisis Its going to be hard to do this one justice in this limited space — especially since I net out here very differently from Bill Gates — but going into this decade, I never would have expected that the cost of new solar or wind energy facilities could be cheaper than the cost of operating an existing coal plant. I never thought that lithium batteries or LEDs would get as cheap or as good as they are today (with signs that this progress will continue) or that the hottest IPO of the year would be an alternative food technology company (Beyond Meat) which will play a key role in helping us mitigate food/animal-related emissions. Despite the challenges of being a cleantech investor for much of the decade, its been a surprising bright spot to see how much pure smart capital and market forces have pushed many of the technologies we need. I still think we will need new policies and a huge amount of political willpower — I’d also like to see more progress made on long-duration energy storage, carbon capture, and industrial — but whereas I once believed that we’d need radically new energy technologies to thwart the worst of climate change, I am now much more of an optimist here than I was when the decade started.
Here’s to more worldview shifts in the coming decade!
While it’s impossible to quantify all the intangibles of a college education, the tools of finance offers a practical, quantitative way to look at the tangible costs and benefits which can shed light on (1) whether to go to college / which college to go to, (2) whether taking on debt to pay for college is a wise choice, and (3) how best to design policies around student debt.
The below briefly walks through how finance would view the value of a college education and the soundness of taking on debt to pay for it and how it can help guide students / families thinking about applying and paying for colleges and, surprisingly, how there might actually be too little college debt and where policy should focus to address some of the issues around the burden of student debt.
The Finance View: College as an Investment
Through the lens of finance, the choice to go to college looks like an investment decision and can be evaluated in the same way that a company might evaluate investing in a new factory. Whereas a factory turns an upfront investment of construction and equipment into profits on production from the factory, the choice to go to college turns an upfront investment of cash tuition and missed salary while attending college into higher after-tax wages.
Finance has come up with different ways to measure returns for an investment, but one that is well-suited here is the internal rate of return (IRR). The IRR boils down all the aspects of an investment (i.e., timing and amount of costs vs. profits) into a single percentage that can be compared with the rates of return on another investment or with the interest rate on a loan. If an investment’s IRR is higher than the interest rate on a loan, then it makes sense to use the loan to finance the investment (i.e., borrowing at 5% to make 8%), as it suggests that, even if the debt payments are relatively onerous in the beginning, the gains from the investment will more than compensate for it.
To give an example: if Sally Student can get a starting salary after college in line with the average salary of an 18-24 year old Bachelor’s degree-only holder ($47,551), would have earned the average salary of an 18-24 year old high school diploma-only holder had she not gone to college ($30,696), and expects wage growth similar to what age-matched cohorts saw from 1997-2017, then the IRR of a 4-year degree at a non-profit private school if Sally pays the average net (meaning after subtracting grants and tax credits) tuition, fees, room & board ($26,740/yr in 2017, or a 4-year cost of ~$106,960), the IRR of that investment in college would be 8.1%.
Playing out different scenarios shows which factors are important in determining returns. An obvious factor is the cost of college:
T&F: Tuition & Fees; TFR&B: Tuition, Fees, Room & Board List: Average List Price; Net: Average List Price Less Grants and Tax Benefits Blue: In-State Public; Green: Private Non-Profit; Red: Harvard
As evident from the chart, there is huge difference between the rate of return Sally would get if she landed the same job but instead attended an in-state public school, did not have to pay for room & board, and got a typical level of financial aid (a stock-market-beating IRR of 11.1%) versus the world where she had to pay full list price at Harvard (IRR of 5.3%). In one case, attending college is a fantastic investment and Sally borrowing money to pay for it makes great sense (investors everywhere would love to borrow at ~5% and get ~11%). In the other, the decision to attend college is less straightforward (financially), and it would be very risky for Sally to borrow money at anything near subsidized rates to pay for it.
Some other trends jump out from the chart. Attending an in-state public university improves returns for the average college wage-earner by 1-2% compared with attending private universities (comparing the blue and green bars). Getting an average amount of financial aid (paying net vs list) also seems to improve returns by 0.7-1% for public schools and 2% for private.
As with college costs, the returns also understandably vary by starting salary:
There is a night and day difference between the returns Sally would see making $40K per year (~$10K more than an average high school diploma holder) versus if she made what the average Caltech graduate does post-graduation (4.6% vs 17.9%), let alone if she were to start with a six-figure salary (IRR of over 21%). If Sally is making six figures, she would be making better returns than the vast majority of venture capital firms, but if she were starting at $40K/yr, her rate of return would be lower than the interest rate on subsidized student loans, making borrowing for school financially unsound.
Time spent in college also has a big impact on returns:
Graduating sooner not only reduces the amount of foregone wages, it also means earning higher wages sooner and for more years. As a result, if Sally graduates in two years while still paying for four years worth of education costs, she would experience a higher return (12.6%) than if she were to graduate in three years and save one year worth of costs (11.1%)! Similarly, if Sally were to finish school in five years instead of four, this would lower her returns (6.3% if still only paying for four years, 5.8% if adding an extra year’s worth of costs). The result is that an extra / less year spent in college is a ~2% hit / boost to returns!
Finally, how quickly a college graduate’s wages growrelative to a high school diploma holder’s also has a significant impact on the returns to a college education:
Census/BLS data suggests that, between 1997 and 2017, wages of bachelor’s degree holders grew faster on an annualized basis by ~0.7% per year than for those with only a high school diploma (6.7% vs 5.8% until age 35, 4.0% vs 3.3% for ages 35-55, both sets of wage growth appear to taper off after 55).
The numbers show that if Sally’s future wages grew at the same rate as the wages of those with only a high school diploma, her rate of return drops to 5.3% (just barely above the subsidized loan rate). On the other hand, if Sally’s wages end up growing 1% faster until age 55 than they did for similar aged cohorts from 1997-2017, her rate of return jumps to a stock-market-beating 10.3%.
Lessons for Students / Families
What do all the charts and formulas tell a student / family considering college and the options for paying for it?
First, college can be an amazing investment, well worth taking on student debt and the effort to earn grants and scholarships. While there is well-founded concern about the impact that debt load and debt payments can have on new graduates, in many cases, the financial decision to borrow is a good one. Below is a sensitivity table laying out the rates of return across a wide range of starting salaries (the rows in the table) and costs of college (the columns in the table) and color codes how the resulting rates of return compare with the cost of borrowing and with returns in the stock market (red: risky to borrow at subsidized rates; white: does make sense to borrow at subsidized rates but it’s sensible to be mindful of the amount of debt / rates; green: returns are better than the stock market).
Except for graduates with well below average starting salaries (less than or equal to $40,000/yr), most of the cells are white or green. At the average starting salary, except for those without financial aid attending a private school, the returns are generally better than subsidized student loan rates. For those attending public schools with financial aid, the returns are better than what you’d expect from the stock market.
Secondly, there are ways to push returns to a college education higher. They involve effort and sometimes painful tradeoffs but, financially, they are well worth considering. Students / families choosing where to apply or where to go should keep in mind costs, average starting salaries, quality of career services, and availability of financial aid / scholarships / grants, as all of these factors will have a sizable impact on returns. After enrollment, student choices / actions can also have a meaningful impact: graduating in fewer semesters/quarters, taking advantage of career resources to research and network into higher starting salary jobs, applying for scholarships and grants, and, where possible, going for a 4th/5th year masters degree can all help students earn higher returns to help pay off any debt they take on.
Lastly, use the spreadsheet*! The figures and charts above are for a very specific set of scenarios and don’t factor in any particular individual’s circumstances or career trajectory, nor is it very intelligent about selecting what the most likely alternative to a college degree would be. These are all factors that are important to consider and may dramatically change the answer.
*To use the Google Sheet, you must be logged into a Google account; use the “Make a Copy” command in the File menu to save a version to your Google Drive and edit the tan cells with red numbers in them to whatever best matches your situation and see the impact on the yellow highlighted cells for IRR and the age when investment pays off
Implications for Policy on Student Debt
Given the growing concerns around student debt and rising tuitions, I went into this exercise expecting to find that the rates of return across the board would be mediocre for all but the highest earners. I was (pleasantly) surprised to discover that a college graduate earning an average starting salary would be able to achieve a rate of return well above federal loan rates even at a private (non-profit) university.
While the rate of return is not a perfect indicator of loan affordability (as it doesn’t account for how onerous the payments are compared to early salaries), the fact that the rates of return are so high is a sign that, contrary to popular opinion, there may actually be too little student debt rather than too much, and that the right policy goal may actually be to find ways to encourage the public and private sector to make more loans to more prospective students.
As for concerns around affordability, while proposals to cancel all student debt plays well to younger voters, the fact that many graduates are enjoying very high returns suggests that such a blanket policy is likely unnecessary, anti-progressive (after all, why should the government zero out the costs on high-return investments for the soon-to-be upper and upper-middle-classes), and fails to address the root cause of the issue (mainly that there shouldn’t be institutions granting degrees that fail to be good financial investments). Instead, a more effective approach might be:
Require all institutions to publish basic statistics (i.e. on costs, availability of scholarships/grants, starting salaries by degree/major, time to graduation, etc.) to help students better understand their own financial equation
Hold educational institutions accountable when too many students graduate with unaffordable loan burdens/payments (i.e. as a fraction of salary they earn and/or fraction of students who default on loans) and require them to make improvements to continue to qualify for federally subsidized loans
Making it easier for students to discharge student debt upon bankruptcy and increasing government oversight of collectors / borrower rights to prevent abuse
Government-supported loan modifications (deferrals, term changes, rate modifications, etc.) where short-term affordability is an issue (but long-term returns story looks good); loan cancellation in cases where debt load is unsustainable in the long-term (where long-term returns are not keeping up) or where debt was used for an institution that is now being denied new loans due to unaffordability
Making the path to public service loan forgiveness (where graduates who spend 10 years working for non-profits and who have never missed an interest payment get their student loans forgiven) clearer and addressing some of the issues which have led to 99% of applications to date being rejected
Special thanks Sophia Wang, Kathy Chen, and Dennis Coyle for reading an earlier version of this and sharing helpful comments!
You can learn a great deal from reading and comparing the financial filings of two close competitors. Tech-finance nerd that I am, you can imagine how excited I was to see Lyft’s and Uber’s respective S-1’s become public within mere weeks of each other.
For two-sided regional marketplaces like Lyft and Uber, an investor should understand the full economic picture for (1) the users/riders, (2) the drivers, and (3) the regional markets. Sadly, their S-1’s don’t make it easy to get much on (2) or (3) — probably because the companies consider the pertinent data to be highly sensitive information. They did, however, provide a fair amount of information on users/riders and rides and, after doing some simple calculations, a couple of interesting things emerged
Uber’s Users Spend More, Despite Cheaper Rides
As someone who first knew of Uber as the UberCab “black-car” service, and who first heard of Lyft as the Zimride ridesharing platform, I was surprised to discover that Lyft’s average ride price is significantly more expensive than Uber’s and the gap is growing! In Q1 2017, Lyft’s average bookings per ride was $11.74 and Uber’s was $8.41, a difference of $3.33. But, in Q4 2018, Lyft’s average bookings per ride had gone up to $13.09 while Uber’s had declined to $7.69, increasing the gap to $5.40.
This is especially striking considering the different definitions that Lyft and Uber have for “bookings” — Lyft excludes “ pass-through amounts paid to drivers and regulatory agencies, including sales tax and other fees such as airport and city fees, as well as tips, tolls, cancellation, and additional fees” whereas Uber’s includes “ applicable taxes, tolls, and fees “. This gap is likely also due to Uber’s heavier international presence (where they now generate 52% of their bookings). It would be interesting to see this data on a country-by-country basis (or, more importantly, a market-by-market one as well).
Interestingly, an average Uber rider appears to also take ~2.3 more rides per month than an average Lyft rider, a gap which has persisted fairly stably over the past 3 years even as both platforms have boosted the number of rides an average rider takes. While its hard to say for sure, this suggests Uber is either having more luck in markets that favor frequent use (like dense cities), with its lower priced Pool product vs Lyft’s Line product (where multiple users can share a ride), or its general pricing is encouraging greater use.
Note: the “~monthly” that you’ll see used throughout the charts in this post are because the aggregate data — rides, bookings, revenue, etc — given in the regulatory filings is quarterly, but the rider/user count provided is monthly. As a result, the figures here are approximations based on available data, i.e. by dividing quarterly data by 3
What does that translate to in terms of how much an average rider is spending on each platform? Perhaps not surprisingly, Lyft’s average rider spend has been growing and has almost caught up to Uber’s which is slightly down.
However, Uber’s new businesses like UberEats are meaningfully growing its share of wallet with users (and nearly perfectly dollar for dollar re-opens the gap on spend per user that Lyft narrowed over the past few years). In 2018 Q4, the gap between the yellow line (total bookings per user, including new businesses) and the red line (total bookings per user just for rides) is almost $10 / user / month! Its no wonder that in its filings, Lyft calls its users “riders”, but Uber calls them “Active Platform Consumers”.
Despite Pocketing More per Ride, Lyft Loses More per User
Long-term unit profitability is more than just how much an average user is spending, its also how much of that spend hits a company’s bottom line. Perhaps not surprisingly, because they have more expensive rides, a larger percent of Lyft bookings ends up as gross profit (revenue less direct costs to serve it, like insurance costs) — ~13% in Q4 2018 compared with ~9% for Uber. While Uber’s has bounced up and down, Lyft’s has steadily increased (up nearly 2x from Q1 2017). I would hazard a guess that Uber’s has also increased in its more established markets but that their expansion efforts into new markets (here and abroad) and new service categories (UberEats, etc) has kept the overall level lower.
Note: the gross margin I’m using for Uber adds back a depreciation and amortization line which were separated to keep the Lyft and Uber numbers more directly comparable. There may be other variations in definitions at work here, including the fact that Uber includes taxes, tolls, and fees in bookings that Lyft does not. In its filings, Lyft also calls out an analogous “Contribution Margin” which is useful but I chose to use this gross margin definition to try to make the numbers more directly comparable.
The main driver of this seems to be higher take rate (% of bookings that a company keeps as revenue) — nearly 30% in the case of Lyft in Q4 2018 but only 20% for Uber (and under 10% for UberEats)
Note: Uber uses a different definition of take rate in their filings based on a separate cut of “Core Platform Revenue” which excludes certain items around referral fees and driver incentives. I’ve chosen to use the full revenue to be more directly comparable
The higher take rate and higher bookings per user has translated into an impressive increase in gross profit per user. Whereas Lyft once lagged Uber by almost 50% on gross profit per user at the beginning of 2017, Lyft has now surpassed Uber even after adding UberEats and other new business revenue to the mix.
All of this data begs the question, given Lyft’s growth and lead on gross profit per user, can it grow its way into greater profitability than Uber? Or, to put it more precisely, are Lyft’s other costs per user declining as it grows? Sadly, the data does not seem to pan out that way
While Uber had significantly higher OPEX (expenditures on sales & marketing, engineering, overhead, and operations) per user at the start of 2017, the two companies have since reversed positions, with Uber making significant changes in 2018 which lowered its OPEX per user spend to under $9 whereas Lyft’s has been above $10 for the past two quarters. The result is Uber has lost less money per user than Lyft since the end of 2017
The story is similar for profit per ride. Uber has consistently been more profitable since 2017, and they’ve only increased that lead since. This is despite the fact that I’ve included the costs of Uber’s other businesses in their cost per ride.
One possible interpretation of Lyft’s higher OPEX spend per user is that Lyft is simply investing in operations and sales and engineering to open up new markets and create new products for growth. To see if this strategy has paid off, I took a look at the Lyft and Uber’s respective user growth during this period of time.
The data shows that Lyft’s compounded quarterly growth rate (CQGR) from Q1 2016 to Q4 2018 of 16.4% is only barely higher than Uber’s at 15.3% which makes it hard to justify spending nearly $2 more per user on OPEX in the last two quarters.
Interestingly, despite all the press and commentary about #deleteUber, it doesn’st seem to have really made a difference in their overall user growth (its actually pretty hard to tell from the chart above that the whole thing happened around mid-Q1 2017).
How are Drivers Doing?
While there is much less data available on driver economics in the filings, this is a vital piece of the unit economics story for a two-sided marketplace. Luckily, Uber and Lyft both provide some information in their S-1’s on the number of drivers on each platform in Q4 2018 which are illuminating.
The average Uber driver on the platform in Q4 2018 took home nearly double what the average Lyft driver did! They were also more likely to be “utilized” given that they handled 136% more rides than the average Lyft driver and, despite Uber’s lower price per ride, saw more total bookings.
It should be said that this is only a point in time comparison (and its hard to know if Q4 2018 was an odd quarter or if there is odd seasonality here) and it papers over many other important factors (what taxes / fees / tolls are reflected, none of these numbers reflect tips, are some drivers doing shorter shifts, what does this look like specifically in US/Canada vs elsewhere, are all Uber drivers benefiting from doing both UberEats and Uber rideshare, etc). But the comparison is striking and should be alarming for Lyft.
Closing Thoughts
I’d encourage investors thinking about investing in either to do their own deeper research (especially as the competitive dynamic is not over one large market but over many regional ones that each have their own attributes). That being said, there are some interesting takeaways from this initial analysis
Lyft has made impressive progress at increasing the value of rides on its platform and increasing the share of transactions it gets. One would guess that, Uber, within established markets in the US has probably made similar progress.
Despite the fact that Uber is rapidly expanding overseas into markets that face more price constraints than in the US, it continues to generate significantly better user economics and driver economics (if Q4 2018 is any indication) than Lyft.
Something happened at Uber at the end of 2017/start of 2018 (which looks like it coincides nicely with Dara Khosrowshahi’s assumption of CEO role) which led to better spending discipline and, as a result, better unit economics despite falling gross profits per user
Uber’s new businesses (in particular UberEats) have had a significant impact on Uber’s share of wallet.
Lyft will need to find more cost-effective ways of growing its business and servicing its existing users & drivers if it wishes to achieve long-term sustainability as its current spend is hard to justify relative to its user growth.
Special thanks to Eric Suh for reading and editing an earlier version!
There’s been a fair amount of talk lately about proactively regulating — and maybe even breaking up — the “Big Tech” companies.
Full disclosure: this post discusses regulating large tech companies. I own shares in several of these both directly (in the case of Facebook and Microsoft) and indirectly (through ETFs that own stakes in large companies)
Like many, I have become increasingly uneasy over the fact that a small handful of companies, with few credible competitors, have amassed so much power over our personal data and what information we see. As a startup investor and former product executive at a social media startup, I can especially sympathize with concerns that these large tech companies have created an unfair playing field for smaller companies.
At the same time, though, I’m mindful of all the benefits that the tech industry — including the “tech giants” — have brought: amazing products and services, broader and cheaper access to markets and information, and a tremendous wave of job and wealth creation vital to may local economies. For that reason, despite my concerns of “big tech”‘s growing power, I am wary of reaching for “quick fixes” that might change that.
Another factor which complicates tech policy is that the traditional “big is bad” mentality ignores the benefits to having large platforms. While Amazon’s growth has hurt many brick & mortar retailers and eCommerce competitors, its extensive reach and infrastructure enabled businesses like Anker and Instant Pot to get to market in a way which would’ve been virtually impossible before. While the dominance of Google’s Android platform in smartphones raised concerns from European regulators, its hard to argue that the companies which built millions of mobile apps and tens of thousands of different types of devices running on Android would have found it much more difficult to build their businesses without such a unified software platform. Policy aimed at “Big Tech” should be wary of dismantling the platforms that so many current and future businesses rely on.
Its also important to remember that poorly crafted regulation in tech can be self-defeating. The most effective way to deal with the excesses of “Big Tech”, historically, has been creating opportunities for new market entrants. After all, many tech companies previously thought to be dominant (like Nokia, IBM, and Microsoft) lost their positions, not because of regulation or antitrust, but because new technology paradigms (i.e. smartphones, cloud), business models (i.e. subscription software, ad-sponsored), and market entrants (i.e. Google, Amazon) had the opportunity to flourish. Because rules (i.e. Article 13/GDPR) aimed at big tech companies generally fall hardest on small companies (who are least able to afford the infrastructure / people to manage it), its important to keep in mind how solutions for “Big Tech” problems affect smaller companies and new concepts as well.
To be 100% clear, I’m not saying that the tech industry and big platforms should be given a pass on rules and regulation. If anything, I believe that laws and regulation play a vital role in creating flourishing markets.
But, instead of treating “Big Tech” as just a problem to kill, I think we’d be better served by laws / regulations that recognize the limits of regulation on tech and, instead, focus on making sure emerging companies / technologies can compete with the tech giants on a level playing field. To that end, I hope to see more ideas that embrace the following four pillars:
I. Tiering regulation based on size of the company
Regulations on tech companies should be tiered based on size with the most stringent rules falling on the largest companies. Size should include traditional metrics like revenue but also, in this age of marketplace platforms and freemium/ad-sponsored business models, account for the number of users (i.e. Monthly Active Users) and third party partners.
In this way, the companies with the greatest potential for harm and the greatest ability to bear the costs face the brunt of regulation, leaving smaller companies & startups with greater flexibility to innovate and iterate.
II. Championing data portability
One of the reasons it’s so difficult for competitors to challenge the tech giants is the user lock-in that comes from their massive data advantage. After all, how does a rival social network compete when a user’s photos and contacts are locked away inside Facebook?
While Facebook (and, to their credit, some of the other tech giants) does offer ways to export user data and to delete user data from their systems, these tend to be unwieldy, manual processes that make it difficult for a user to bring their data to a competing service. Requiring the largest tech platforms to make this functionality easier to use (i.e., letting others import your contact list and photos with the ease in which you can login to many apps today using Facebook) would give users the ability to hold tech companies accountable for bad behavior or not innovating (by being able to walk away) and fosters competition by letting new companies compete not on data lock-in but on features and business model.
I believe that is an overreaction. Platform owners offering attractive products and services (i.e., Google offering turn-by-turn navigation on Android phones) can be a great thing for users (after all, most prominent platforms started by providing compelling first-party offerings) and for 3rd party participants if these offerings improve the attractiveness of the platform overall.
What is hard to justify is when platform owners stack the deck in their favor using anti-competitive moves such as banning or reducing the visibility of competitors,crippling third party offerings, making excessive demands on 3rd parties, etc. Its these sorts of actions by the largest tech platforms that pose a risk to consumer choice and competition and should face regulatory scrutiny. Not just the fact that a large platform exists or that the platform owner chooses to participate in it.
IV. Modernizing how anti-trust thinks about defensive acquisitions
The rise of the tech giants has led to many calls to unwind some of the pivotal mergers and acquisitions in the space. As much as I believe that anti-trust regulators made the wrong calls on some of these transactions, I am not convinced, beyond just wanting to punish “Big Tech” for being big, that the Pandora’s Box of legal and financial issues (for the participants, employees, users, and for the tech industry more broadly) that would be opened would be worthwhile relative to pursuing other paths to regulate bad behavior directly.
That being said, its become clear that anti-trust needs to move beyond narrow revenue share and pricing-based definitions of anti-competitiveness (which do not always apply to freemium/ad-sponsored business models). Anti-trust prosecutors and regulators need to become much more thoughtful and assertive around how some acquisitions are done simply to avoid competition (i.e., Google’s acquisition of Waze and Facebook’s acquisition of WhatsApp are two examples of landmark acquisitions which probably should have been evaluated more closely).
This is hardly a complete set of rules and policies needed to approach growing concerns about “Big Tech”. Even within this framework, there are many details (i.e., who the specific regulators are, what specific auditing powers they have, the details of their mandate, the specific thresholds and number of tiers to be set, whether pre-installing an app counts as unfair, etc.) that need to be defined which could make or break the effort. But, I believe this is a good set of principles that balances both the need to foster a tech industry that will continue to grow and drive innovation as well as the need to respond to growing concerns about “Big Tech”.
Special thanks to Derek Yang and Anthony Phan for reading earlier versions and giving me helpful feedback!
Having been lucky enough to invest in both tech (cloud, mobile, software) and “deeptech” (materials, cleantech, energy, life science) startups (and having also ran product at a mobile app startup), it has been striking to see how fundamentally different the paradigms that drive success in each are.
Whether knowingly or not, most successful tech startups over the last decade have followed a basic playbook:
Take advantage of rising smartphone penetration and improvements in cloud technology to build digital products that solve challenges in big markets pertaining to access (e.g., to suppliers, to customers, to friends, to content, to information, etc.)
Build a solid team of engineers, designers, growth, sales, marketing, and product people to execute on lean software development and growth methodologies
Hire the right executives to carry out the right mix of tried-and-true as well as “out of the box” channel and business developmentstrategies to scale bigger and faster
This playbook appears deceptively simple but is very difficult to execute well. It works because for markets where “software is eating the world”:
There is relatively little technology risk: With the exception of some of the most challenging AI, infrastructure, and security challenges, most tech startups are primarily dealing with engineering and product execution challenges — what is the right thing to build and how do I build it on time, under budget? — rather than fundamental technology discovery and feasibility challenges
Skills & knowledge are broadly transferable: Modern software development and growth methodologies work across a wide range of tech products and markets. This means that effective engineers, salespeople, marketers, product people, designers, etc. at one company will generally be effective at another. As a result, its a lot easier for investors/executives to both gauge the caliber of a team (by looking at their experience) and augment a team when problems arise (by recruiting the right people with the right backgrounds).
Distribution is cheap and fast: Cloud/mobile technology means that a new product/update is a server upgrade/browser refresh/app store download away. This has three important effects:
The first is that startups can launch with incomplete or buggy solutions because they can readily provide hotfixes and upgrades.
The second is that startups can quickly release new product features and designs to respond to new information and changing market conditions.
The third is that adoption is relatively straightforward. While there may be some integration and qualification challenges, in general, the product is accessible via a quick download/browser refresh, and the core challenge is in getting enough people to use a product in the right way.
In contrast, if you look at deeptech companies, a very different set of rules apply:
Technology risk/uncertainty is inherent: One of the defining hallmarks of a deeptech company is dealing with uncertainty from constraints imposed by reality (i.e. the laws of physics, the underlying biology, the limits of current technology, etc.). As a result, deeptech startups regularly face feasibility challenges — what is even possible to build? — and uncertainty around the R&D cycles to get to a good outcome — how long will it take / how much will it cost to figure this all out?
Skills & knowledge are not easily transferable: Because the technical and business talent needed in deeptech is usually specific to the field, talent and skills are not necessarily transferable from sector to sector or even company to company. The result is that it is much harder for investors/executives to evaluate team caliber (whether on technical merits or judging past experience) or to simply put the right people into place if there are problems that come up.
Product iteration is slow and costly: The tech startup ethos of “move fast and break things” is just harder to do with deeptech.
At the most basic level, it just costs a lot more and takes a lot more time to iterate on a physical product than a software one. It’s not just that physical products require physical materials and processing, but the availability of low cost technology platforms like Amazon Web Services and open source software dramatically lower the amount of time / cash needed to make something testable in tech than in deeptech.
Furthermore, because deeptech innovations tend to have real-world physical impacts (to health, to safety, to a supply chain/manufacturing line, etc.), deeptech companies generally face far more regulatory and commercial scrutiny. These groups are generally less forgiving of incomplete/buggy offerings and their assessments can lengthen development cycles. Deeptech companies generally can’t take the “ask for forgiveness later” approaches that some tech companies (i.e. Uber and AirBnb) have been able to get away with (exhibit 1: Theranos).
As a result, while there is no single playbook that works across all deeptech categories, the most successful deeptech startups tend to embody a few basic principles:
Go after markets where there is a very clear, unmet need: The best deeptech entrepreneurs tend to take very few chances with market risk and only pursue challenges where a very well-defined unmet need (i.e., there are no treatments for Alzheimer’s, this industry needs a battery that can last at least 1000 cycles, etc) blocks a significant market opportunity. This reduces the risk that a (likely long and costly) development effort achieves technical/scientific success without also achieving business success. This is in contrast with tech where creating or iterating on poorly defined markets (i.e., Uber and Airbnb) is oftentimes at the heart of what makes a company successful.
Focus on “one miracle” problems: Its tempting to fantasize about what could happen if you could completely re-write every aspect of an industry or problem but the best deeptech startups focus on innovating where they won’t need the rest of the world to change dramatically in order to have an impact (e.g., compatible with existing channels, business models, standard interfaces, manufacturing equipment, etc). Its challenging enough to advance the state of the art of technology — why make it even harder?
Pursue technologies that can significantly over-deliver on what the market needs: Because of the risks involved with developing advanced technologies, the best deeptech entrepreneurs work in technologies where even a partial success can clear the bar for what is needed to go to market. At the minimum, this reduces the risk of failure. But, hopefully, it gives the company the chance to fundamentally transform the market it plays in by being 10x better than the alternatives. This is in contrast to many tech markets where market success often comes less from technical performance and more from identifying the right growth channels and product features to serve market needs (i.e., Facebook, Twitter, and Snapchat vs. MySpace, Orkut, and Friendster; Amazon vs. brick & mortar bookstores and electronics stores)
All of this isn’t to say that there aren’t similarities between successful startups in both categories — strong vision, thoughtful leadership, and success-oriented cultures are just some examples of common traits in both. Nor is it to denigrate one versus the other. But, practically speaking, investing or operating successfully in both requires very different guiding principles and speaks to the heart of why its relatively rare to see individuals and organizations who can cross over to do both.
Special thanks to Sophia Wang, Ryan Gilliam, and Kevin Lin Lee for reading an earlier draft and making this better!
(Update Jan 2021: Bitnami has made available a new tool bncert which makes it even easier to enable HTTPS with a Let’s Encrypt certificate; the instructions below using Let’s Encrypt’s certbot still work but I would recommend people looking to enable HTTPS to use Bitnami’s new bncert process)
I recently made two big changes to the backend of this website to keep up with the times as internet technology continues to evolve.
For anyone who is also interested in migrating an existing WordPress deployment on another host to AWS Lightsail and turning on HTTPS/SSL, here are the steps I followed (gleamed from some online research and a bit of trial & error). Its not as straightforward as some other setups, but its very do-able if you are willing to do a little bit of work in the AWS console:
Follow the (fairly straightforward) instructions in the AWS Lightsail tutorial around setting up a clean WordPress deployment. I would skip sub-step 3 of step 6 (directing your DNS records to point to the Lightsail nameservers) until later (when you’re sure the transfer has worked so your domain continues to point to a functioning WordPress deployment).
Unless you are currently not hosting any custom content (no images, no videos, no Javascript files, etc) on your WordPress deployment, I would ignore the WordPress migration tutorial at the AWS Lightsail website (which won’t show you how to transfer this custom content over) in favor of this Bitnami how-to-guide (Bitnami provides the WordPress server image that Lightsail uses for its WordPress instance) which takes advantage of the fact that the Bitnami WordPress includes the All-in-One WP Migration plugin which, for free, can do single file backups of your WordPress site up to 512 MB (larger sites will need to pay for the premium version of the plugin).
Note: if, like me, you are using Jetpack’s site accelerator to cache your images/static file assets, don’t worry if upon visiting your site some of the images appear broken. Jetpack relies on the URL of the asset to load correctly. This should get resolved once you point your DNS records accordingly (literally the next step) and any other issues should go away after you mop up any remaining references to the wrong URLs in your database (see the bullet below where I reference the Better Search Replace plugin).
If you followed my advice above, now would be the time to change your DNS records to point to the Lightsail nameservers (sub-step 3 of step 6 of the AWS Lightsail WordPress tutorial) — wait a few hours to make sure the DNS settings have propagated and then test out your domain and make sure it points to a page with the Bitnami banner in the lower right (sign that you’re using the Bitnami server image, see below)
The Bitnami banner in the lower-right corner of the page you should see if your DNS propagated correctly and your Lightsail instance is up and running
To remove that ugly banner, follow the instructions in this tutorial (use the AWS Lightsail panel to get to the SSH server console for your instance and, assuming you followed the above instructions, follow the instructions for Apache)
Assuming your webpage and domain all work (preferably without any weird uptime or downtime issues), you can proceed with this tutorial to provision a Let’s Encrypt SSL certificate for your instance. It can be a bit tricky as it entails spending a lot of time in the SSH server console (which you can get to from the AWS Lightsail panel) and tweaking settings in the AWS Lightsail DNS Zone manager, but the tutorial does a good job of walking you through all of it. (Update Jan 2021: Bitnami has made available a new tool bncert which makes it even easier to enable HTTPS. While the link above using Let’s Encrypt’s certbot still works, I would recommend people use Bitnami’s new bncert process going forward)
I would strongly encourage you to wait to make sure all the DNS settings have propagated and that your instance is not having any strange downtime (as mine did when I first tried this) as if you have trouble connecting to your page, it won’t be immediately clear what is to blame and you won’t be able to take reactive measures.
I used the plugin Better Search Replace to replace all references to intermediate domains (i.e. the IP addresses for your Lightsail instance that may have stuck around after the initial step in Step 1) or the non-HTTPS domains (i.e. http://yourdomain.com or http://www.yourdomain.com) with your new HTTPS domain in the MySQL databases that power your WordPress deployment (if in doubt, just select the wp_posts table). You can also take this opportunity to direct all your yourdomain.com traffic to www.yourdomain.com (or vice versa). You can also do this directly in MySQL but the plugin allows you to do this across multiple tables very easily and allows you to do a “dry run” first where it finds and counts all the times it will make a change before you actually execute it.
(Update Jan 2021: Bitnami has made available a new tool bncert which makes it even easier to enable HTTPS and also automatically handles the redirect. While the instructions below still technically work, I would just use Bitnami’s new bncert process going forward)If you want to redirect all the traffic to www.yourdomain.com to yourdomain.com, you have two options. If your domain registrar is forward thinking and does simple redirects for you like Namecheap does, that is probably the easiest path. That is sadly not the path I took because I transferred my domain over to AWS’s Route 53 which is not so enlightened. If you also did the same thing / have a domain registrar that is not so forward thinking, you can tweak the Apache server settings to achieve the same effect. To do this, go into the SSH server console for your Lightsail instance and:
Run cd ~/apps/wordpress/conf
To make a backup which you can restore (if you screw things up) run mv httpd-app.conf httpd-app.conf.old
I’m going to use the Nano editor because its the easiest for a beginner (but feel free to use vi or emacs if you prefer), but run nano httpd-app.conf
Use your cursor and find the line that says RewriteEngine On that is just above the line that says #RewriteBase /wordpress/
Enter the following lines
# begin www to non-www
RewriteCond %{HTTP_HOST} ^www\.(.*)$ [NC]
RewriteRule ^(.*)$ https://%1/$1 [R=permanent,L]
# end www to non-www
The first and last line are just comments so that you can go back and remind yourself of what you did and where. The middle two lines are where the server recognizes incoming URL requests and redirects them accordingly
With any luck, your file will look like the image below — hit ctrl+X to exit, and hit ‘Y’ when prompted (“to save modified buffer”) to save your work
Run sudo /opt/bitnami/ctlscript.sh restart to restart your server and test out the domain in a browser to make sure everything works
If things go bad, run mv httpd-app.conf.old httpd-app.conf and then restart everything by running sudo /opt/bitnami/ctlscript.sh restart
What httpd-app.conf should look like in your Lightsail instance SSH console after the edits
I’ve only been using AWS Lightsail for a few days, but my server already feels much more responsive. It’s also nice to go to my website and not see “not secure” in my browser address bar (its also apparently an SEO bump for most search engines). Its also great to know that Lightsail is integrated deeply into AWS which makes the additional features and capabilities that have made AWS the industry leader (i.e. load balancers, CloudFront as CDN, scaling up instance resources, using S3 as a datastore, or even ultimately upgrading to full-fledged EC2 instances) are readily available.
Person X on your team reflects poorly on your company — This is tough advice to give as its virtually impossible during the course of a pitch to build enough rapport and get a deep enough understanding of the inter-personal dynamics of the team to give that advice without it unnecessarily hurting feelings or sounding incredibly arrogant / meddlesome.
Your slides look awful — This is difficult to say in a pitch because it just sounds petty for an investor to complain about the packaging rather than the substance.
Be careful when using my portfolio companies as examples — While its good to build rapport / common ground with your VC audience, using their portfolio companies as examples has an unnecessarily high chance of backfiring. It is highly unlikely that you will know more than an inside investor who is attending board meetings and in direct contact with management, so any errors you make (i.e., assuming a company is doing well when it isn’t or assuming a company is doing poorly when it is doing well / is about to turn the corner) are readily caught and immediately make you seem foolish.
You should pitch someone who’s more passionate about what you’re doing — Because VCs have to risk their reputation within their firms / to the outside world for the deals they sign up to do, they have to be very selective about which companies they choose to get involved with. As a result, even if there’s nothing wrong with a business model / idea, some VCs will choose not to invest due simply to lack of passion. As the entrepreneur is probably deeply passionate about and personally invested in the market / problem, giving this advice can feel tantamount to insulting the entrepreneur’s child or spouse.
Hopefully this gives some of the hard-working entrepreneurs out there some context on why a pitch didn’t go as well as they had hoped and maybe some pointers on who and how to approach an investor for their next pitch.
I’m oftentimes asked what determines the prices that companies get bought for: after all, why does one app company get bought for $19 billion and a similar app get bought at a discount to the amount of investor capital that was raised?
While specific transaction values depend a lot on the specific acquirer (i.e. how much cash on hand they have, how big they are, etc.), I’m going to share a framework that has been very helpful to me in thinking about acquisition valuations and how startups can position themselves to get more attractive offers. The key is understanding that, all things being equal, why you’re being acquired determines the buyer’s willingness to pay. These motivations fall on a spectrum dividing acquisitions into four types:
Talent Acquisitions: These are commonly referred to in the tech press as “acquihires”. In these acquisitions, the buyer has determined that it makes more sense to buy a team than to spend the money, time, and effort needed to recruit a comparable one. In these acquisitions, the size and caliber of the team determine the purchase price.
Asset / Capability Acquisitions: In these acquisitions, the buyer is in need of a particular asset or capability of the target: it could be a portfolio of patents, a particular customer relationship, a particular facility, or even a particular product or technology that helps complete the buyer’s product portfolio. In these acquisitions, the uniqueness and potential business value of the assets determine the purchase price.
Business Acquisitions: These are acquisitions where the buyer values the target for the success of its business and for the possible synergies that could come about from merging the two. In these acquisitions, the financials of the target (revenues, profitability, growth rate) as well as the benefits that the investment bankers and buyer’s corporate development teams estimate from combining the two businesses (cost savings, ability to easily cross-sell, new business won because of a more complete offering, etc) determine the purchase price.
Strategic Gamechangers: These are acquisitions where the buyer believes the target gives them an ability to transform their business and is also a critical threat if acquired by a competitor. These tend to be acquisitions which are priced by the buyer’s full ability to pay as they represent bets on a future.
What’s useful about this framework is that it gives guidance to companies who are contemplating acquisitions as exit opportunities:
If your company is being considered for a talent acquisition, then it is your job to convince the acquirer that you have built assets and capabilities above and beyond what your team alone is worth. Emphasize patents, communities, developer ecosystems, corporate relationships, how your product fills a distinct gap in their product portfolio, a sexy domain name, anything that might be valuable beyond just the team that has attracted their interest.
If a company is being considered for an asset / capability acquisition, then the key is to emphasize the potential financial trajectory of the business and the synergies that can be realized after a merger. Emphasize how current revenues and contracts will grow and develop, how a combined sales and marketing effort will be more effective than the sum of the parts, and how the current businesses are complementary in a real way that impacts the bottom line, and not just as an interesting “thing” to buy.
If a company is being evaluated as a business acquisition, then the key is to emphasize how pivotal a role it can play in defining the future of the acquirer in a way that goes beyond just what the numbers say about the business. This is what drives valuations like GM’s acquisition of Cruise (which was a leader in driverless vehicle technology) for up to $1B, or Facebook’s acquisition of WhatsApp (messenger app with over 600 million users when it was acquired, many in strategic regions for Facebook) for $19B, or Walmart’s acquisition of Jet.com (an innovator in eCommerce that Walmart needs to help in its war for retail marketshare with Amazon.com).
The framework works for two reasons: (1) companies are bought, not sold, and the price is usually determined by the party that is most willing to walk away from a deal (that’s usually the buyer) and (2) it generally reflects how most startups tend to create value over time: they start by hiring a great team, who proceed to build compelling capabilities / assets, which materialize as interesting businesses, which can represent the future direction of an industry.
Hopefully, this framework helps any tech industry onlooker wondering why acquisition valuations end up at a certain level or any startup evaluating how best to court an acquisition offer.
A look at what Snap’s S-1 reveals about their growth story and unit economics
If you follow the tech industry at all, you will have heard that consumer app darling Snap Inc. (makers of the app Snapchat) has filed to go public. The ensuing Form S-1 that has recently been made available has left tech-finance nerds like yours truly drooling over the until-recently-super-secretive numbers behind their business.
While full-time Wall Street analysts will pour over the figures and comparables in much greater detail than I can, I decided to take a quick peek at the numbers to gauge for myself how the business is doing as a growth investment, looking at:
What does the growth story look like for the business?
Do the unit economics allow for a path to profitability?
What does the growth story look like for the business?
As I’ve noted before, consumer media businesses like Snap have two options available to grow: (1) increase the number of users / amount of time spent and/or (2) better monetize users over time
A quick peek at the DAU (Daily Active Users) counts of Snap reveal that path (1) is troubled for them. Using Facebook as a comparable (and using the midpoint of Facebook’s quarter-end DAU counts to line up with Snap’s average DAU over a quarter) reveals not only that Snap’s DAU numbers aren’t growing so much, their growth outside of North America (where they should have more room to grow) isn’t doing that great either (which is especially alarming as the S-1 admits Q4 is usually seasonally high for them).
Last 3 Quarters of DAU growth, by region
A quick look at the data also reveals why Facebook prioritizes Android development and low-bandwidth-friendly experiences — international remains an area of rapid growth which is especially astonishing considering how over 1 billion Facebook users are from outside of North America. This contrasts with Snap which, in addition to needing a huge amount of bandwidth (as a photo and video intensive platform) also (as they admitted in their S-1) de-emphasizes Android development. Couple that with Snap’s core demographic (read: old people can’t figure out how to use the app), reveals a challenge to where quick short-term user growth can come from.
As a result, Snap’s growth in the near term will have to be driven more by path (2). Here, there is a lot more good news. Snap’s quarterly revenue per user more than doubled over the last 3 quarters to $1.029/DAU. While its a long way off from Facebook’s whopping $7.323/DAU (and over $25 if you’re just looking at North American users), it suggests that there is plenty of opportunity for Snap to increase monetization, especially overseas where its currently able to only monetize about 1/10 as effectively as they are in North America (compared to Facebook which is able to do so 1/5 to 1/6 of North America depending on the quarter).
2016 and 2015 Q2-Q4 Quarterly Revenue per DAU, by region
Considering Snap has just started with its advertising business and has already convinced major advertisers to build custom content that isn’t readily reusable on other platforms and Snap’s low revenue per user compared even to Facebook’s overseas numbers, I think its a relatively safe bet that there is a lot of potential for the number to go up.
Do the unit economics allow for a path to profitability?
While most folks have been (rightfully) stunned by the (staggering) amount of money Snap lost in 2016, to me the more pertinent question (considering the over $1 billion Snap still has in its coffers to weather losses) is whether or not there is a path to sustainable unit economics. Or, put more simply, can Snap grow its way out of unprofitability?
Because neither Facebook nor Snap provide regional breakdowns of their cost structure, I’ve focused on global unit economics, summarized below:
2016 and 2015 Q2-Q4 Quarterly Financials per DAU
What’s astonishing here is that neither Snap nor Facebook seem to be gaining much from scale. Not only are their costs of sales per user (cost of hosting infrastructure and advertising infrastructure) increasing each quarter, but the operating expenses per user (what they spend on R&D, sales & marketing, and overhead — so not directly tied to any particular user or dollar of revenue) don’t seem to be shrinking either. In fact, Facebook’s is over twice as large as Snap’s — suggesting that its not just a simple question of Snap growing a bit further to begin to experience returns to scale here.
What makes the Facebook economic machine go, though, is despite the increase in costs per user, their revenue per user grows even faster. The result is profit per user is growing quarter to quarter! In fact, on a per user basis, Q4 2016 operating profit exceeded Q2 2015 gross profit(revenue less cost of sales, so not counting operating expenses)! No wonder Facebook’s stock price has been on a tear!
While Snap has also been growing its revenue per user faster than its cost of sales (turning a gross profit per user in Q4 2016 for the first time), the overall trendlines aren’t great, as illustrated by the fact that its operating profit per user has gotten steadily worse over the last 3 quarters. The rapid growth in Snap’s costs per user and the fact that Facebook’s costs are larger and still growing suggests that there are no simple scale-based reasons that Snap will achieve profitability on a per user basis. As a result, the only path for Snap to achieve sustainability on unit economics will be to pursue huge growth in user monetization.
Tying it Together
The case for Snap as a good investment really boils down to how quickly and to what extent one believes that the company can increase their monetization per user. While the potential is certainly there (as is being realized as the rapid growth in revenue per user numbers show), what’s less clear is whether or not the company has the technology or the talent (none of the key executives named in the S-1 have a particular background building advertising infrastructure or ecosystems that Google, Facebook, and even Twitter did to dominate the online advertising businesses) to do it quickly enough to justify the rumored $25 billion valuation they are striving for (a whopping 38x sales multiple using 2016 Q4 revenue as a run-rate [which the S-1 admits is a seasonally high quarter]).
What is striking to me, though, is that Snap would even attempt an IPO at this stage. In my mind, Snap has a very real shot at being a great digital media company of the same importance as Google and Facebook and, while I can appreciate the hunger from Wall Street to invest in a high-growth consumer tech company, not having a great deal of visibility / certainty around unit economics and having only barely begun monetization (with your first quarter where revenue exceeds cost of sales is a holiday quarter) poses challenges for a management team that will need to manage public market expectations around forecasts and capitalization.
In any event, I’ll be looking forward to digging in more when Snap reveals future figures around monetization and advertising strategy — and, to be honest, Facebook’s numbers going forward now that I have a better appreciation for their impressive economic model.




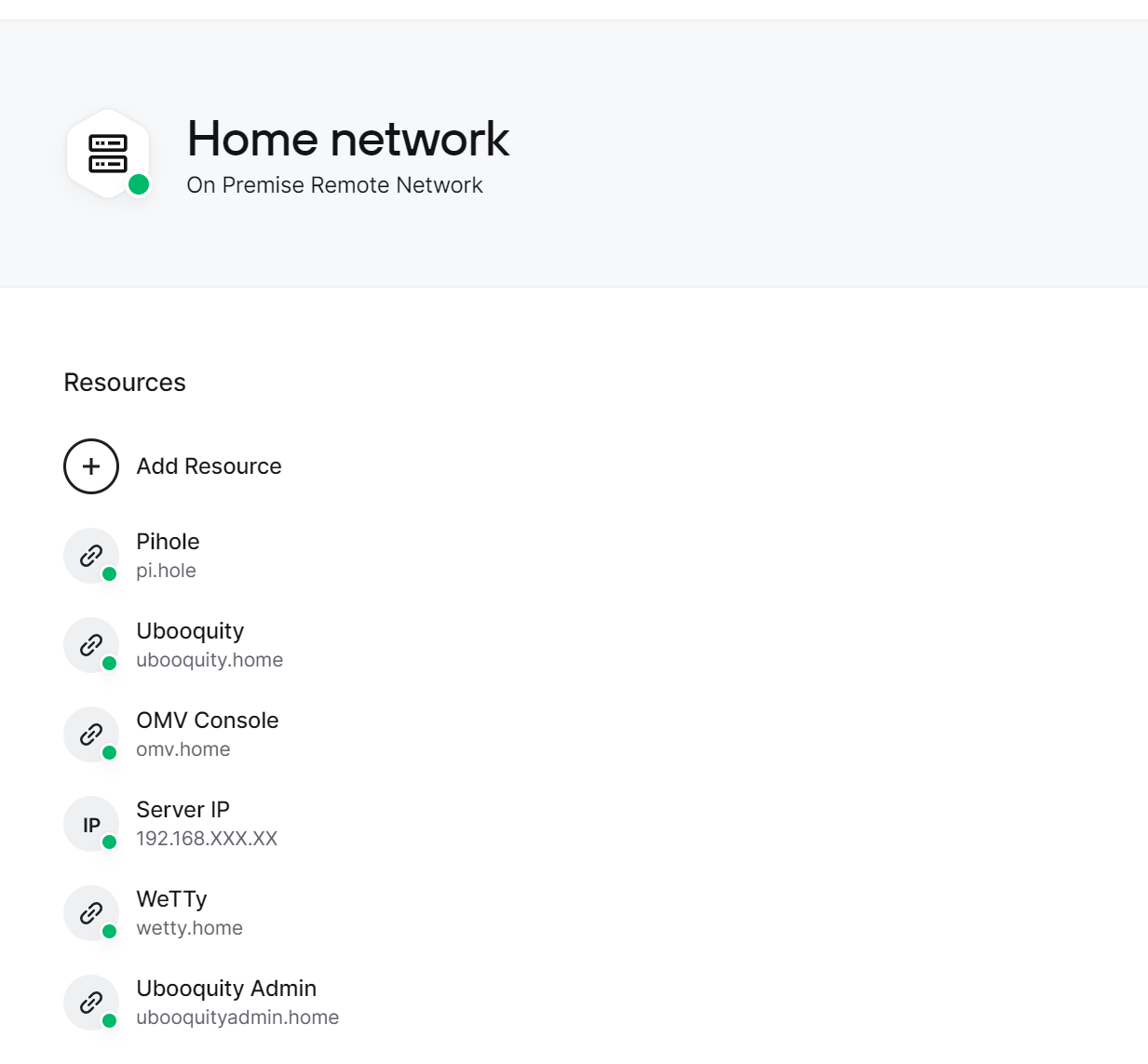
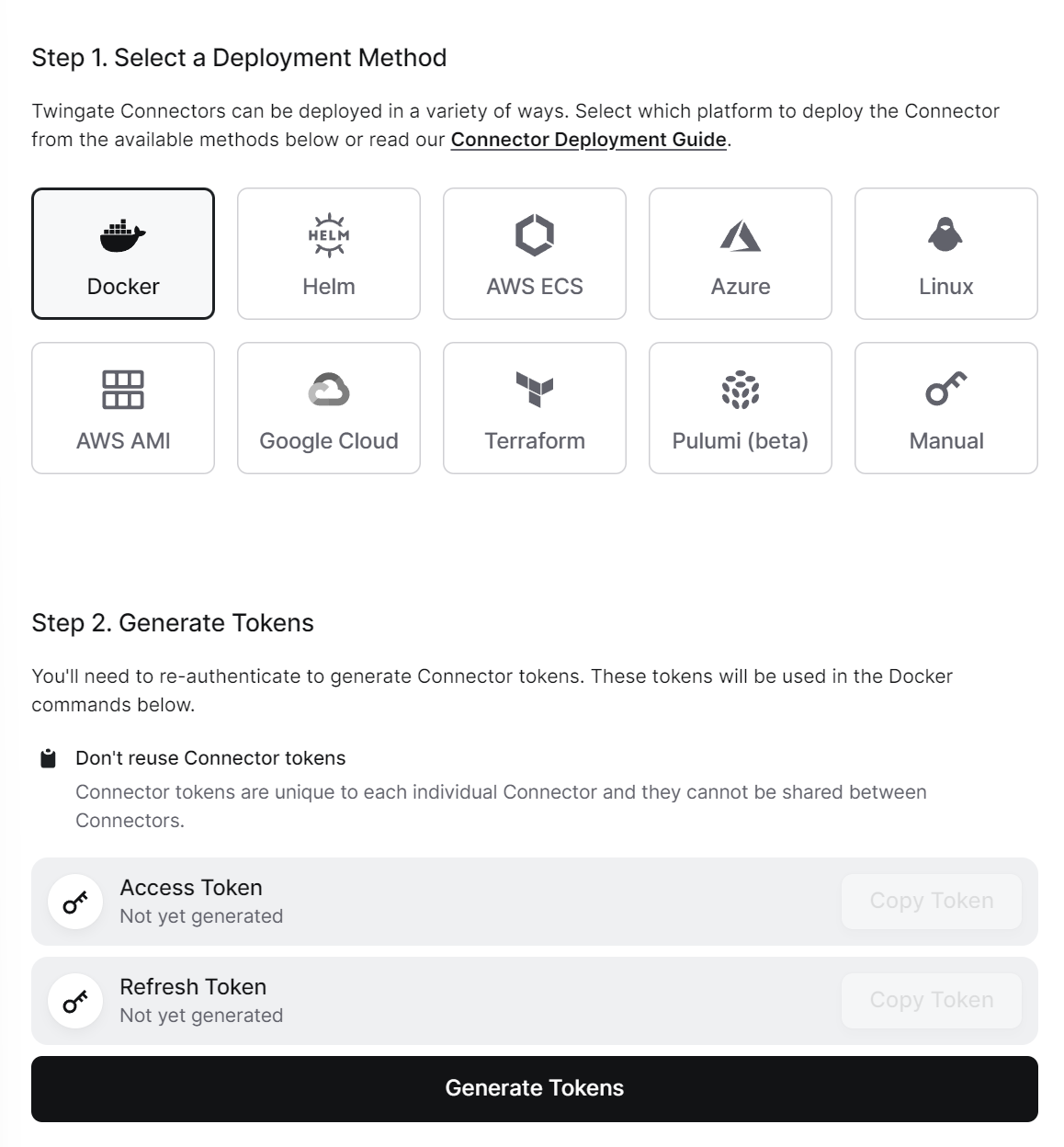
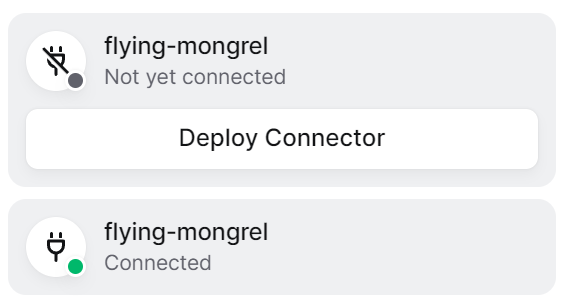
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24830088/Thred_top.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24825634/CleanShot_2023_08_02_at_10.57.20.png)